







——Word Embedding字嵌入,是维度下降的一个很好的应用。
提到文字编码,首先是一种最最死板的编码方式1-of-N Encoding,就是把每个词汇当一个向量,这个向量的维度是所有词汇的数量,然后每个词只有一个位置是1,一一对应,比如apple就是第一位是1,以此类推。但是这样不仅很繁杂,也不能体会词与词之间的关联性,所以希望能像下面word class一样能把相同属性的词汇放到一个类里面。但即使是word class,也体现不了类与类之间的关系,比如class1和class3都是生物。所以有了word embedding字嵌入,他把每个词都投影到二维平面上,不仅分了类,还体现了类与类之间的关系,比如从横轴可以分开动词和生物词汇,从纵轴可以分开能动的和不能动的。
字嵌入的实现方式其实就是让机器学习大量的文章,它是一个无监督的学习过程,输入就是很多文章和词汇,但是输出的这个词汇的类/属性,是不知道的。或者说一个单词本身是什么意思不重要,重要的是几个词之间的关系,是否为同类型词汇的一个判断。比如这里举的例子,人名后面都出现了同样的字眼,所以就算机器不知道人名的含义和差别,但是知道它们是一类的。



下面讲具体如何实现上述思想的方法
1.count based基于计数的,比如有wi和wj两个单词,V(wi)是这个单词的向量表示形式,那么这两个越是经常一起出现co-occur,这两个单词的向量V越相似。这里有一个叫glove vector的方法就是这样做的。通过比较这两个向量的乘积与Ni,j的相似度,N是这两个单词出现在同一篇文章的次数。
2.prediction based基于预测的,要做的事情是给定一个wi-1,预测出它之后的单词wi,所以这个神经网络的输入就是描述wi-1的向量,输出是各个单词作为wi的可能性。也是一个N维向量,哪个词有可能出现,它对应的位置就是大的可能性。如果此时把第一个隐藏层的结果拿出来放到平面上,展现的其实就是上面说的分类的效果,会先根据前一个词确定后一个词的大致类别(?我瞎扯的)。
当然只从一个词就能判断下一个词,连人类都在做不到,当然是多前词才能大致判断下一个词,所以需要考虑wi-1乃至wi-2,下面就是考虑多个词时的网络结构。这里的规则时wi-1和wi-2需要严格一一对应z,这样可以确保次序性,并且可以共享W,减少参数量。这样的话通过下面的公式可以发现,只需要在输入前把所有的单词先加在一起再乘以W即可,减小了计算量。
这种拿前两个词汇来预测的方法还有很多,比如拿wi左右的词汇wi-1和wi+1来预测wi的,或者是用wi来预测左右的。
而且很明显这个网络不是深度网络,是因为本身不需要深度,并且一层的网络可以减少计算量,从而一次训练很多数据。



下面是应用,一个是中英文的词汇,字嵌入做不到直接翻译,因为中文和英文没有任何关系,但是如下图,它可以做到确定类,所以如果来一个新词,它可以大概知道对应的译词会落在哪个类,从而达到类似翻译的效果。
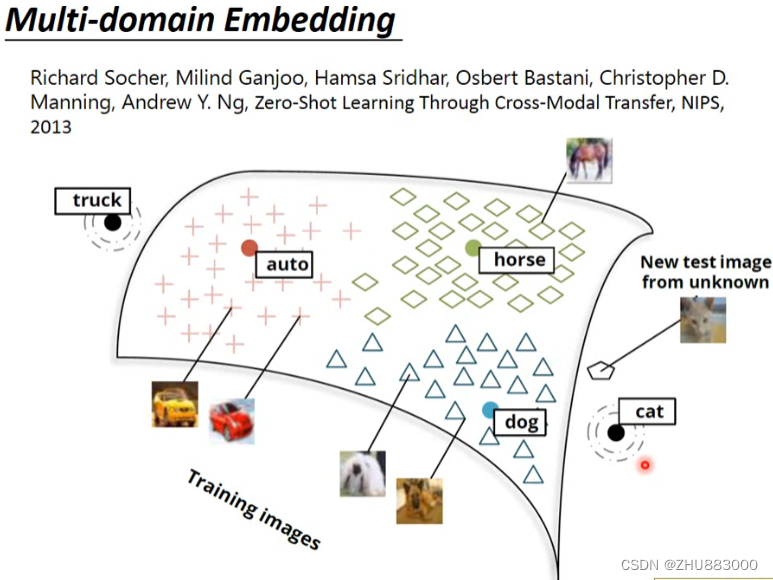
图像辨识上面也是,虽然不是直接把图像的类别判断出来,但是可以把之前的图像和类别分类之后,遇到没见过的图像就可以大致判断出它是哪一类的。















 2075
2075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









