







浅谈Hive
文章目录
Hive
Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用分折数据。可以理解Hive是套壳Hadoop。
其实不然,Hive的最大的魅力在于用户专注于编写HQL转换成为MapReduce程序完成对数据的分析。
Hive的运行机制
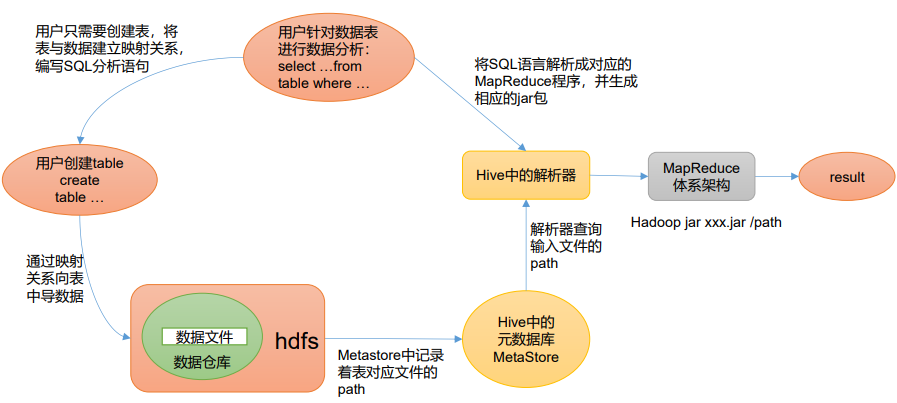
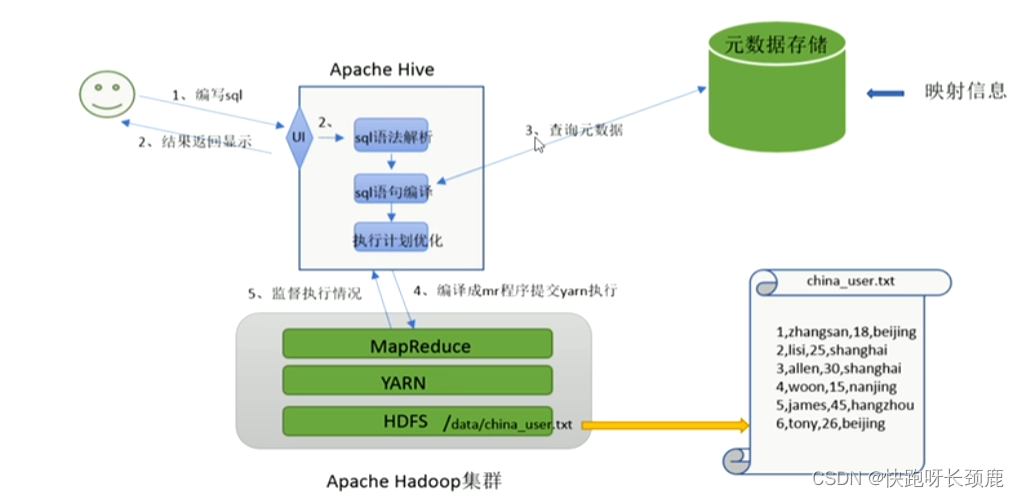
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,
结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将
执行返回的结果输出到用户交互接口。
文件映射
映射在数学上称之为一种对应关系,比如y:x+1,对于每一个x的值都有与之对应的y的值。
在Hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。
映射信息专业的叫法称之为元数据信息(元数据是指用来描述数据的数据metadata)。
Hive能将数据文件映射成为一张表,这个映射是指什么?
文件和表之间的对应关系
Hive本身承担了什么功能职责?
SQL语法解析编译成为MapReduce
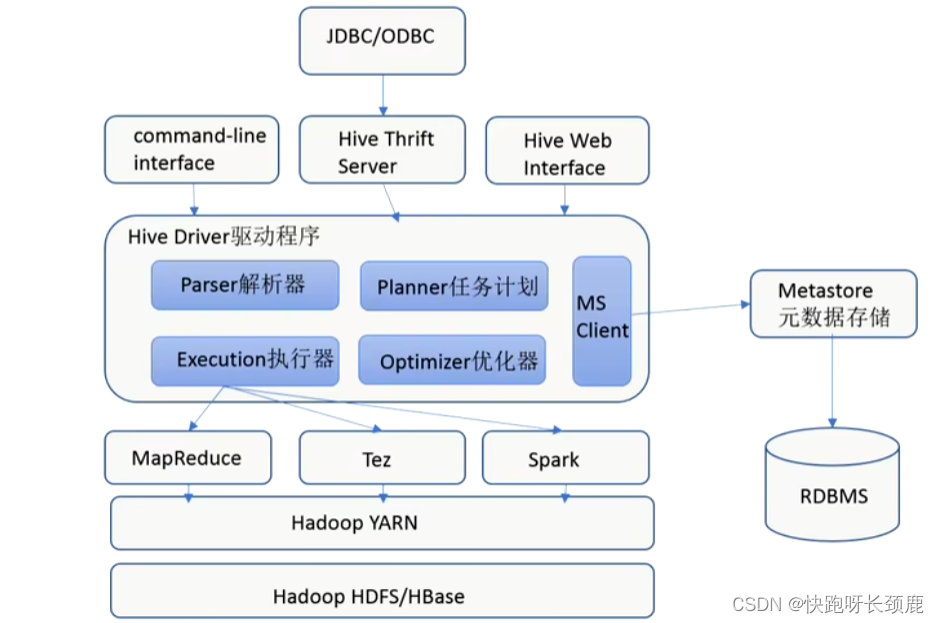
Hive组件
元数据(Metadata)
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(dataaboutdata),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
元数据存储
通常是存储在关系数据库如mysql/derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
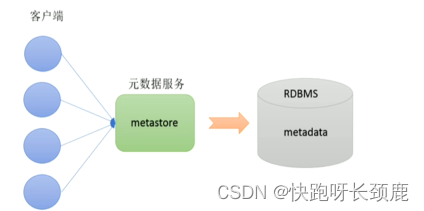
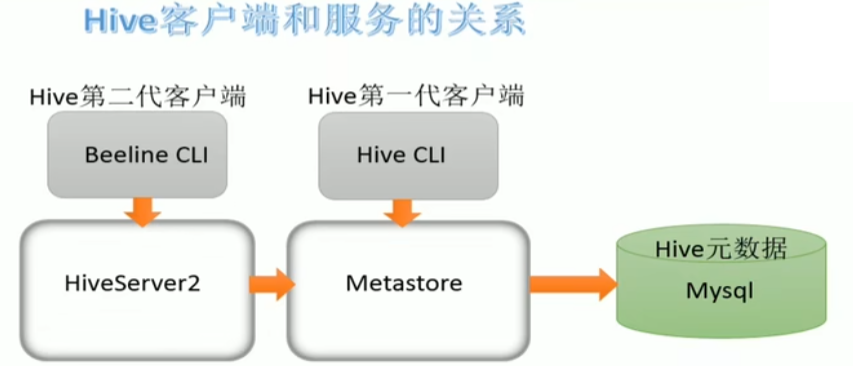
元数据服务(Metastore)
Metastore即元数据服务。Metastore服务的作用是管理Metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MYSQL数据库来存取元数据。
有了Metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MYSQL数据库的用户名和密码,只需要连接metastore服务即可。某种程度上也保证了hive元数据的安全。
Metastore配置方式
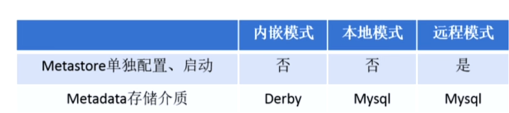
metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
区分3种配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metadata存储在内置的derby中,还是第三方RDBMS,比如mysql
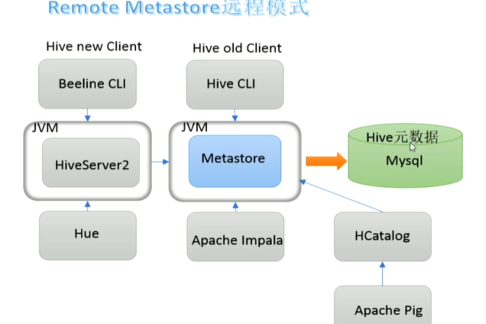
Metastore远程模式
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过
Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
Hive启动方式
第一种(本地)
hive
第二种beeline
在hive安装的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
nohup hive --service metastore &
nohup hive --service hiverserver2 &
后台启动 nohup hive --service mestore & (日志 在当前路径下nohup.out下)















 431
431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









