









实验:部署Hadoop伪分布式集群
开始部署之前,我们要先向虚拟机里导入安装包,进行解压安装,配置好JDK,Hadoop,之后,进入关键步骤:
1、新建文件,存放jdk和hadoop,方便后面管理:
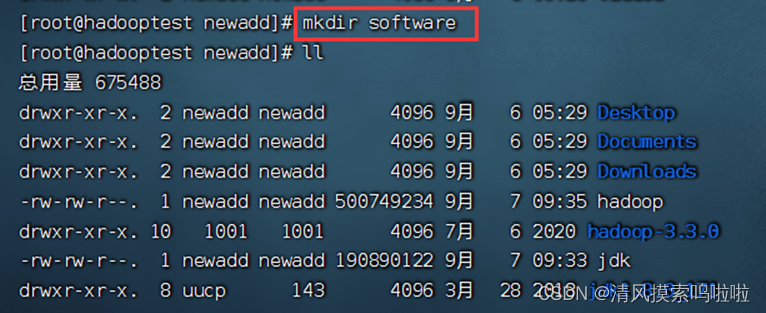
2、查看文件存放路径,方便后面配置jdk和hadoop的环境:

3、配置好环境,检测其是否完成:
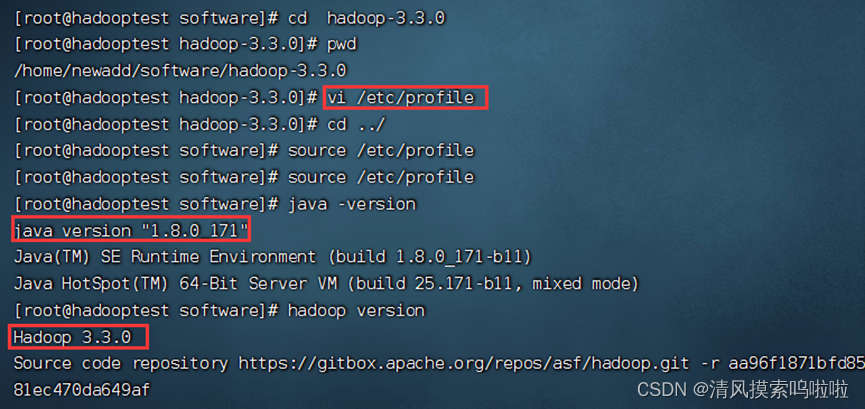
4、容易搞忘记的点是在安装部署hadoop 伪分布式集群时,所处的路径和目录,要在第一个红色框里的目录下才可进行:

5、一下几个文件输入相应内容:

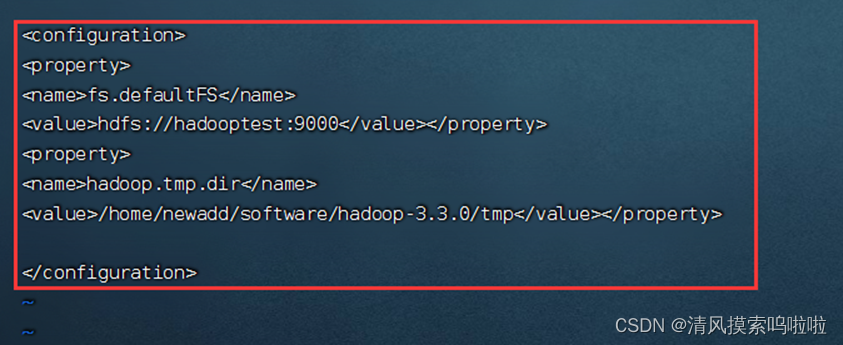
配置:vi core-site.xml
配置:vi hdfs-site.xml

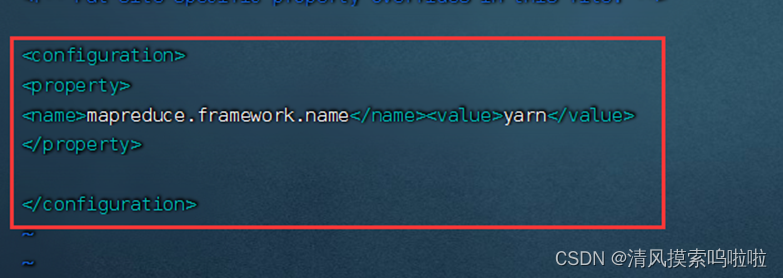
配置:vim mapred-site.xml
配置:vi yarn-site.xml
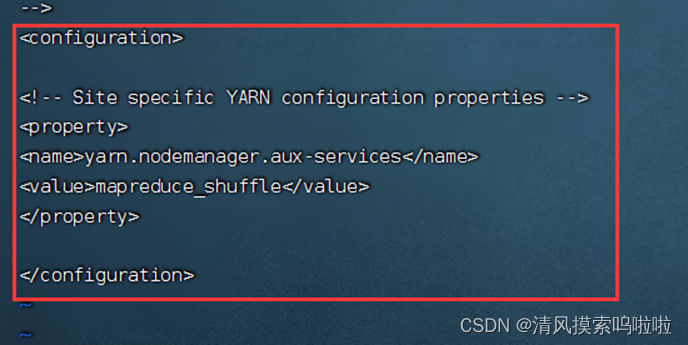
workers也需要配置。

6、格式化HDFS:

7、格式化成功:

8、重启即可:

注意,开始之前配置IP地址,永久关闭防火墙,配置免密钥。
9、在浏览器里搜索(出现以下截图即可):
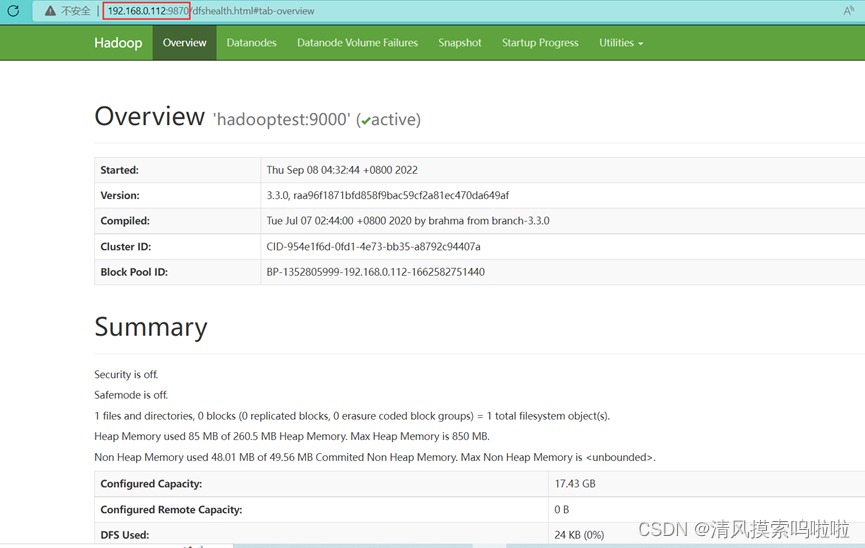
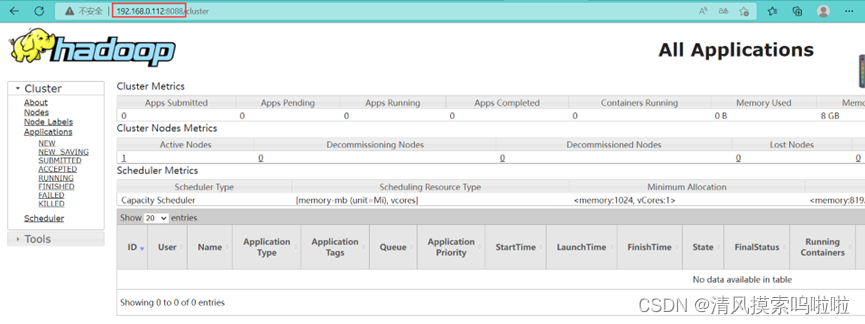















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











