






前言
本文章记录了本人在深度学习课程大作业过程中,整个环境的配置过程步骤。
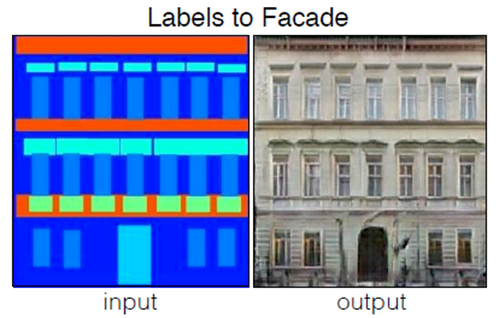
我的项目名称是《基于Pix2pix的建筑标签图像翻译》:
基于深度学习框架Keras,实现Pix2pix图像生成对抗网络,以实现通过建筑语义标签图(以及带建筑的街道语义标签图)生成对应的“真实”建筑图像。
实验环境
- Windows10
- Anaconda3-2020.02-Windows-x86_64
- Pycharm 2019.2.4
- Python 3.6.5
- Tensorflow-gpu 1.12.0
- Keras 2.2.4
- Tensorboard 1.12.2
- Pydot-ng 2.0.0 + pydotplus 2.0.2
环境搭建步骤
一、下载Anaconda并安装
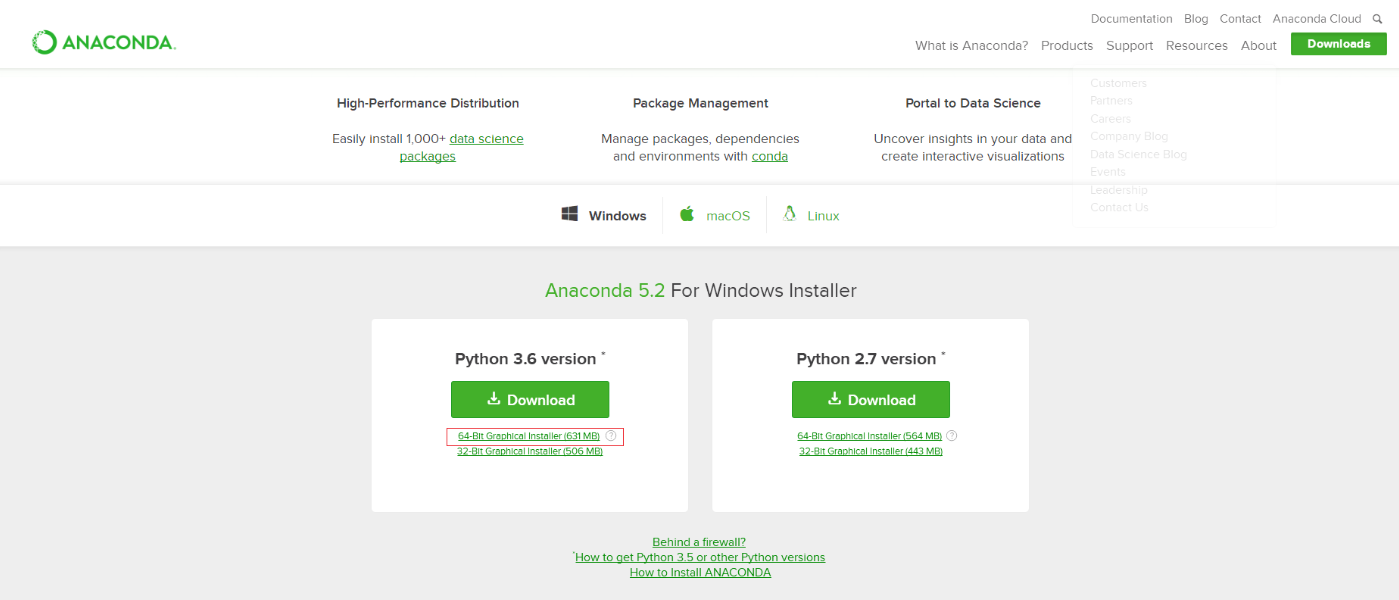
- 在浏览器中输入 https://www.anaconda.com/distribution/ ,需要选择Windows环境下的Python3.7版本,点击图中适合自己的版本,进行下载。
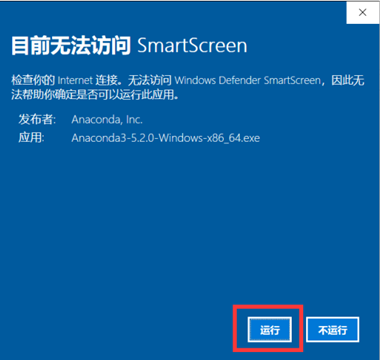
- 下载好软件后,双击安装软件
①注意软件名称及版本 ②如出现windows10自带提示,均选择坚持运行(Run)
②如出现windows10自带提示,均选择坚持运行(Run)
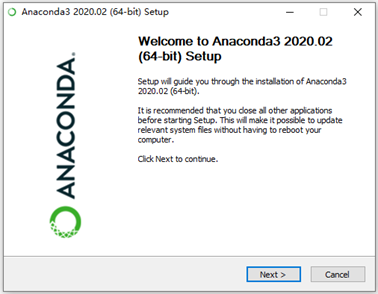
 ③一步一步进行安装
③一步一步进行安装
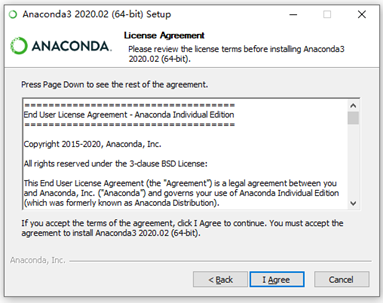
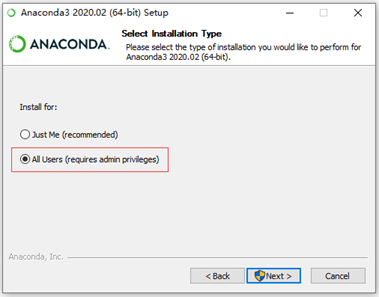
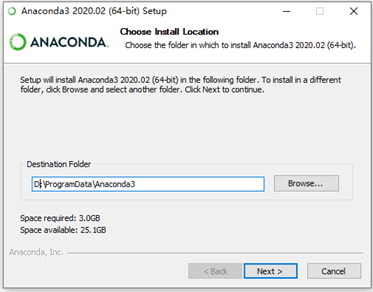 ④注意一定要勾选这两个选项(注意:在选择安装文件夹时,所安装的完
④注意一定要勾选这两个选项(注意:在选择安装文件夹时,所安装的完
整路径中都不能有文件夹名称有空格或包含中文字符)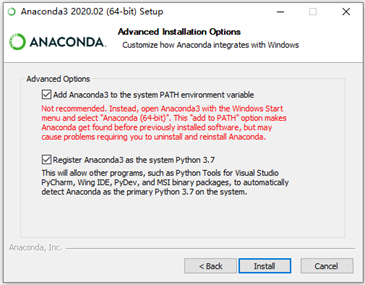 点击install即可安装
点击install即可安装
- 配置环境变量
将自己的Python环境变量添加到path下: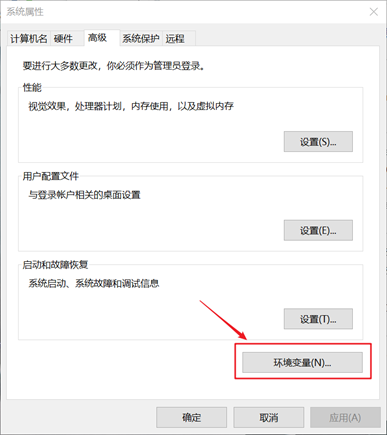

- 测试Python的安装情况
同时按下电脑 Windows+R 键打开运行窗口,输入 cmd,点击确定。在命令行中键入Python,然后回车,会出现如图的显示:
- 安装完毕后,可以在开始菜单中看到如下图标
二、下载Pycharm并安装
- 访问官网 https://www.jetbrains.com/pycharm/download/ ,点击图中适合自己的版本,进行下载。下载完成后,选择安装包进行安装:
- 选择安装目录:
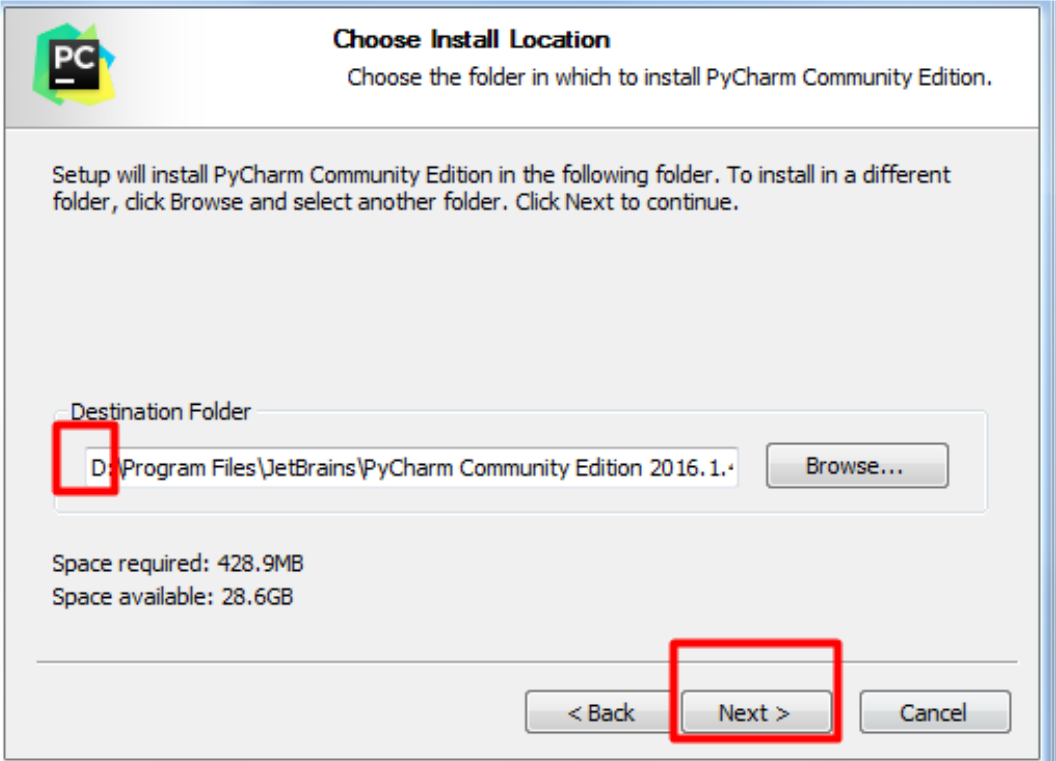
- 一路确定,完成安装:
- 激活Pycharm:
登录官网申请学生账户(使用学校的学生邮箱申请):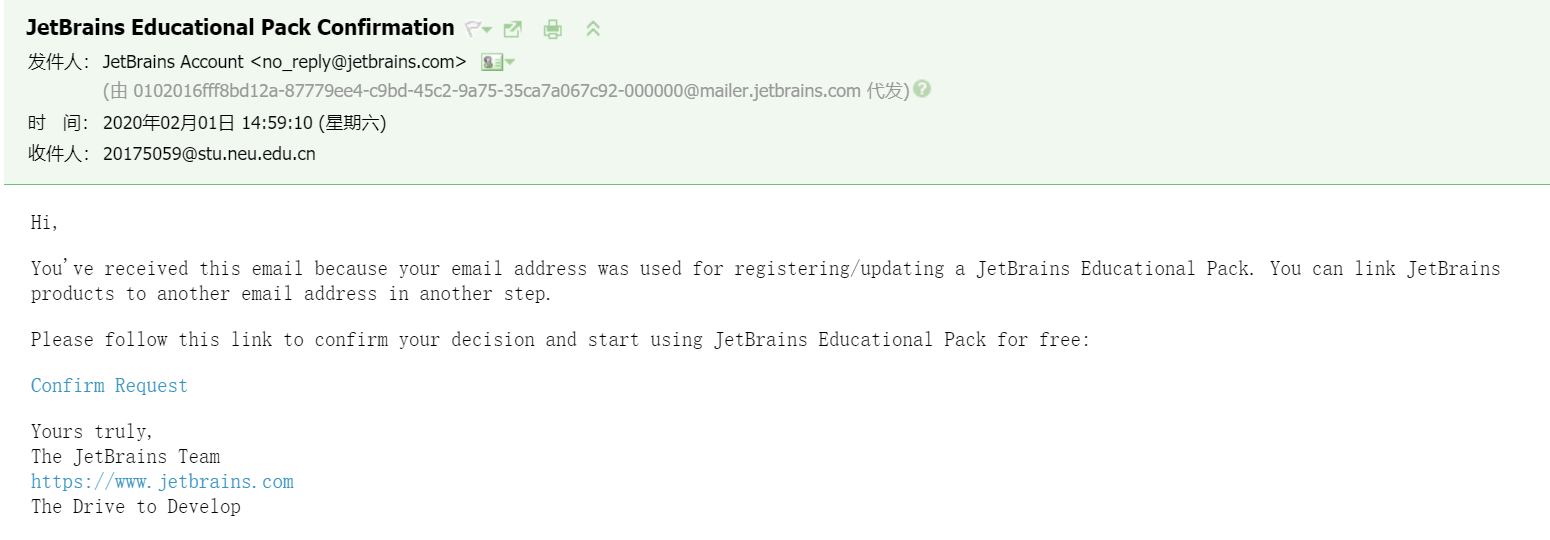 账户申请成功并通过验证之后,打开pycharm,在help -> register中输入用户名密码:
账户申请成功并通过验证之后,打开pycharm,在help -> register中输入用户名密码:
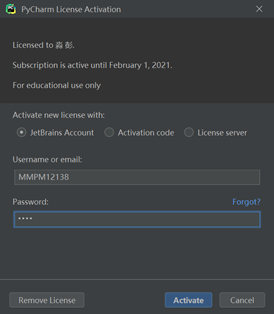 最终激活成功如下:
最终激活成功如下:

三、在Pycharm中配置Anaconda环境
- 进入PyCharm,依次点击File-> Setting->Project Interpreter:
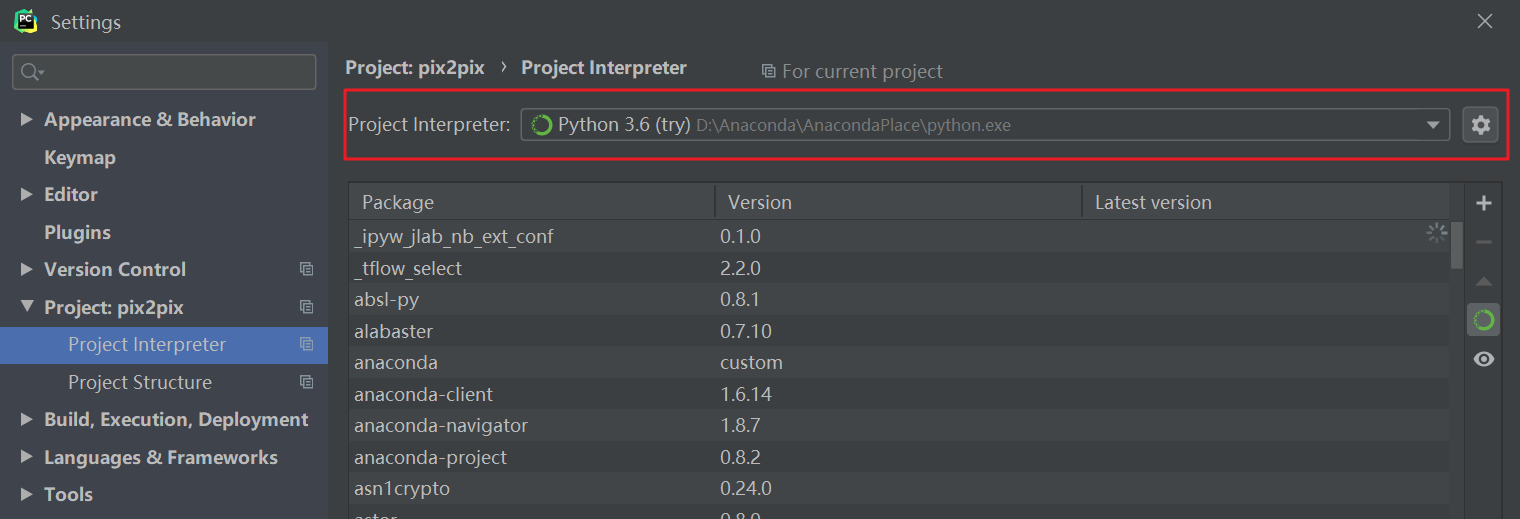
- 点击齿轮选择Add Local,点击第三个选项卡,将路径选为anaconda安装路径下的python.exe,确定后成功配置anaconda环境:
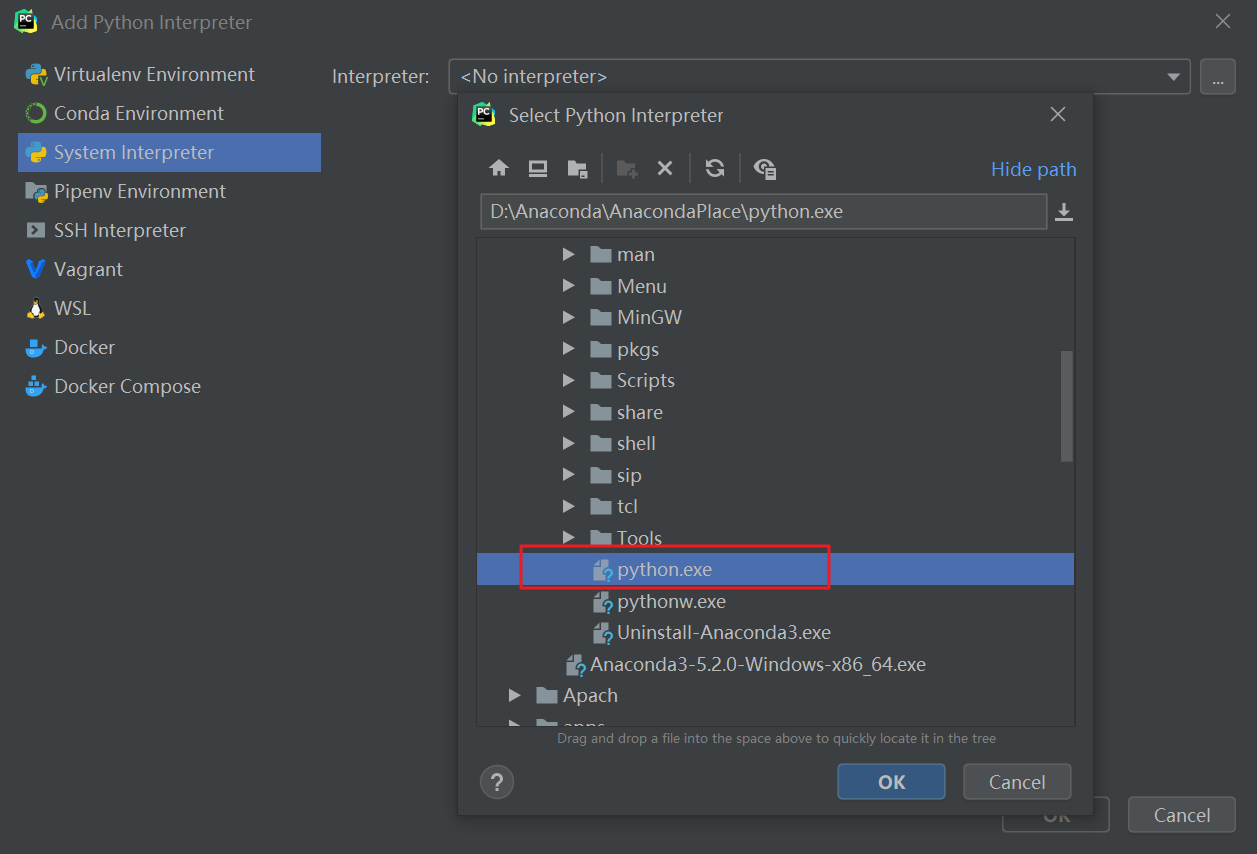
- 之后,在该环境下创建的工程就可以使用anaconda中已有的库了。
四、安装GPU的Tensorflow和Keras
因为在图像处理的神经网络上gpu和cpu速度差别很大。因此,安装gpu版本的tensorflow和keras。tensorflow-gpu是tensorflow的gpu版本,它必须通过 cuda 和 cudnn 来调用电脑的 gpu。
- 确认自身电脑的显卡所对应支持的 CUDA:
我的电脑上的显卡GPU为NVIDA GeForce GTX 1050https://developer.nvidia.com/cuda-gpus网站确认该型号是否支持CUDA: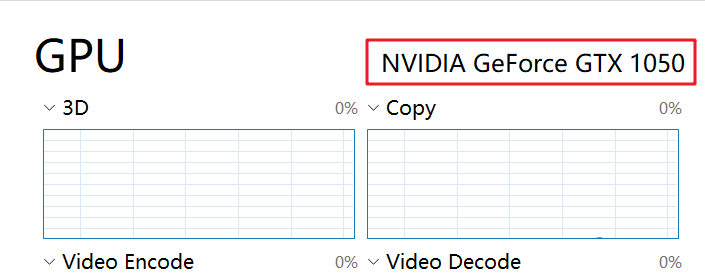 到
到
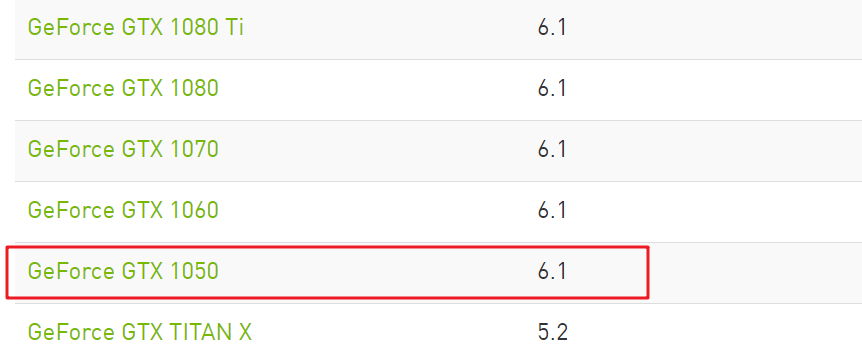 可以看到我的显卡型号是支持的。
可以看到我的显卡型号是支持的。
- 到NVIDA官方网站https://developer.nvidia.com/cuda-90-download-archive?tdsourcetag=s_pctim_aiomsg 下载安装 CUDA Toolkit 9.0
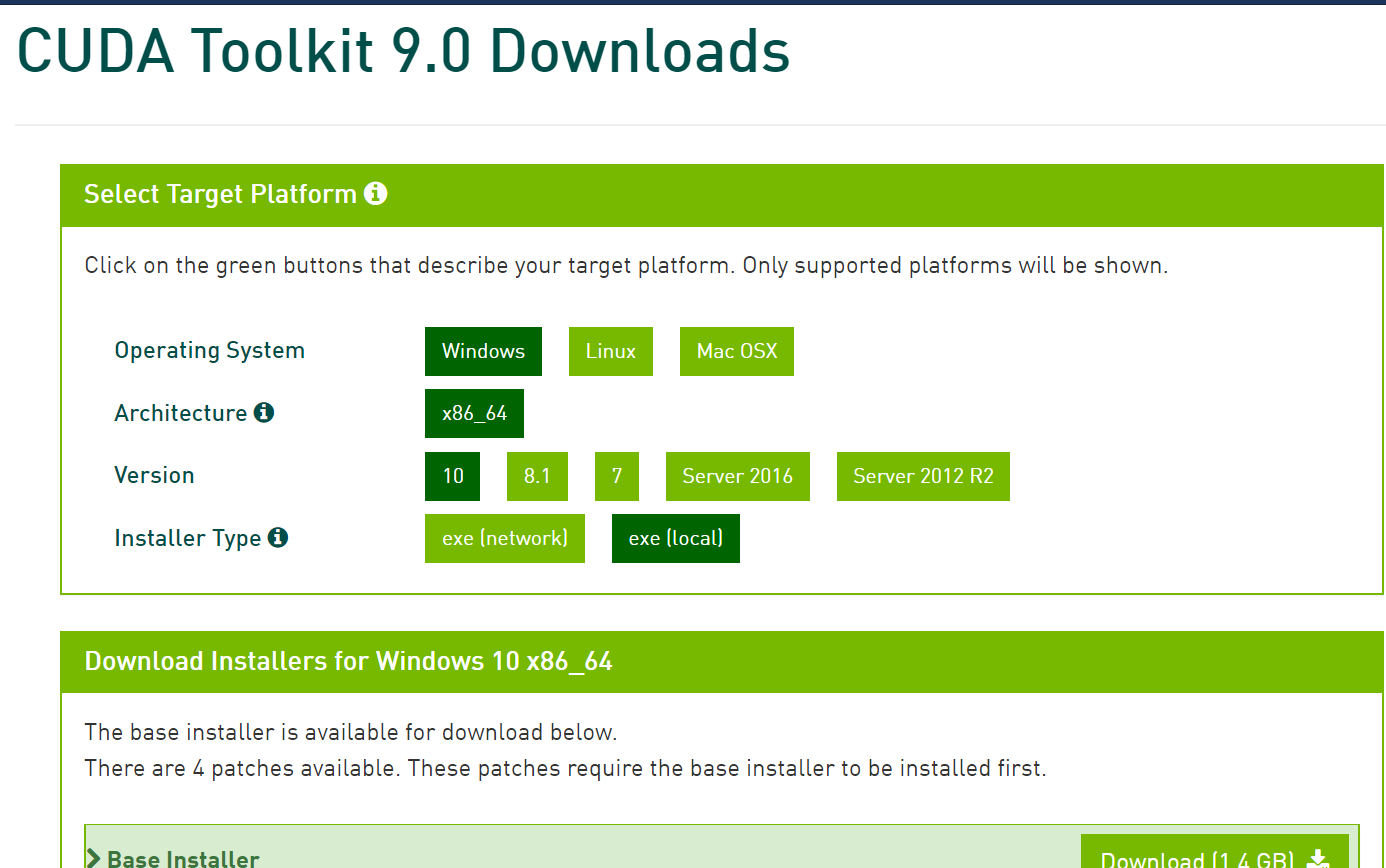 打开下载好的安装包,一路确定进行安装:
打开下载好的安装包,一路确定进行安装:
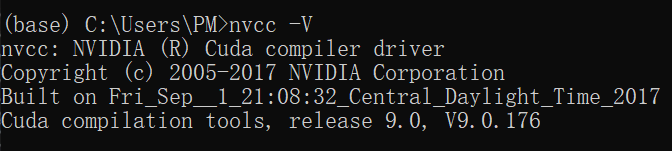
 安装成功之后,输入以下命令检查:
安装成功之后,输入以下命令检查:
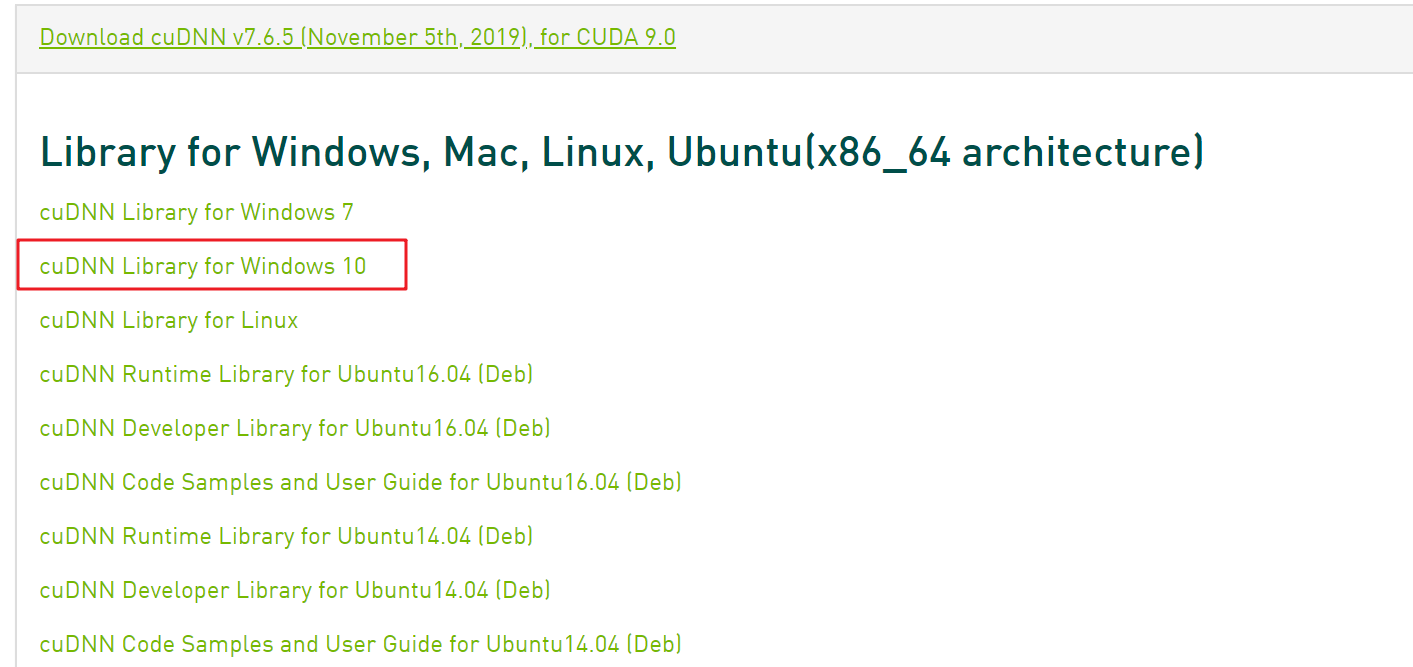
- 到https://developer.nvidia.com/cudnn 下载 cuDNN v7.6.5,并解压到目录,把对应的目录地址添加到path环境变量
 下载cuDNN,需要先注册一个NVIDA的账号。点击Join now,注册账号,在邮箱中完成验证。
https://www.tensorflow.org/install/source_windows 查找CUDA对应版本的cuDNN:
下载cuDNN,需要先注册一个NVIDA的账号。点击Join now,注册账号,在邮箱中完成验证。
https://www.tensorflow.org/install/source_windows 查找CUDA对应版本的cuDNN: 然后再到
然后再到
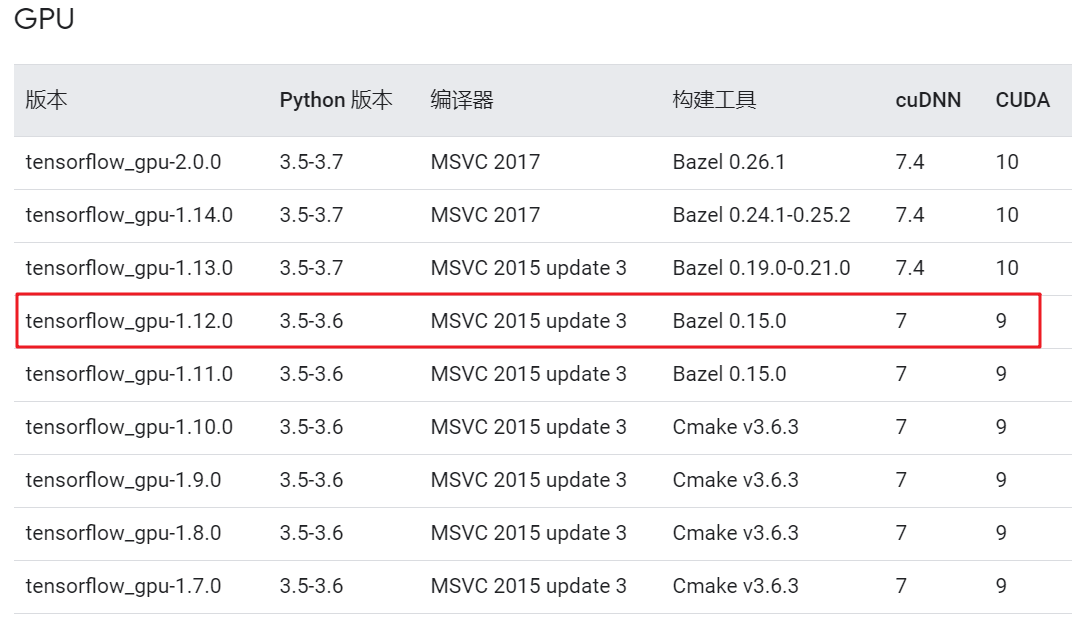 由于我的python版本是3.6.5,并且CUDA版本是9.0,因此综合考虑我选择安装红框的组合版本,即安装7.x.x版本的cuDNN。
由于我的python版本是3.6.5,并且CUDA版本是9.0,因此综合考虑我选择安装红框的组合版本,即安装7.x.x版本的cuDNN。
登录账号,下载cuDNN的安装包。
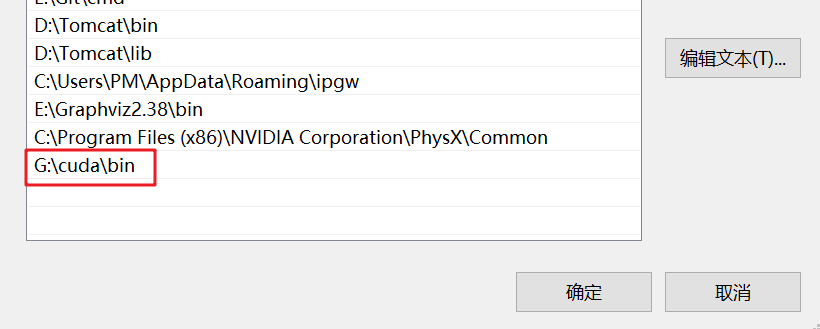
 解压安装后,将安装地址添加到环境变量:
解压安装后,将安装地址添加到环境变量:
- 安装对应的 tensorflow GPU版本和keras版本:
确定对应CUDA和cuDNN版本的GPU版的tensorflow: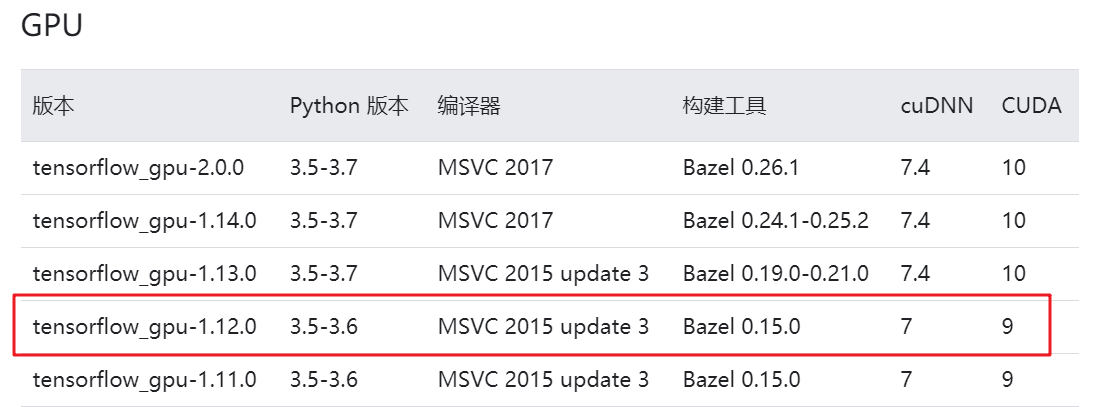 安装1.12.0版本的tensorflow-gpu:
安装1.12.0版本的tensorflow-gpu:
pip install tensorflow_gpu==1.12.0 确定对应tensorflow-gpu版本的Keras版本:
确定对应tensorflow-gpu版本的Keras版本:
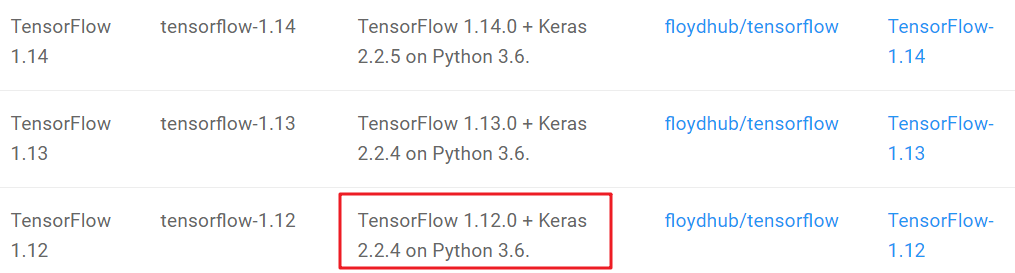 安装2.2.4版本的Keras:
安装2.2.4版本的Keras:
pip install keras==2.2.4
- 安装完成后,使用命令查看所有设备:
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())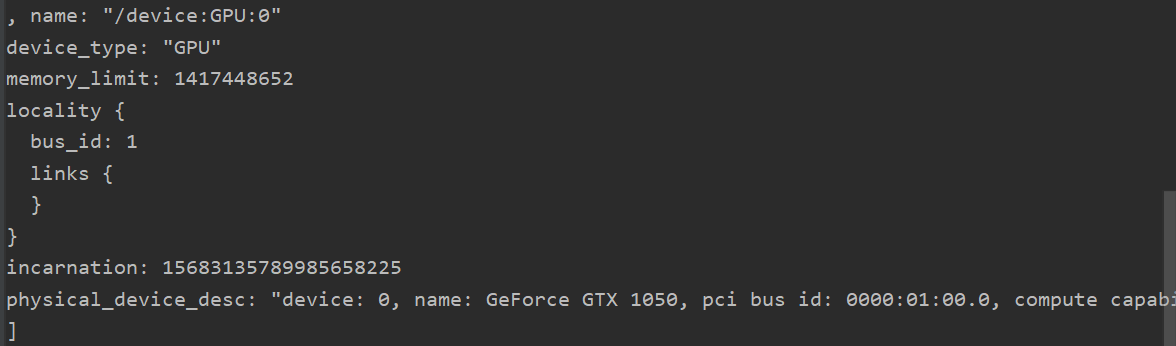
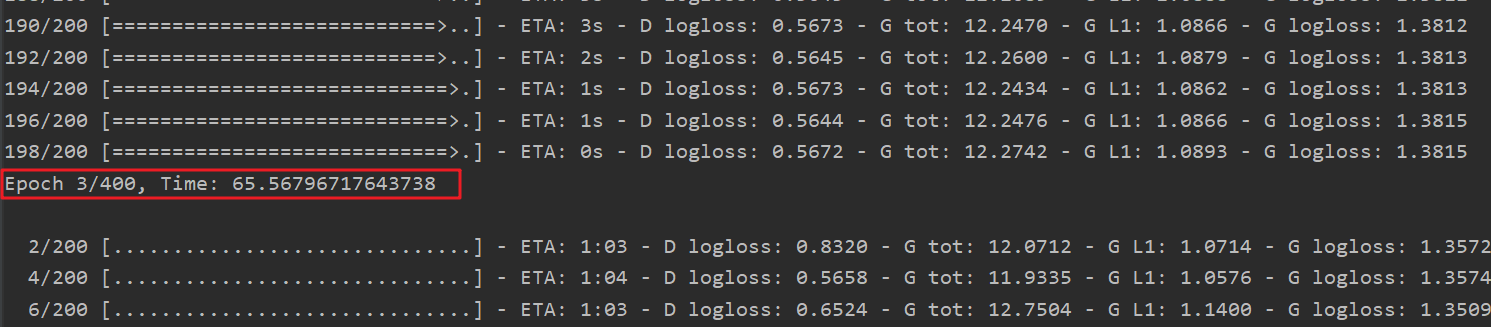
- 使用GPU进行训练可以看到每一个epoch的训练速度快了很多:
五、安装Tensorboard
TensorBoard是TensorFlow下的一个可视化的工具,能在训练大规模神经网络时将复杂的运算过程可视化。TensorBoard能展示你训练过程中绘制的图像、网络结构等。
考虑到实验训练过程中,我使用的是以Tensorflow为后端的Keras,因此按照道理也可以使用Tensorboard来实现。
- 使用pip安装1.12.2版本的tensorboard:
输入pip install tensorboard==1.12.2命令以安装
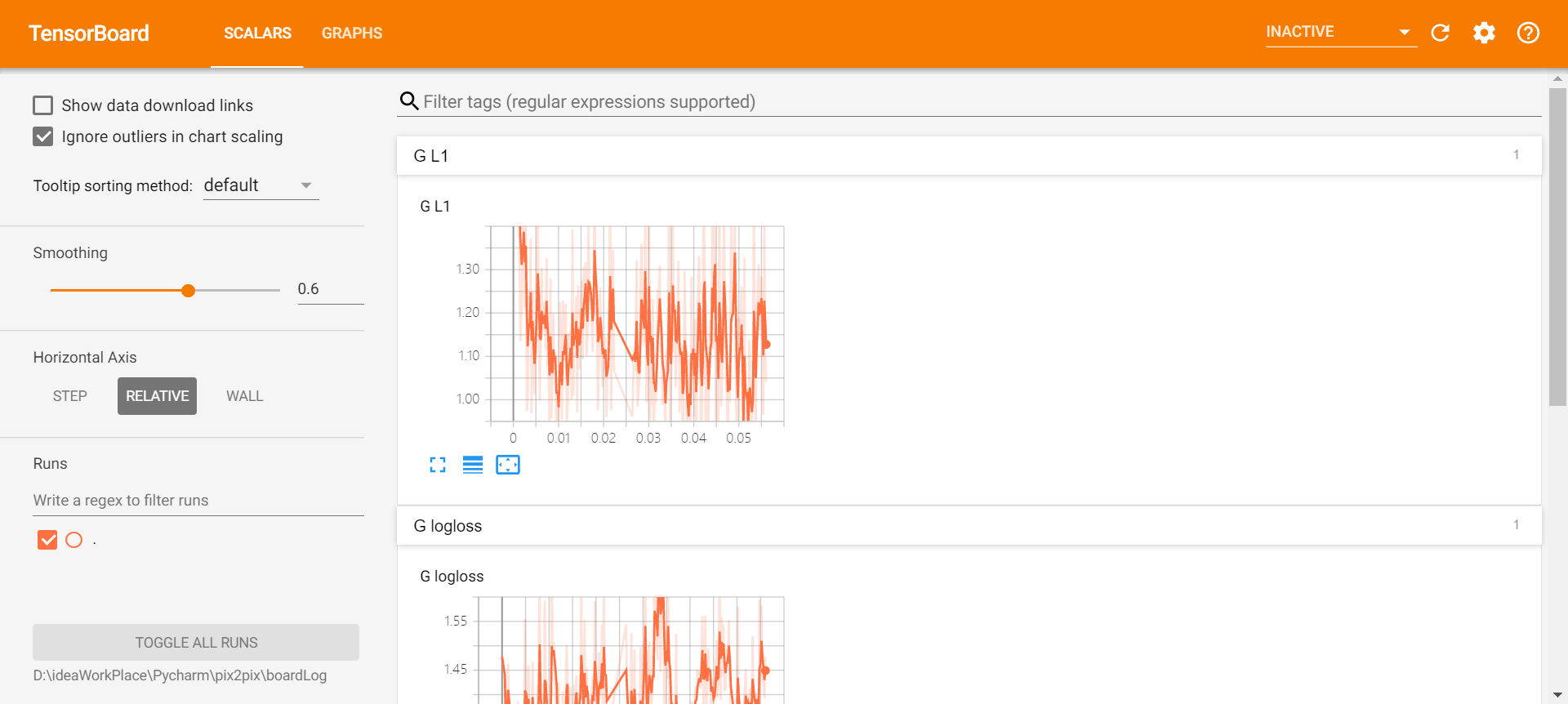
- 启动tensorboard:
执行tensorboard --logdir=D:\ideaWorkPlace\Pycharm\pix2pix\boardLog,再访问localhost:6006。
- 如果启动报错
ImportError: cannot import name '_message' from 'google.protobuf.pyext',如下所示: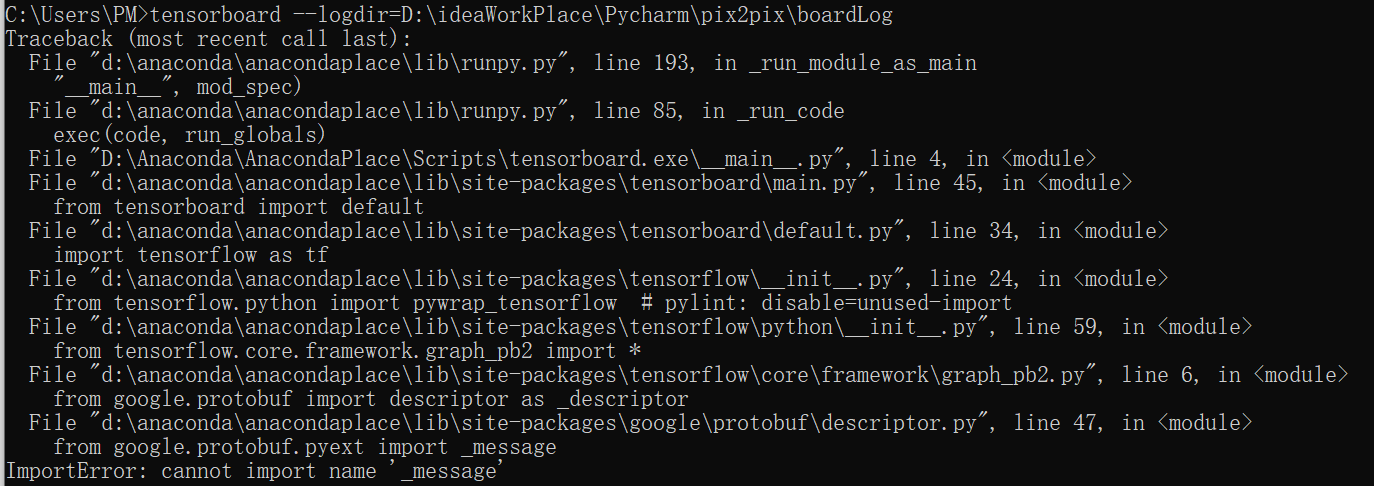 原因在于protobuf安装的是较新版本3.10.1, 出现了不兼容的问题。把protobuf进行降级,从3.10.1降级到3.6.1,再重新启动即可。
原因在于protobuf安装的是较新版本3.10.1, 出现了不兼容的问题。把protobuf进行降级,从3.10.1降级到3.6.1,再重新启动即可。
六、安装pydot和graphviz——keras可视化
Keras支持将模型的结构图进行输出,从而实现整个模型以及各层结构的可视化。
运行项目中keras.utils的plot_model功能,需要安装官网上说的两个依赖包:pydot和graphviz。
pip install pydot-ng
pip install graphviz
pip install pydotplus 注意这里,之前我安装的是pydot,但会出现如下的错误:
原因是python3.5和3.6以上版本不再支持Graphviz,因此需要卸载pydot,安装pydotplus。
注意这里,之前我安装的是pydot,但会出现如下的错误:
原因是python3.5和3.6以上版本不再支持Graphviz,因此需要卸载pydot,安装pydotplus。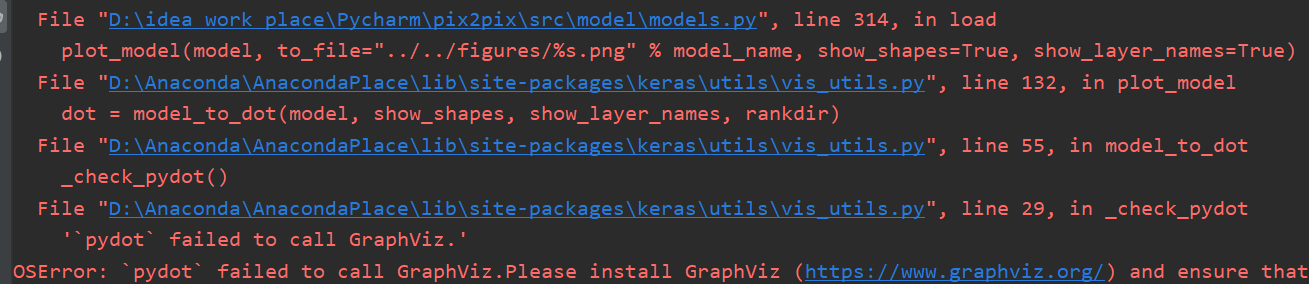
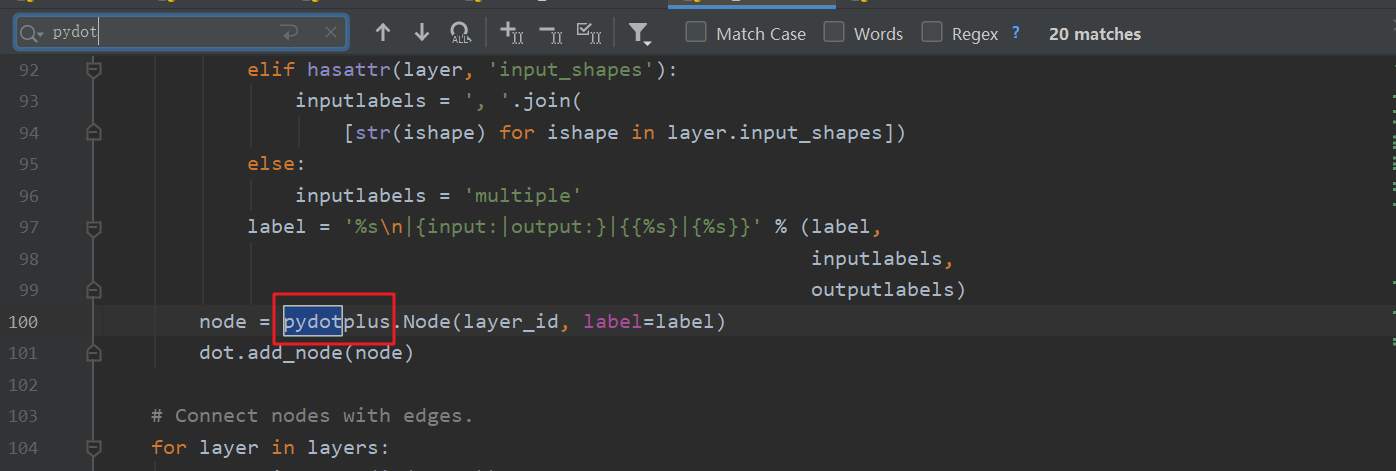
- 找到keras里面的utils\vis_utils.py,把里面的pydot的都替换成pydotplus
- 安装Graphviz软件
到官网下载graphviz的安装包(可选择msi格式): 安装.msi安装包,并一直next确认:
安装.msi安装包,并一直next确认:
 将安装的客户端配置一下环境变量:
将安装的客户端配置一下环境变量:
 测试Graphviz是否安装成功:在cmd中输入
测试Graphviz是否安装成功:在cmd中输入
dot -version并回车,若显示出graphviz的相关版本信息,则安装配置成功。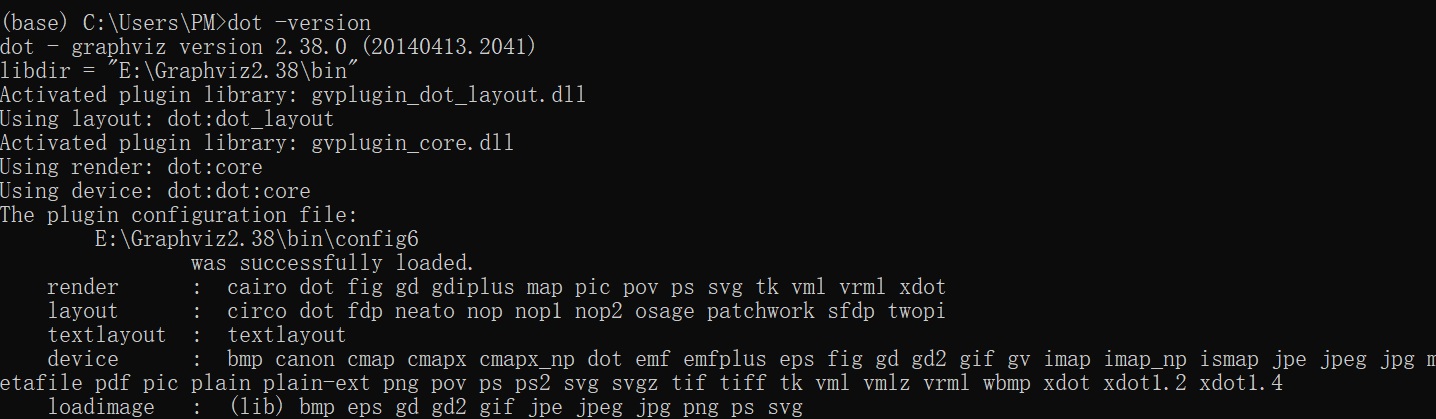
- 通过models.py文件中的如下代码进行测试:
# 加载U-Net generator(decoder由upsampling上采样实现)
if model_name == "generator_unet_upsampling":
model = generator_unet_upsampling(img_dim, bn_mode, model_name=model_name)
model.summary()
if do_plot: # 用plot_model函数将模型的形状保存为图片
from keras.utils import plot_model
plot_model(model, to_file="../../figures/%s.png" % model_name, show_shapes=True, show_layer_names=True)
return model















 1747
1747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









