







前言
在前面 Yarn的基本架构和作业提交全流程 一文中提到,当ResourceManager收到客户端Client的请求之后会将该作业job添加到(默认的)容量调度器中,然后再由某一个空闲的NodeManager领取该job并具体提供运算资源。那么,Yarn框架为什么要设计把作业添加到调度器中呢?
假设你现在所在的公司有一个hadoop的集群。但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求。那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这两个任务呢?是先执行A的任务,再执行B的任务,还是同时跑两个?
所以,在Yarn框架中正因为有调度器,有合适的调度规则,就可以保证多个应用在同一时间有条不紊的工作。其实在Yarn中最原始的调度规则是FIFO(先进先出),即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能导致一个大任务独占资源,其他的资源需要不断的等待。当然,也可能是一堆小任务占用资源,而大任务一直无法得到适当的资源,于是造成饥饿。所以,FIFO虽然很简单,但是并不能满足实际业务中的需求。
事实上,Yarn中支持的调度器有三种,分别是FIFO Scheduler 、Capacity Scheduler和Fair Scheduler,具体查看调度器的方式如下:
1)web界面:http://host:8088/cluster
2)命令行:yarn queue -status 队列名

三种调度器的区别
1、FIFO Scheduler
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。从下图可以看出在FIFO 调度器中,小任务会被大任务阻塞:

2、Capacity Scheduler
对于Capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。具体设置详见:yarn-default.xml文件
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
如下图所示:

3、Fair Scheduler
在Fair调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如下图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。

下面重点介绍一下工作中经常用到的容量调度器以及相关配置:
1、什么是capacity调度器
Capacity Schedule调度器以队列为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的,如下图:

default队列占30%资源,analyst和dev分别占40%和30%资源;类似的,analyst和dev各有两个子队列,子队列在父队列的基础上再分配资源。
队列以分层方式组织资源,设计了多层级别的资源限制条件以更好的让多用户共享一个Hadoop集群,比如队列资源限制、用户资源限制、用户应用程序数目限制。队列里的应用以FIFO方式调度,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可以设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
2、Capacity调度器的几个特性
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
- 安全,每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同时保证每个队列分配到自己的容量,提高利用率。
- 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了。
在Capacity调度器的每一个队列内部,资源的调度是采用的先进先出(FIFO)策略。
通过上面的图我们已经知道一个job可能使用不了整个队列的资源。然而如果这个队列中运行多个job,如果这个队列的资源够用,那么就分配给这些job,如果这个队列的资源不够用了呢?
其实,Capacity调度器仍可能分配额外的资源给这个队列,这就是“弹性队列”(queue elasticity)的概念。
在正常的操作中,Capacity调度器不会强制释放Container,当一个队列资源不够用时,这个队列只能获得其它队列释放后的Container资源。当然,我们可以为队列设置一个最大资源使用量,以免这个队列过多的占用空闲资源,导致其它队列无法使用这些空闲资源,这就是”弹性队列”需要权衡的地方。
Capacity调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。比如我大体上把整个集群分成了AB两个队列,A队列给A项目组的人来使用。B队列给B项目组来使用。但是A项目组下面又有两个方向,那么还可以继续分,比如专门做BI的和做实时分析的。那么队列的分配就可以参考下面的树形结构:
root
------a[60%]
|---a.bi[40%]
|---a.realtime[60%]
------b[40%]
a队列占用整个资源的60%,b队列占用整个资源的40%。a队列里面又分了两个子队列,一样也是2:3分配。
虽然有了这样的资源分配,但是并不是说a提交了任务,它就只能使用60%的资源,那40%就空闲着。只要资源实在空闲状态,那么a就可以使用100%的资源。但是一旦b提交了任务,a就需要在释放资源后,把资源还给b队列,直到ab平衡在3:2的比例。
粗粒度上资源是按照上面的方式进行,在每个队列的内部,还是按照FIFO的原则来分配资源的。
3、调度器相关配置
1)配置调度器
在ResourceManager中配置它要使用的调度器,hadoop资源分配的默认配置
在搭建完成后我们发现对于资源分配方面,yarn的默认配置是这样的,也就是有一个默认的队列。事实上,是否使用CapacityScheduler组件是可以配置的,但是默认配置就是这个CapacityScheduler,如果想显式配置需要修改 conf/yarn-site.xml 内容如下:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
可以看到默认是org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler这个调度器,那么这个调度器的名字是什么呢?
我们可以在/Users/lcc/soft/hadoop/hadoop-2.7.4/etc/hadoop/capacity-scheduler.xml文件中看到:
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
可以看到默认的队列名字为default(知道名字有什么用?我们可以根据nameNode地址,和调度器名称,获取机器相关的信息,比如内存,磁盘,cpu等资源用了多少,还剩下多少)
2)配置队列
调度器的核心就是队列的分配和使用了,修改conf/capacity-scheduler.xml可以配置队列。
Capacity调度器默认有一个预定义的队列——root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用.来进行分割,比如yarn.scheduler.capacity..queues.
下面是配置的样例,比如root下面有三个子队列:
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>a,b,c</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.a.queues</name>
<value>a1,a2</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.b.queues</name>
<value>b1,b2,b3</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
上面配置的结构类似于:
root
------a[队列名字]
|---a1[子队列名字]
|---a2[子队列名字]
------b[队列名字]
|---b1[子队列名字]
|---b2[子队列名字]
|---b3[子队列名字]
------c[队列名字]
3)相关属性解释
yarn.scheduler.capacity..capacity
它是队列的资源容量占比(百分比)。系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是100%。
yarn.scheduler.capacity..maximum-capacity
队列资源的使用上限。由于系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是-1,即禁用。
yarn.scheduler.capacity..minimum-user-limit-percent
每个任务占用的最少资源。比如,你设置成了25%。那么如果有两个用户提交任务,那么每个任务资源不超过50%。如果3个用户提交任务,那么每个任务资源不超过33%。如果4个用户提交任务,那么每个任务资源不超过25%。如果5个用户提交任务,那么第五个用户需要等待才能提交。默认是100,即不去做限制。
yarn.scheduler.capacity..user-limit-factor
每个用户最多使用的队列资源占比,如果设置为50.那么每个用户使用的资源最多就是50%。
yarn.scheduler.capacity.maximum-applications / yarn.scheduler.capacity..maximum-applications
设置系统中可以同时运行和等待的应用数量。默认是10000.
yarn.scheduler.capacity.maximum-am-resource-percent / yarn.scheduler.capacity..maximum-am-resource-percent
设置有多少资源可以用来运行app master,即控制当前激活状态的应用。默认是10%。
yarn.scheduler.capacity..state
队列的状态,可以使RUNNING或者STOPPED.如果队列是STOPPED状态,那么新应用不会提交到该队列或者子队列。同样,如果root被设置成STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭。
yarn.scheduler.capacity.root..acl_submit_applications
访问控制列表ACL控制谁可以向该队列提交任务。如果一个用户可以向该队列提交,那么也可以提交任务到它的子队列。
yarn.scheduler.capacity.root..acl_administer_queue
设置队列的管理员的ACL控制,管理员可以控制队列的所有应用程序。同样,它也具有继承性。
注意:ACL的设置是user1,user2 group1,group2这种格式。如果是*则代表任何人。空格表示任何人都不允许。默认是*.
yarn.scheduler.capacity.resource-calculator
资源计算方法,默认是org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator则会计算内存和CPU。
yarn.scheduler.capacity.node-locality-delay
调度器尝试进行调度的次数。一般都是跟集群的节点数量有关。默认40(一个机架上的节点数)
一旦设置完这些队列属性,就可以在web ui上看到了。可以访问链接:http://localhost:8088/ws/v1/cluster/scheduler
4)队列配置修改
如果想要修改队列或者调度器的配置,可以修改
vi $HADOOP_CONF_DIR/capacity-scheduler.xml
修改完成后,需要执行下面的命令:
$HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues
注意:
- 队列不能被删除,只能新增;
- 更新队列的配置需要是有效的值;
- 同层级的队列容量限制相加需要等于100%。
5)队列实例参考:

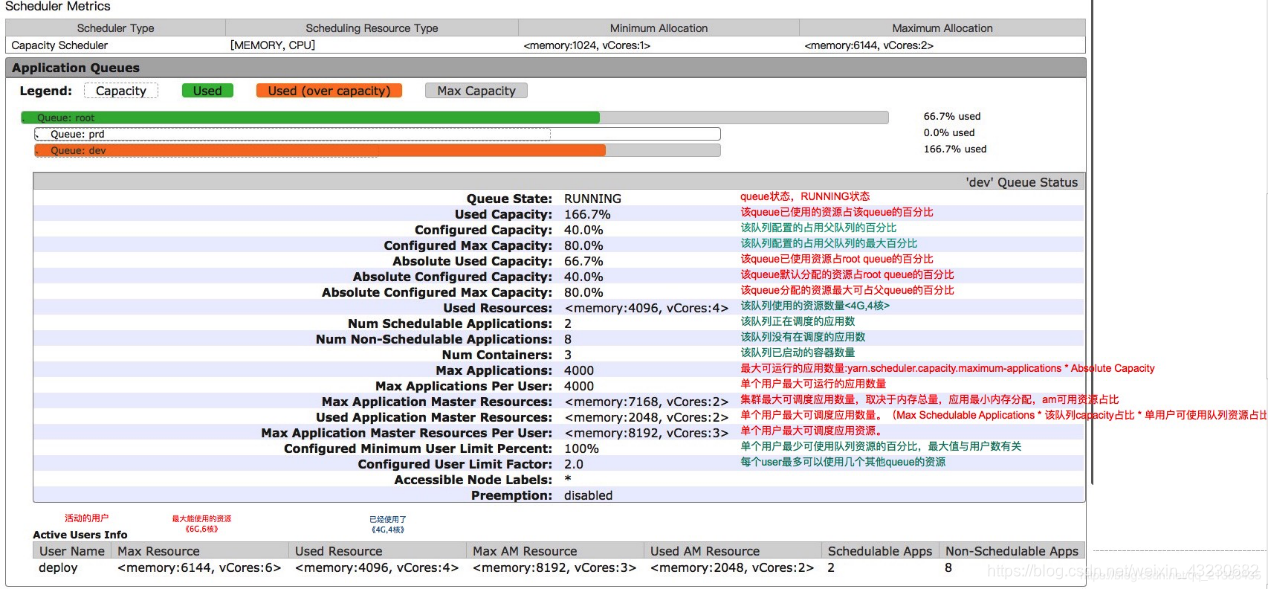
自定义队列,实现任务提交不同队列
前面我们看到了hadoop当中有各种资源调度形式,当前hadoop的任务提交,默认提交到default队列里面去了,将所有的任务都提交到default队列,我们在实际工作当中,可以通过划分队列的形式,对不同的用户,划分不同的资源,让不同的用户的任务,提交到不同的队列里面去,实现资源的隔离
资源隔离目前有2种,静态隔离和动态隔离。
所谓静态隔离是以服务隔离,是通过cgroups(LINUX control groups) 功能来支持的。比如HADOOP服务包含HDFS, HBASE, YARN等等,那么我们固定的设置比例,HDFS:20%, HBASE:40%, YARN:40%, 系统会帮我们根据整个集群的CPU,内存,IO数量来分割资源,先提一下,IO是无法分割的,所以只能说当遇到IO问题时根据比例由谁先拿到资源,CPU和内存是预先分配好的。
上面这种按照比例固定分割就是静态分割了,仔细想想,这种做法弊端太多,假设我按照一定的比例预先分割好了,但是如果我晚上主要跑mapreduce, 白天主要是HBASE工作,这种情况怎么办? 静态分割无法很好的支持,缺陷太大
动态隔离只要是针对 YARN以及impala, 所谓动态只是相对静态来说,其实也不是动态。 先说YARN, 在HADOOP整个环境,主要服务有哪些? mapreduce(这里再提一下,mapreduce是应用,YARN是框架,搞清楚这个概念),HBASE, HIVE,SPARK,HDFS,IMPALA, 实际上主要的大概这些,很多人估计会表示不赞同,oozie, ES, storm , kylin,flink等等这些和YARN离的太远了,不依赖YARN的资源服务,而且这些服务都是单独部署就OK,关联性不大。 所以主要和YARN有关也就是HIVE, SPARK,Mapreduce。这几个服务也正式目前用的最多的(HBASE用的也很多,但是和YARN没啥关系)。
根据上面的描述,大家应该能理解为什么所谓的动态隔离主要是针对YARN。好了,既然YARN占的比重这么多,那么如果能很好的对YARN进行资源隔离,那也是不错的。如果我有3个部分都需要使用HADOOP,那么我希望能根据不同部门设置资源的优先级别,实际上也是根据比例来设置,建立3个queue name, 开发部们30%,数据分析部分50%,运营部门20%。
设置了比例之后,再提交JOB的时候设置mapreduce.queue.name,那么JOB就会进入指定的队列里面。 非常可惜的是,如果你指定了一个不存在的队列,JOB仍然可以执行,这个是目前无解的,默认提交JOB到YARN的时候,规则是root.users.username , 队列不存在,会自动以这种格式生成队列名称。 队列设置好之后,再通过ACL来控制谁能提交或者KIll job。
从上面2种资源隔离来看,没有哪一种做的很好,如果非要选一种,我会选取后者,隔离YARN资源, 第一种固定分割服务的方式实在支持不了现在的业务
需求:
现在一个集群当中,可能有多个用户都需要使用,例如开发人员需要提交任务,测试人员需要提交任务,以及其他部门工作同事也需要提交任务到集群上面去,对于我们多个用户同时提交任务,我们可以通过配置yarn的多用户资源隔离来进行实现。
第一步:node01编辑yarn-site.xm
- node01修改yarn-site.xml添加以下配置
cd /xsluo/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim yarn-site.xml
- 内容如下
<!-- 指定我们的任务调度使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定我们的任务调度的配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/xsluo/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/fair-scheduler.xml</value>
</property>
<!-- 是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold 这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!-- 默认提交到default队列 -->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>default is True</description>
</property>
<!-- 如果提交一个任务没有到任何的队列,是否允许创建一个新的队列,设置false不允许 -->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>default is True</description>
</property>
第二步:node01添加fair-scheduler.xml配置文件
- node01执行以下命令,添加fair-scheduler.xml的配置文件
cd /xsluo/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
vim fair-scheduler.xml
- 内容如下
<?xml version="1.0"?>
<allocations>
<!-- 每个队列中,app的默认调度策略,默认值是fair -->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<user name="hadoop">
<!-- 用户hadoop最多运行的app个数 -->
<maxRunningApps>30</maxRunningApps>
</user>
<!-- 如果用户没有设置最多运行的app个数,那么用户默认运行10个 -->
<userMaxAppsDefault>10</userMaxAppsDefault>
<!-- 定义我们的队列 -->
<!--
weight
资源池权重
aclSubmitApps
允许提交任务的用户名和组;
格式为: 用户名 用户组
当有多个用户时候,格式为:用户名1,用户名2 用户名1所属组,用户名2所属组
aclAdministerApps
允许管理任务的用户名和组;
格式同上。
-->
<queue name="root">
<minResources>512mb,4vcores</minResources>
<maxResources>102400mb,100vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<weight>1.0</weight>
<schedulingMode>fair</schedulingMode>
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<aclSubmitApps>*</aclSubmitApps>
</queue>
<queue name="hadoop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<aclSubmitApps>hadoop hadoop</aclSubmitApps>
<aclAdministerApps>hadoop hadoop</aclAdministerApps>
</queue>
<queue name="develop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1</weight>
<aclSubmitApps>develop develop</aclSubmitApps>
<aclAdministerApps>develop develop</aclAdministerApps>
</queue>
<queue name="test1">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>test1,hadoop,develop test1</aclSubmitApps>
<aclAdministerApps>test1 group_businessC,supergroup</aclAdministerApps>
</queue>
</queue>
<!-- 包含一系列的rule元素;这些rule元素用来告诉scheduler调度器,进来的app按照规则提交到哪个队列中
有多个rule的话,会从上到下进行匹配;
rule可能会带有argument;所有的rule都带有create argument,表示当前rule是否能够创建一个新队列;默认值是true
-->
<queuePlacementPolicy>
<!-- app被提交到指定的队列;如果队列不存在,则不创建 -->
<rule name="specified" create="false"/>
<!-- app被提交到提交此app的用户所属组的组名命名的队列;如果队列不存在,则不创建 -->
<rule name="primaryGroup" create="false" />
<!-- 如果上边的rule都没有匹配上,则app提交到一下队列;如果没有指定queue值,默认值是root.default -->
<rule name="default" queue="root.default"/>
</queuePlacementPolicy>
</allocations>
第三步:将修改后的配置文件拷贝到其他机器上
- 将node01修改后的yarn-site.xml和fair-scheduler.xml配置文件分发到其他服务器上面去
cd /xsluo/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop
[hadoop@node01 hadoop]# scp yarn-site.xml fair-scheduler.xml node02:$PWD
[hadoop@node01 hadoop]# scp yarn-site.xml fair-scheduler.xml node03:$PWD
第四步:重启yarn集群
- 修改完yarn-site.xml配置文件之后,重启yarn集群,node01执行以下命令进行重启
[hadoop@node01 hadoop]# cd /xsluo/install/hadoop-2.6.0-cdh5.14.2/
[hadoop@node01 hadoop-2.6.0-cdh5.14.2]# sbin/stop-yarn.sh
[hadoop@node01 hadoop-2.6.0-cdh5.14.2]# sbin/start-yarn.sh
第五步:修改任务提交的队列
- 修改代码,添加我们mapreduce任务需要提交到哪一个队列里面去
Configuration configuration = new Configuration();
configuration.set("mapreduce.job.queuename", "hadoop");
- hive任务指定提交队列,hive-site.xml文件添加
<property>
<name>mapreduce.job.queuename</name>
<value>test1</value>
</property>
- spark任务运行指定提交的队列
1- 脚本方式
--queue hadoop
2- 代码方式
sparkConf.set("spark.yarn.queue", "develop")














 2746
2746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









