






分类模型评估
参数来源或者背景
分类模型中二分类模型的预测,有时是以概率值体现,以逻辑回归为例,每一个预测分类都对应一个概率值。对预测的概率从小到大排序,总得有一个阈值将这个序列截断,大于这个阈值则预测为正例,反之为反例。可以设想,我们在移动这个截断点(阈值),我们希望这个模型能够很好地分类,即截断点右侧的正例尽可能多,反例尽可能少。每次移动都可以计算一些指标:TP(真正例)、TN(真反例)、FP(假正例)、FN(假反例)、P(precision精确率)、R(recall召回率)、TPR(真正例率)、FPR(假正例率)
混淆矩阵
有一群人,里面有好人(这里当作正例)也有坏人,一个外地人根据这群人的特征(衣着、谈吐、年龄等等)来认人,分辨好人坏人
- TP(真正例):他认为是好人,实际真是好人的这些人群:被识别出来的好人
- TN(真反例):他认为是坏人,实际也是坏人:被识别出来的坏人
- FP(假正例):被识别为好人的坏人
- FN(假反例):被识别为坏人的好人
- TP+FN : 被识别出来的好人 + 被识别为坏人的好人 = 实际好人数量
- TN+FP : 被识别出来的坏人 + 被识别为好人的坏人 = 实际坏人的数量
- TP + FP : 被识别出来的好人 + 被识别为好人的坏人 = 识别为好人的数量
- FP + FN : 被识别为好人的坏人 + 被识别为坏人的好人 = 被错误识别的人的数量
精确率precision(查准率)
被识别出来的真好人占 识别为好人的数量 的比例:识别好人的精度
如果想提高精确度,就要降低分母(识别为好人的数量),必然会降低。。
P
=
T
P
T
P
+
F
P
↓
P=\frac{TP}{TP+FP\downarrow}
P=TP+FP↓TP
召回率 recall(查全率)
被识别出的好人 占 实际为好人的数量的比例:识别的好人是否全面
R
=
T
P
T
P
+
F
N
R=\frac{TP}{TP+FN}
R=TP+FNTP
P-R曲线与F1( 调和平均数)
在上述的截断点移动过程中,可以在横坐标为R(召回率)纵坐标为 P(精确率)的曲线;
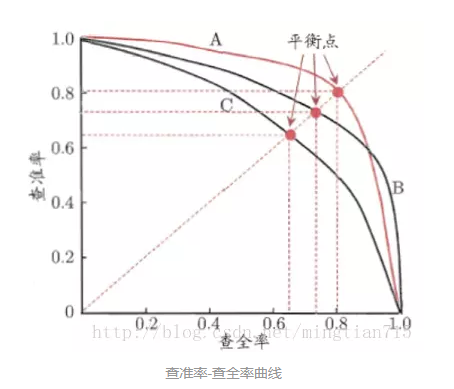
两个模型A和B比较优劣时通过P-R曲线:A的P-R曲线如果能包裹B的,则A的分类性能更好:在相同的召回率,A有更高的精确率,在相同的精确率,A有更高的召回率。
但是存在交叉的情况,这样产生了新的指标来评估优劣:F1: P(精确度)和R(召回率)的调和平均数
1
F
1
=
1
2
×
(
1
P
+
1
R
)
\frac{1}{F1}=\frac{1}{2}\times(\frac{1}{P}+\frac{1}{R})
F11=21×(P1+R1)
调和平均数F1更重视P和P较小的值
F
1
=
2
×
P
×
R
P
+
R
F1=\frac{2\times P \times R}{P+R}
F1=P+R2×P×R
ROC与AUC
两个指标:
-
真正例率(预测为正例的数量占实际正例数量的比例)
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP -
假正例率(假阳率)(错误预测为正例,实际为反例的数量占实际反例数量的比例)。
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
在截断点从右向左移动的过程中,产生一个个TPR和FPR(从原点开始左下朝右上),分别作为y轴和x轴,最后可以形成一个ROC曲线。
同一份数据集,训练了两个分类模型A和B,哪个更好呢?如果A 的ROC 能包住B的,则A模型的分类能力更好,因为:在任意一个截断点,A模型都有更高的真正例率,和更低的假正例率。
在实际操作中,是通过比较ROC 曲线下面的面积即AUC实现的。
注意:ROC是从关注正例的角度出发设计出来的一个指标,如果从关注负例的角度出发,即关注截断点左侧,真负例率和假正例率有相同的曲线。如果错误预测的代价是均等的(假正例和假负例的代价一样),AUC曲线左侧的面积可以认为是假正例率的积分,再加上假负利率的积分,可以用来评估模型的总体代价
回归模型评估
-
MSE
-
RMSE
-
决定系数
R 2 = 1 − S S r e s S S t o t R^2=1-\frac{SS_{res}}{SS_{tot}} R2=1−SStotSSres- SSres 是残差平方和(Sum of Squares of Residuals),即实际观测值与模型预测值之差的平方和。
- SStotSStot 是总平方和(Total Sum of Squares),即实际观测值与其平均值之差的平方和。
如何解释:
- R平方 = 0:表示模型根本不比预测平均值更好。
- R平方 = 1:表示模型完美地预测了目标变量。
- R平方接近1:表示模型能够很好地解释目标变量的方差。
注意事项:
- 过高的R平方:一个非常高的R平方并不总是意味着模型就是好的。特别是在过拟合的情况下,模型可能在训练数据上表现出高R平方,但在新数据上表现不佳。
- 复杂模型的R平方:更复杂的模型(如有更多自变量的模型)可能会有一个较高的R平方值,即使新增的变量实际上并不重要。
- 使用场景:R平方更适用于线性回归模型。对于非线性回归模型,R平方的解释可能不那么直观。















 7023
7023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









