






装包
- 1、命令行式安装
- 2、pycharm内安装
1、命令行式安装
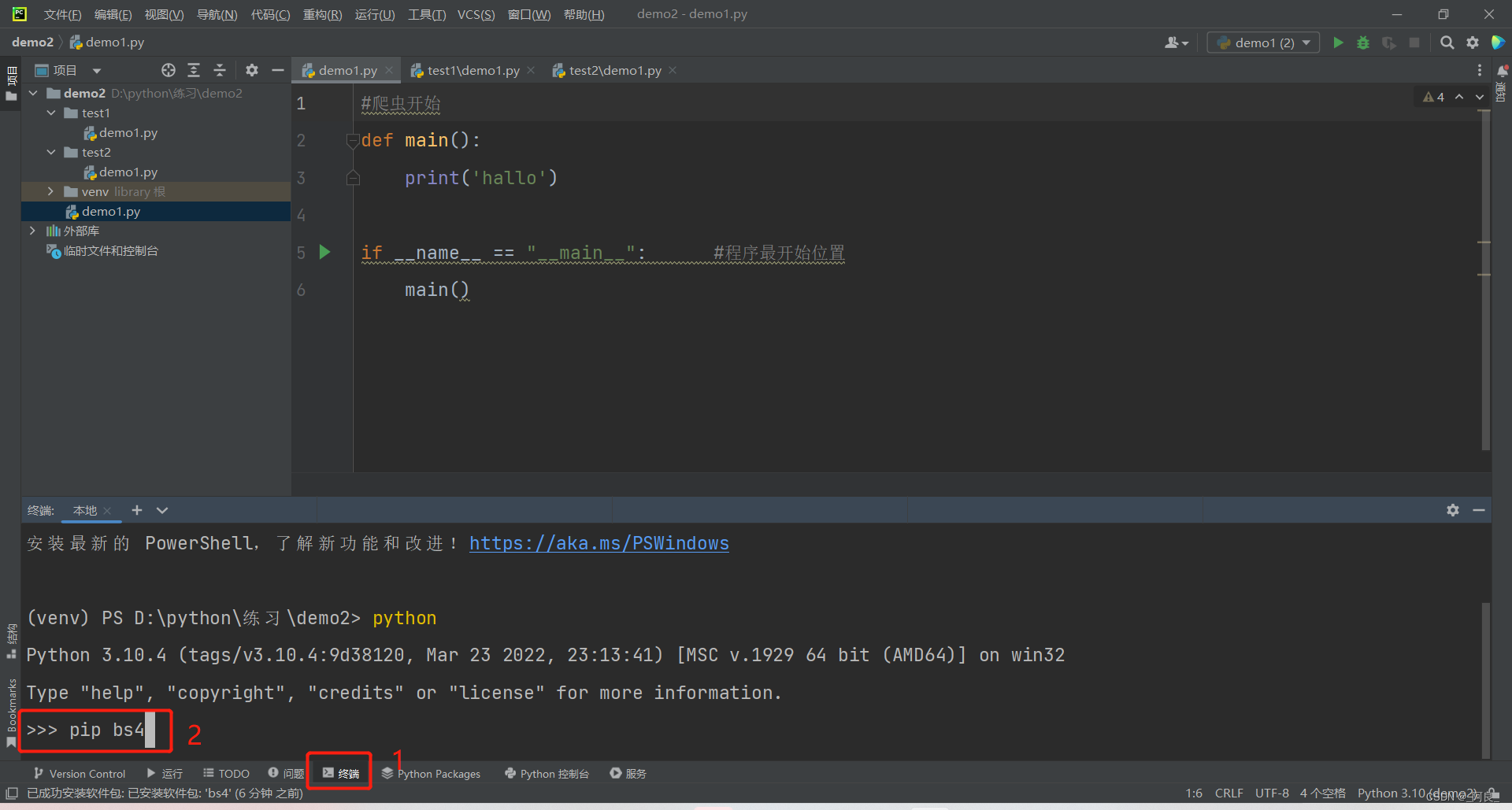
或win+r→cmd→pip bs4
2、pycharm内安装
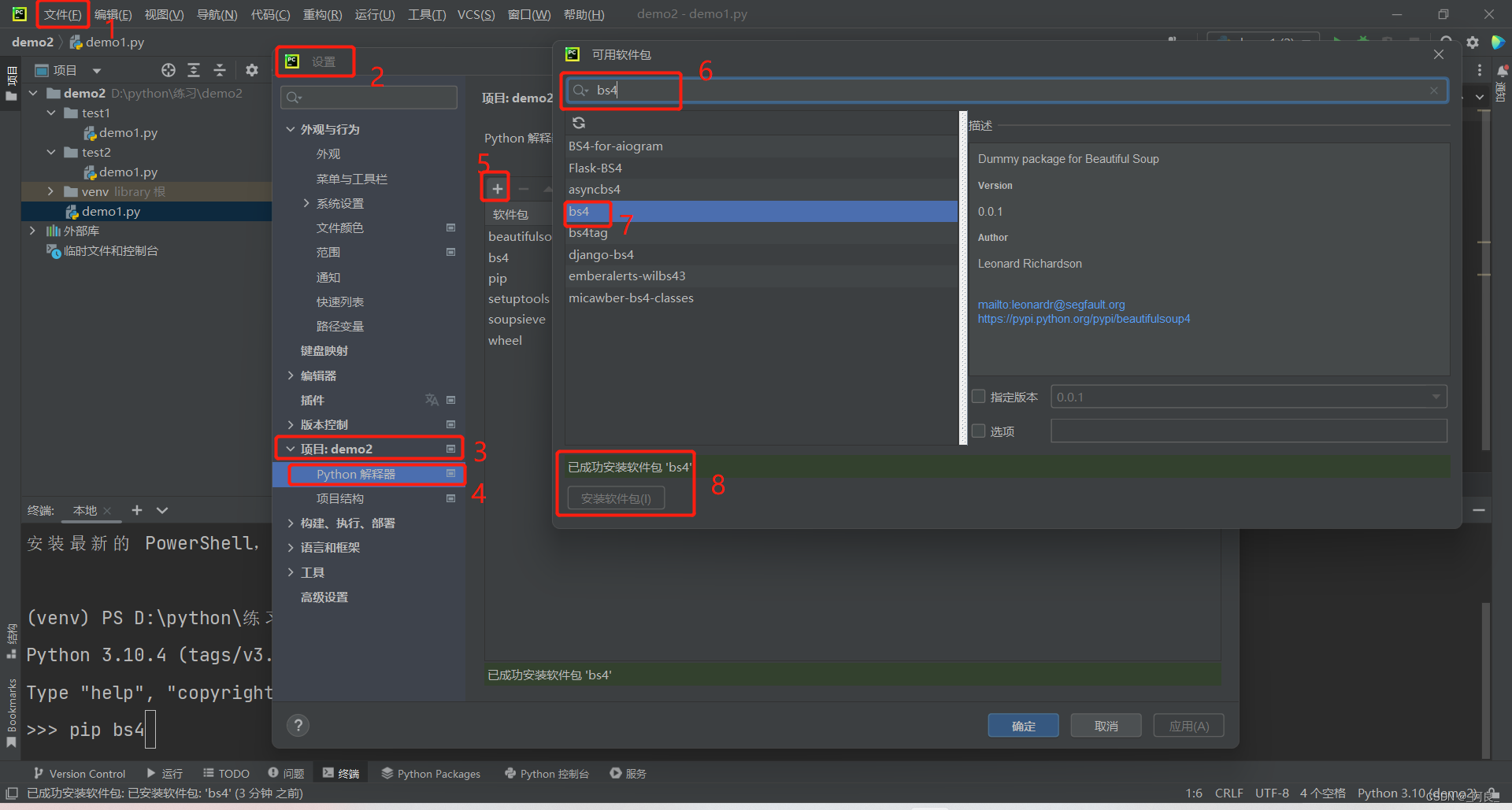
爬虫需要用到的包:
#需要引用的包及其作用
# import bs4 #网页解析,获取数据
# import re #正则表达式,进行文字匹配
# import nrlib.request,urllib.error #自定URL,获取网页数据
# import xlwt #进行excel操作
# import sqlite3 #进行SQLite数据库操作
定义程序开始的位置
def main():
print('hallo')
if __name__ == "__main__": #程序最开始位置
main()
爬虫的思路
- 先确定需要爬的网页
- 解析数据
- 保存数据
#这只是一个爬虫的基本框架
def main():
baseurl = "https://movie.douban.com/top250?start=" #引入网页
datelist = getdate(baseurl) #爬取baseurl中的内容
savepath = ".\\豆瓣电影top250" #获取完内容给一个存放的路径
savedate(savepath) #执行保存数据程序
#爬取网页
def getdate(baseurl):
datelist = []
#逐一解析数据
return datelist
#保存数据
def savedate(savepath):
print('save...')
if __name__ == "__main__": #程序最开始位置
main()















 2040
2040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









