







 这篇博客探讨了在因果随机森林中如何确定合适的树木数量。作者指出,虽然默认设置通常是2000,但为了学术研究的严谨性,通常需要通过绘制渐进图来寻找预测方差趋于稳定的树木数量。文章提供了一种使用R语言进行实验的方法,并建议通过观察中位数预测方差的变化来决定最佳的树的数量。
这篇博客探讨了在因果随机森林中如何确定合适的树木数量。作者指出,虽然默认设置通常是2000,但为了学术研究的严谨性,通常需要通过绘制渐进图来寻找预测方差趋于稳定的树木数量。文章提供了一种使用R语言进行实验的方法,并建议通过观察中位数预测方差的变化来决定最佳的树的数量。
 前言
前言
推断因果性和分析异质性是统计学家在处理混杂任务中的圣杯。传统且主流的方法有:倾向性评分、分层分享、比例风险模型等。新的方法也有很多,代表就是:因果随机森林。这种算法,浅看难度一般,深入探索发现坑还是很多的。这篇博客不对算法做深入探讨,仅仅是我在阅读文献中发现确定森林模型的树木数量参数 the number of trees 这个任务,所谓研究因果森林的grf包中未能提及,因此,我对针对这个任务进行部分很浅的工作。
不过,私以为,这个参数是极为重要的,默认因果森林中是2000,而且内部提供了turn.para来直接优化参数,我认为,在一般情况下,不改其实也很ok的。2000真的很大了,一般错误率都稳定了。但是,各位研究牲们,发学术文章,扪心自问,感觉还是要有一张图,才好交差吧?
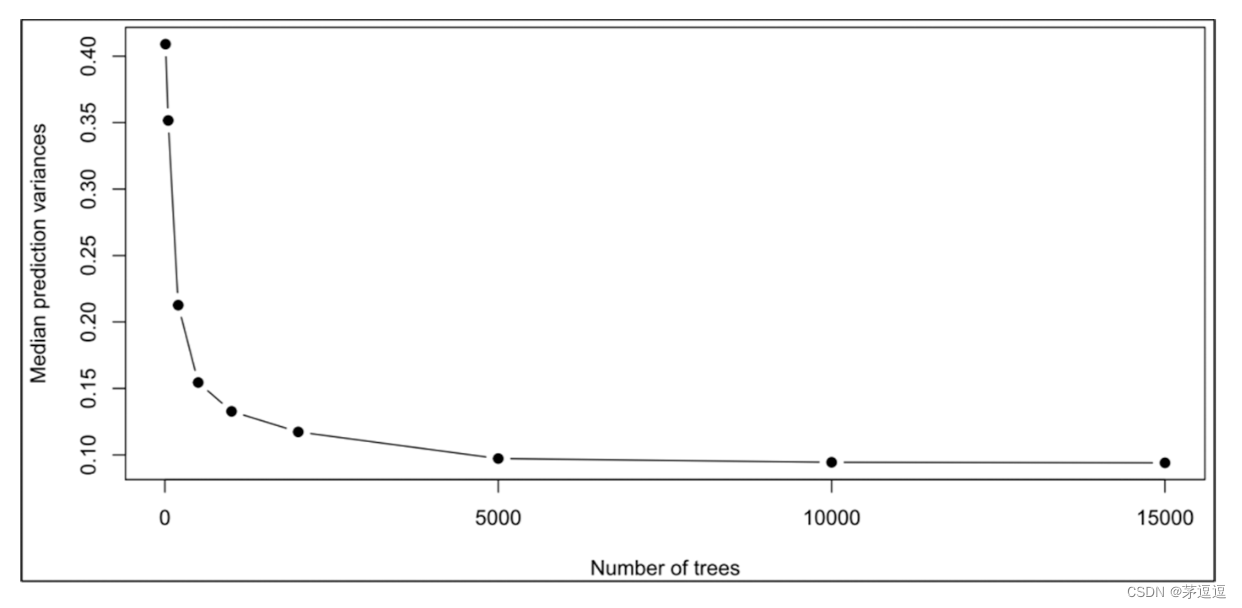
且看这篇文章中的图2,他就是一张"渐进图"来确定出最合理的树的数量。
其中,y轴是Median prediction variances x轴是 the number of trees.
prediction variances在哪?搜一搜不就知道了。
非常好找对不对?

小结: prediction variances 一般肯定和predictions相伴而生,随机森林建模肯定会输出一个错误率给你看看这个模型好不好的吧。
那你肯定会说,哎不对吧,一般函数设计会把这个Error直接print的吧?简单,你试一试不就好了:

结果没有。是不是在模型(S3-S4)项目中呢?

试了还是没有,所以还是使用了grf-lab中的方法
causal.forest = causal_forest(X, Y, W)
prediction.result = predict(causal.forest, X.test, estimate.variance=TRUE)
standard.error = sqrt(prediction.result$variance.estimates)这里X.test这个外部数据集其实是不能用的,要看森林的goodness,你要使用袋外数据,所以应该改为
prediction.result = predict(causal.forest, estimate.variance=TRUE)
standard.error = sqrt(prediction.result$variance.estimates)引入for循环,复习一下进度条
那么直接在树木500、1000、1500。。。。。5000。。。这些设定下,看一下中位数预测方差能怎么变化,什么时候趋于稳定不久知道了。
r语言代码实现
# simulation
n = 2000; p = 10
X = matrix(rnorm(n*p), n, p)
W = rbinom(n, 1, 0.5)
Y = pmax(X[,1], 0) * W + X[,2] + pmin(X[,3], 0) + rnorm(n)
# seting
list <- list()
num_tree<- seq(500,5000,100)
interval <- 50
set.seed(1234) # for random procee, we set a specific seed to reproduct the experiment.
# 第一个位置 创建进度条
pb <- txtProgressBar(style=3)
star_time <- Sys.time() ## 记录程序开始时间
for (i in 1:interval) {
causal.forest = causal_forest(X, Y, W,num.trees = num_tree[i])
prediction.result = predict(causal.forest, estimate.variance=TRUE)
standard.error = sqrt(prediction.result$variance.estimates)
list [[i]] <- median(standard.error)
# 第二个位置 定义进度条
setTxtProgressBar(pb, i/interval)
}
end_time <- Sys.time() ## 记录程序结束时间
## 第三个位置关闭进度条
close(pb)
## 计算程序运行时间
cat(run_time <- end_time - star_time,"mins")
#画出 Tree vs. Median prediction variances------------------------------------------------------------
plot((1:50)*100,list %>% unlist(),ylab = "Median prediction variances",xlab = "Number of trees",type='o')结果
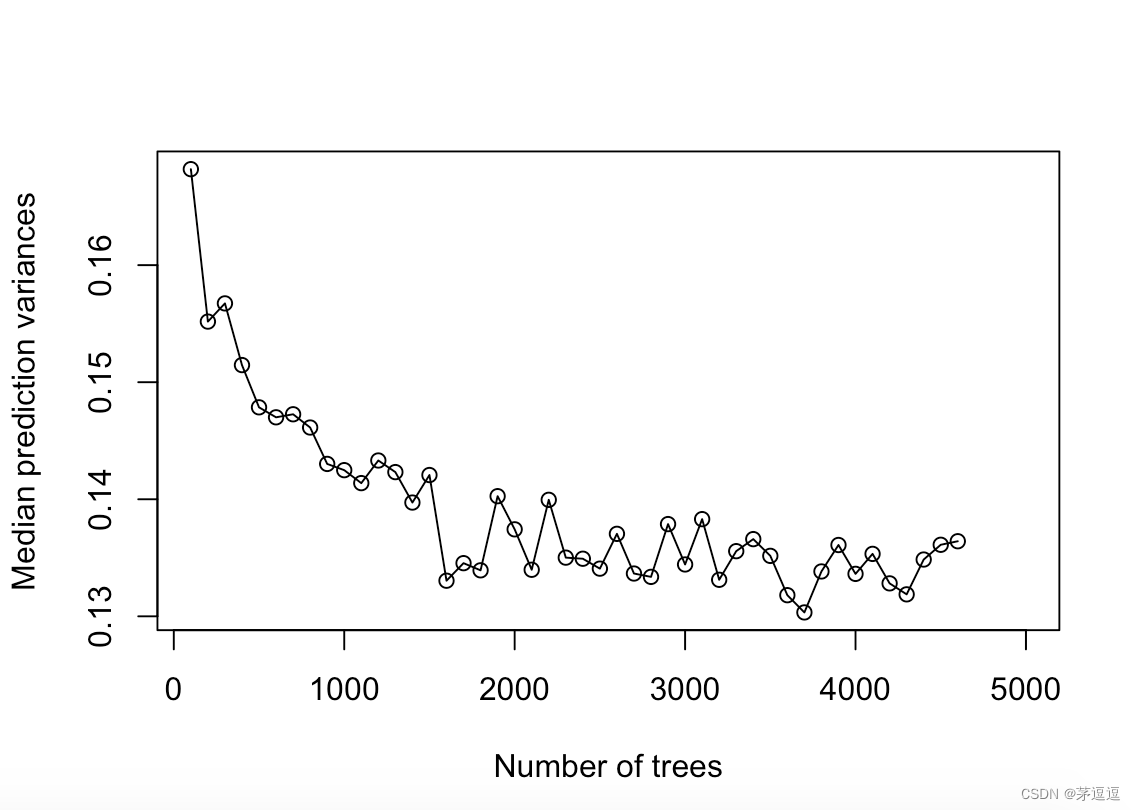
结论是the number of trees 设置为 2000,估计可以说比较准确。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











