






测试urllib库
引入urllib库
import urllib.request
具体使用方法!
#以get方式获取网址内的内容
response = urllib.request.urlopen("http://www.baidu.com") #通过urllib.request.urlopen的方法读取网页
#print(response.read()) #以读的形式返回从网页中爬到的内容(实际上就是网页的源码)
print(response.read().decode('utf-8')) #对获取到的网页源码进行utf-8的形式解码(中文解码)
补充:测试相应的网站—httpbin.org
#以post方式获取网址内的内容(模拟用户名+密码方式登录访问网页)
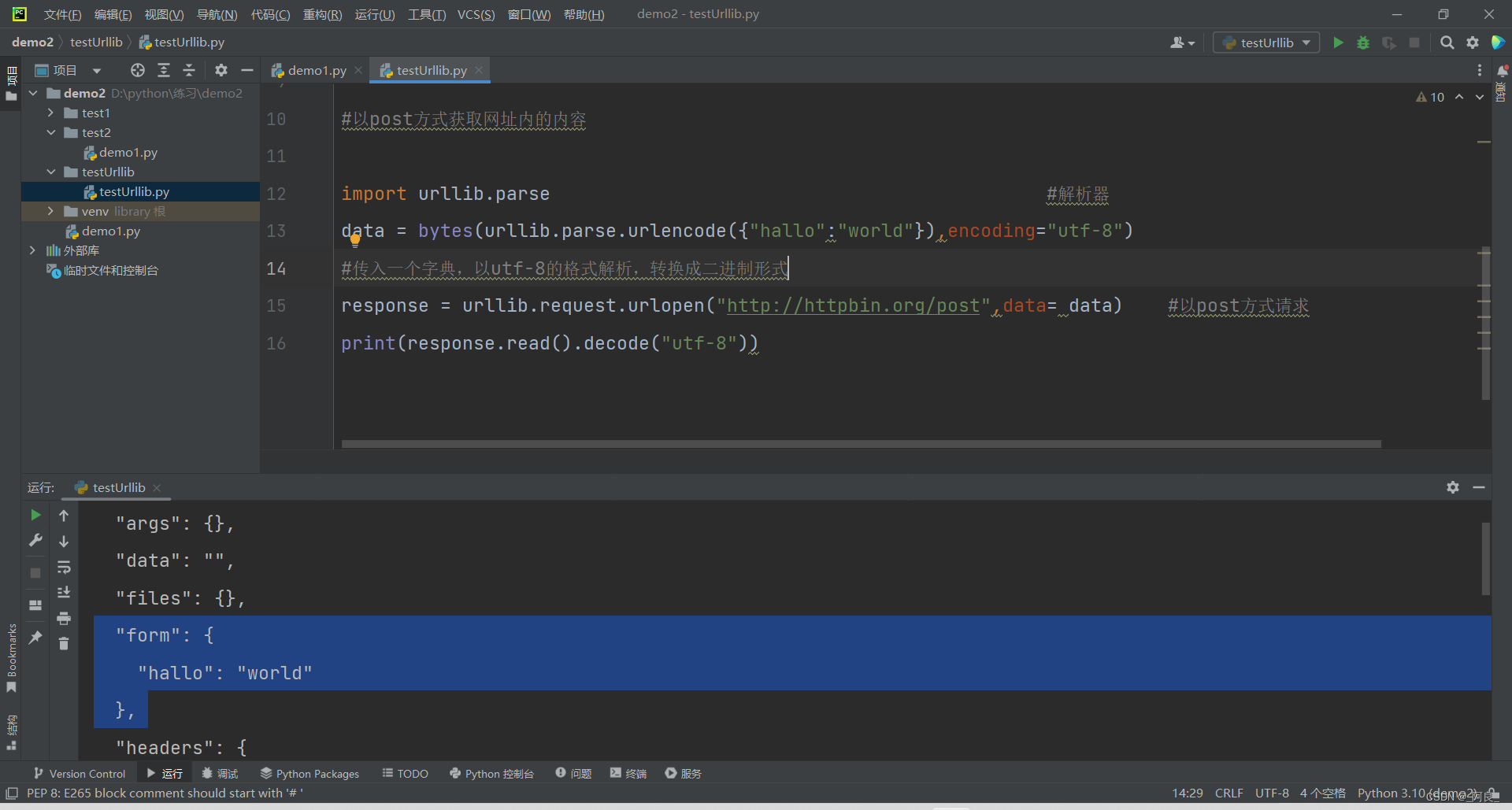
import urllib.parse #解析器
data = bytes(urllib.parse.urlencode({"hallo":"world"}),encoding="utf-8")
#传入一个字典,以utf-8的格式解析,转换成二进制形式文件(实质hallo:world就是用户名和密码)
response = urllib.request.urlopen("http://httpbin.org/post",data= data) #以post方式请求
print(response.read().decode("utf-8"))
#以get形式模拟访问网页
response = urllib.request.urlopen("http://httpbin.org/get")
print(response.read().decode("utf-8"))
#返回的"User-Agent": "Python-urllib/3.10", 说明了网站识别出访问主体是Python(非人)
#超时处理
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout = 0.01) #0.01秒没响应,则进行异常处理
print(response.read().decode("utf-8"))
except urllib.error.URLError as e:
print("超时")
response = urllib.request.urlopen("http://www.baidu.com")
print(response.getheaders()) #获取访问网站时自己暴露给网站请求的属性(自己的信息)
#把自己伪装成浏览器访问网页1
url = "http://httpbin.org/post"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32",
"X-Amzn-Trace-Id": "Root=1-62737aaf-65680442658d9d0328dd7256"
} #网页中F12找到这个访问时候的代理(实际就是用这个身份去访问网页的)!!字典型!!
data = bytes(urllib.parse.urlencode({'name':'li'}),encoding = 'utf-8')
req = urllib.request.Request(url=url,data=data,headers=headers,method="POST") #自己的伪装
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))
#以伪装成浏览器的身份访问豆瓣
url = "https://www.douban.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.41 Safari/537.36 Edg/101.0.1210.32",
"X-Amzn-Trace-Id": "Root=1-62737aaf-65680442658d9d0328dd7256"
} #网页中F12找到这个访问时候的代理(实际就是用这个身份去访问网页的)!!字典型!!
data = bytes(urllib.parse.urlencode({'name':'li'}),encoding = 'utf-8')
req = urllib.request.Request(url=url,headers=headers) #自己的伪装
response = urllib.request.urlopen(req)
print(response.read().decode("utf-8"))















 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









