









Hadoop 平台伪分布式模式的构建部署过程?!值得推荐!!
前言:
大数据也就是"Big data",那么是什么是大数据呢?笔者认为就是海量数据,非常多的数据的意思。那么大数据为啥在这几年又会如此之火呢?主要还是得益于中国信息高速公路发展的结果。首先是通信链路的发展。由原来的以太网、ADSL传输到后面的光纤到户,桌面百兆的速率的提升;由原来的2G到现在的4G以及马上要来的5G。这些优质高效的传输方式支撑着当下信息社会的稳定发展;其次就是移动化、智能化的发展,每个人几台手机、N个APP、N个平板,移动化趋势的加入,使得人们可以随时随地的消费和生产数据;智能化的发展就体现了当下社会国人对于各种需求的不断提升。最重要的是什么,就是我们中国社会发展了,人民有钱了。对吧。所以笔者认为基于这些原因,大数据顺势而生,而且愈发重要。大数据行业生态也已经形成。正如马老师而言,我们的社会已经进入了DT时代。因此我自己也定义为一个DT人。
好,以上就是我自己个人的一点理解。那么说道大数据,必然会说到hadoop。它是什么东西呢?为什么会是它呢?一个行业的产生肯定不是只有一个公司。但是在这个行业hadoop的生态做的非常好,就是因为它有一整套完整有效的生态,各个子系统都完整匹配各平台。因此它的市场份额要远远高过其它的大数据平台。它的市场份额占用率超过80%。所以形成了市场垄断。就像安卓一样,安卓是一套生态系统的总成。它不仅仅是一个手机端的系统。因此我们称为大数据现在就用hadoop平台了。
Hadoop平台是Apache基金管理委员会组织下的一个开源的分布式系统架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。具有可靠、高效、可伸缩的特点。它是基于Java语言进行开发的。它由三大模块组成也就是HDFS\ YARN\ Mapreduce.组成。官方网站:https://hadoop.apache.org ,大家没事可以去看看。
接下来
对hadoop这款软件的三大通用组件进行一个详解
HDFS:Hadoop distributed file system. 顾名思义就是Hadoop平台下用来管理分布式文件的一个系统。其实它的一个关键作用及时分布式存储。它是hadoop体系中数据存储管理的基础。并且是一个高度容错的系统。能检测和应对硬件故障,用于在低成本的通用硬件上运行。它分为 namenode datanode两个组件
HDFS简化了文件的一致性 模型。通过流式数据的访问。提供高吞吐量的应用程序数据访问的功能。适合带有大型数据集的应用程序。它提供了一次写入多次读取的机制。数据以块的形式同时分布在集群的不同的物理机器上。
YARN 分布式资源管理器 属于hadoop第二代的分布式计算的框架,其实可以这么理解。就是一个管理资源的管理器。它可以运行多种计算框架,比如MR、Giaph 、Spark、Storm、Flink.....
MapReduce 其实按照java 开发语言来开发的一个程序就是用Java的 Map()函数进行的Reduce计算。Map将要计算的对象先分成N个Key,然后再用Reduce去对Map计算的结果进行整合规约的过程。最终会形成一个计算结果。非常适合大量计算机组成的分布式并行环境的离线数据的操作。
以上三个通用组件都是以hdfs为基础的。hdfs是hadoop运行的所有的基础。yarn 对应的配置文件 yarn-site.xml .
hdfs 对应的配置文件 hdfs-site.xml . Hadoop的核心配置文件 core-site.xml. 这个几个配置文件特别重要。
接下来,我们来部署一个Hadoop的伪分布式
伪分布式,其实不是真正的分布式。它有两种以下两个场景:
第一:开发环境下我们只需要使用Hadoop提供的一些功能,而不需要去搭建更多的集群服务。
第二:学习环境下,想尽快熟悉hadoop的功能。让大家尽快熟悉了解这个Hadoop生态。
在部署之前,我们还要用到一些常规的知识:
Hadoop 平台现在主要是三个厂家。哪三个呢?
Apache Hadoop 它是原厂,源码包供应商,所有的开发商都以它为基础
CDH hadoop 它是目前国内使用最多的一家hadoop平台。管理完善,文档齐全。我们就用它来开发,测试。
HDP hadoop 了解了解即可。
那么我们要用到 CDH hadoop ,目前我们使用CDH5 他是基于hadoop 2.6来开发升级并对外提供服务的。非常成熟
官网下载 https://www.cloudera.com/downloads/cdh/6-3-1.html 大家没事去看看里边的信息和文档,非常重要
好啦,废话少说。上干货。。。。
系统环境:
OS:CenterOS 7.6 CDH : hadoop-2.6.0-cdh5.16.2
JDK 1.8 _181

步骤如下:
第一步: 解压获取到的cdh软件包到指定目录 tar zxvf ......-C 目录
第二步:配置Hadoop ,进入刚刚解压的Hadoop目录将其中的/etc/hadoop目录单独拷贝到另外一个目录下,比如/etc/hadoop下
第三步:安装JDK 同样使用 tar zxvf ...... -C 目录
第四步 并配置环境变量 vi /etc/profile 下面是笔者的。

第五步: 创建一个用于启动hadoop的用户。不用设置密码
第六步: 授权 主要是授权hadoop的按照目录与hadoop的/etc/的配置文件的目录 授权给hadoop
chown -R hadoop:hadoop ..../hadoop 使用此命令就好
第七步:伪分布式下可以不用任何配置就可以启动服务。但是呢我们这里还是定义一个core-site.xml 他是hadoop的核心配置文件。也是通用的组件。就进入到配置文件目录下的conf目录下查看 该改以下几个就可以了。

第八步:既然定义了主机名,那么我们的宿主机的/etc/hosts目录下也要做相应的映射。也就是 ip ----hostname的映射
第九步:启动服务拉。 看服务启动正常否
切换用户 su - hadoop
/bin/hdfs namenode -format --------->必须要做 这个是产生NameNode元数据的意思
启动namenode datanode服务
sbin/hadoop-daemon.sh start namenode start
![]()
服务启动后,也会有一个端口会起来 50070端口
![]()
通过Web访问看能否OK? 一切正常

sbin/hadoop-daemon.sh start datanode start 是否成功呢?通过Jps看一下结果
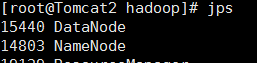
都有了,namenode datanode 都有了服务也正常。
接下来,启动resourcemanager ,也就是启动RM。
sbin/yarn-daemon.sh start resourcemanager 启动成功。

它启动后,就会有一个8088 的端口,是否OK呢?我们也来访问一下,发现也正常。

于是我们的一个伪分布式服务就搭建成功拉。我们还可以在上面去跑更多的应用服务。进而更快的深入了解我们的平台。
大家快快搭建吧。
欢迎大家关注我。后续我将时时更新我的个人博客信息。
我主要是跟大家一起来探讨linux 容器 自动化 大数据、AI、 Python方面的一些学习历程。一起共同进步。。。















 1772
1772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









