







Prometheus
Time Series
时序数据库,跟着一个时间轴往前走
-
Data scheme
- identifier -> (t0,v0),(t1,v1),(t2,v2),(t3,v3),…
-
Prometheus Data Model
- {
-
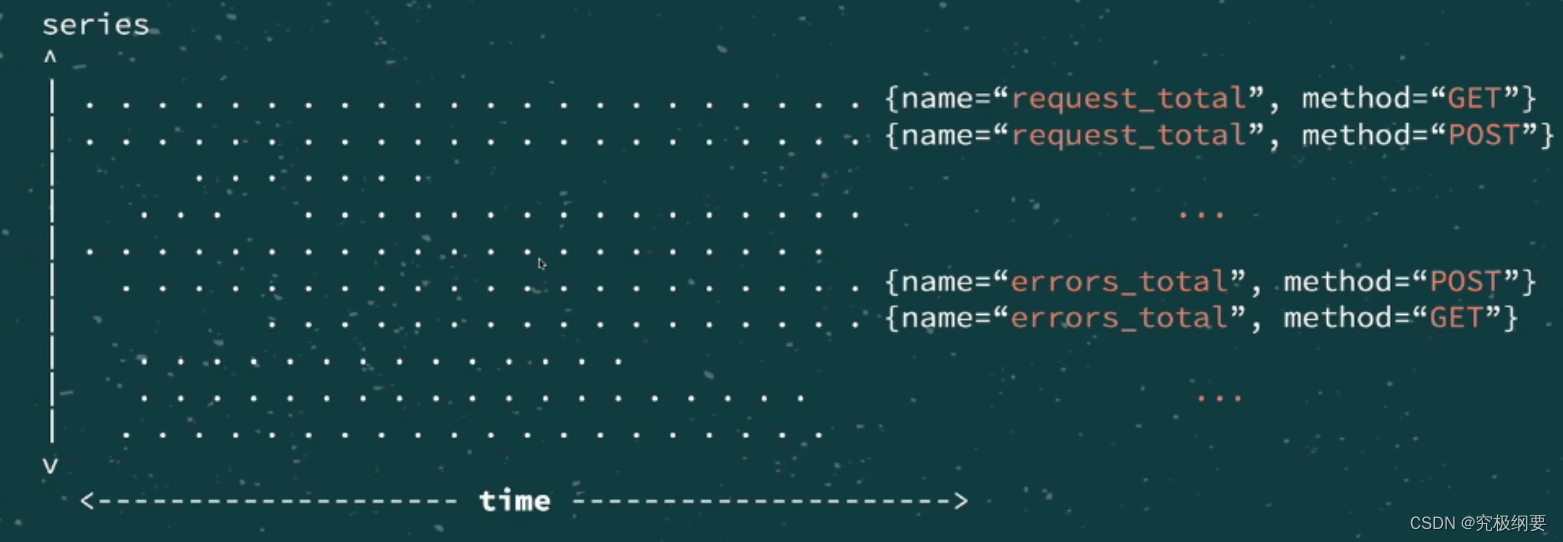
Typical set of series identifiers

-
Query
- _ name_=“requests_total” selects all series belonging to the requests_total metric.
- method=“PUT|POST” -selects all series method is PUT or POST.
Prometheus v1.x-存储V2版本
-
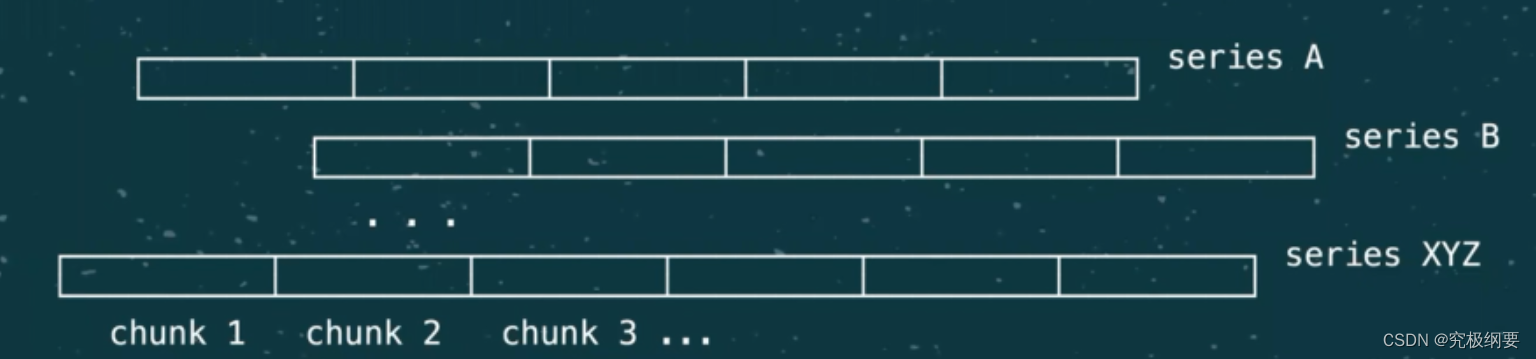
每个time series 一个文件
-
在内存里批处理 1kb chunks
-
弊端:
- chunk在内存里,如果程序丢掉或者node crashed,chunk马上丢掉了
- series维度很多,files很多,i节点很快就会被耗尽,硬盘写不进去了
- 几千个chunk写入硬盘,硬盘会很忙
- 保持file打开并且进行I/O操作,会造成高延迟
- 旧数据需要被清除,导致SSD写入放大
- CPU/MEM/DISK资源耗费巨大
-
Series Churn:一些series变不活跃,一些变的很活跃
prometheus不知道到底是否应该存在内存当中
Prometheus v2.x-存储V3版本
-
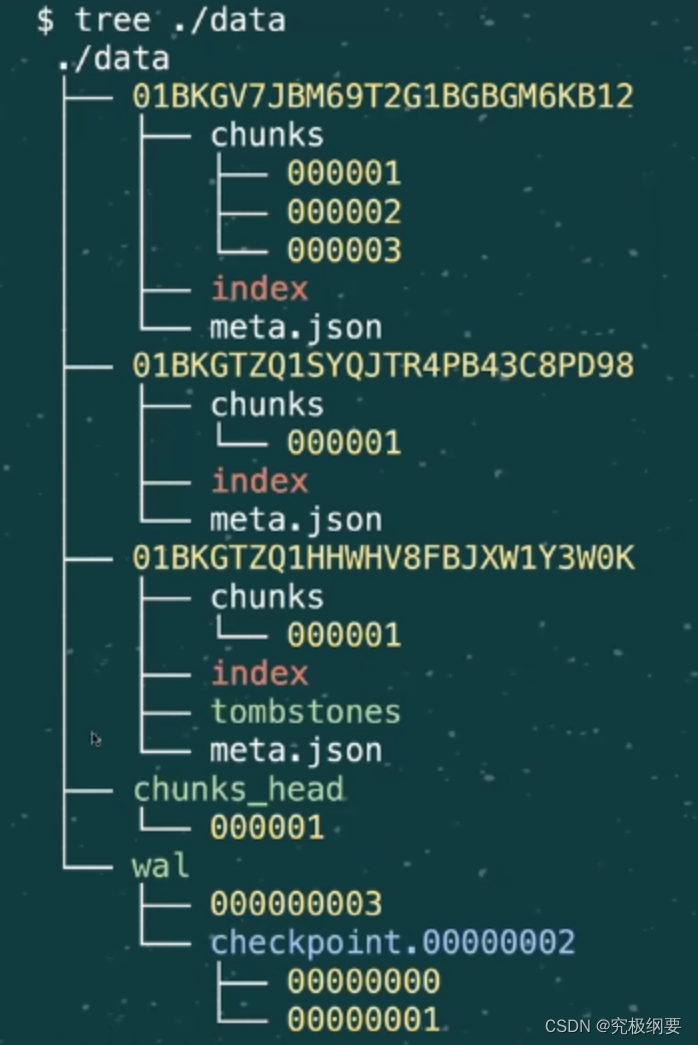
存储布局
- 01xxxx 是data block
- ULID:和UUID很类似,但是可以排序
- chunk 目录
- index 数据索引,倒排索引
- meta.json
- tombstone删除数据,放入叫tombstone的文件里
- wal Write-Ahead Log预写日志,先写日志,再数据操作

- chunk_head 可以改
- Chunk 有120个samples,默认2h,chunk会被cut
- 01xxxx 是data block
-
注意:
- 数据每两个小时保留到磁盘中
- WAL用于数据恢复
- 2小时一次,可以有效查询某一个时间范围数据
-
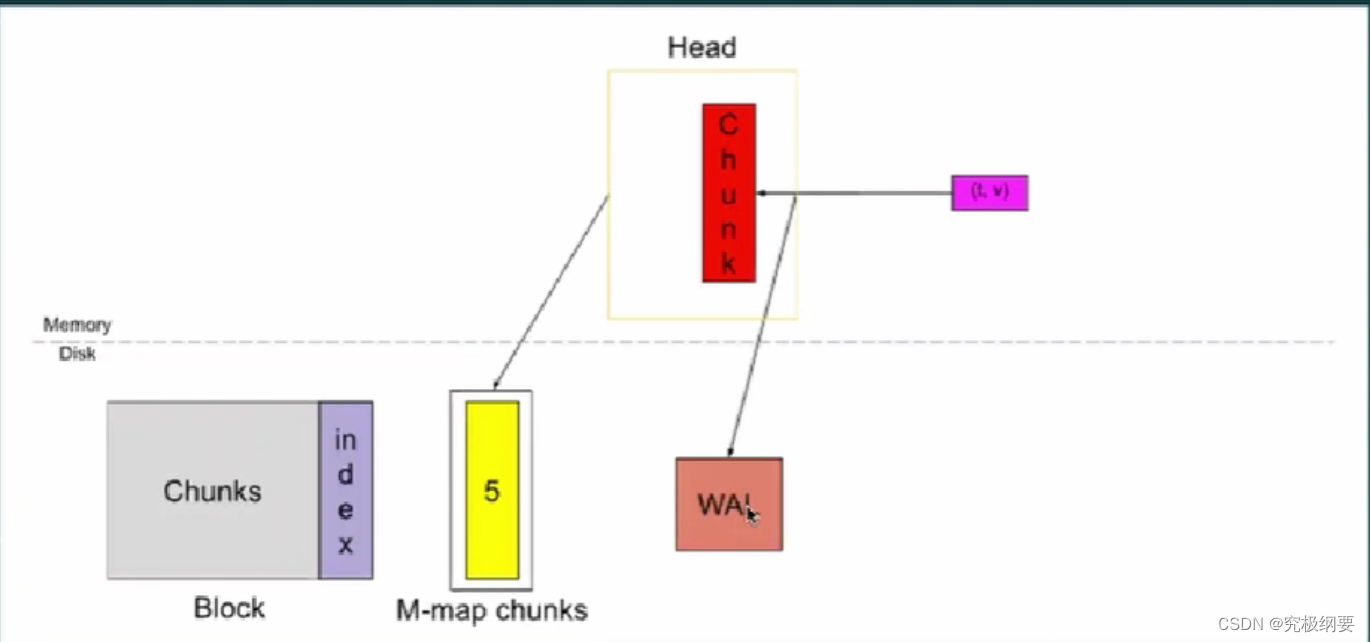
Blocks: 小数据库
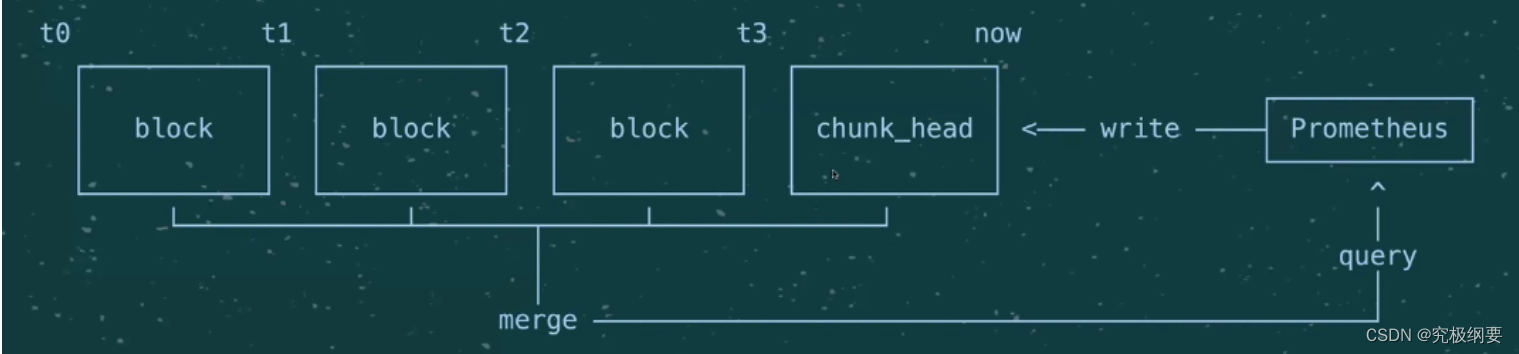
- block不可改
- prometheus来的数据先放入chunk_head里,满了以后放进block变成只读
- 查询数据进入小block里,得到的数据merge到前端用户
-
Chunk-head
- 不是所以chunks 都存在内存
- 当chunk被cut,disk和mmap都会更新
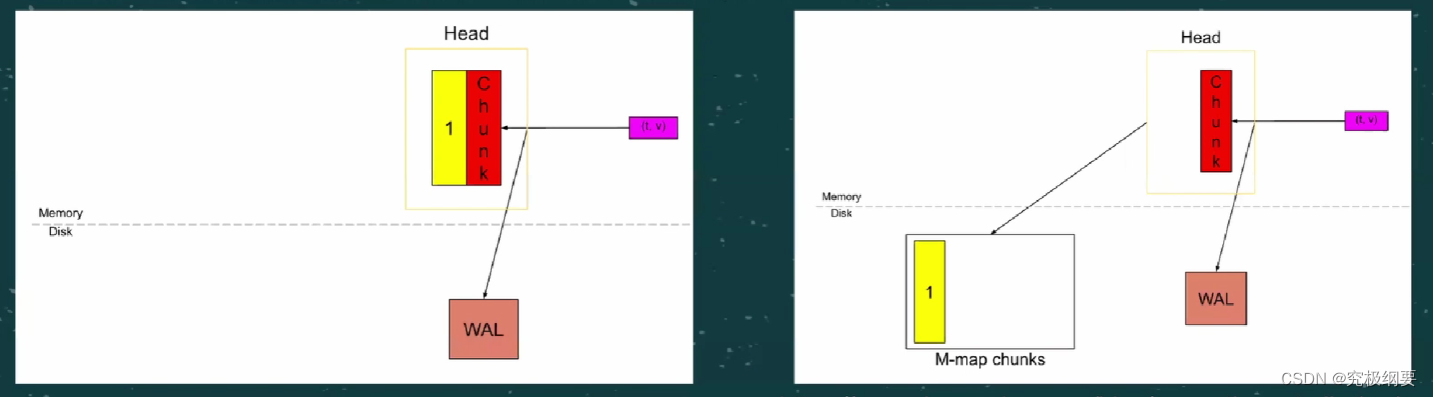
-
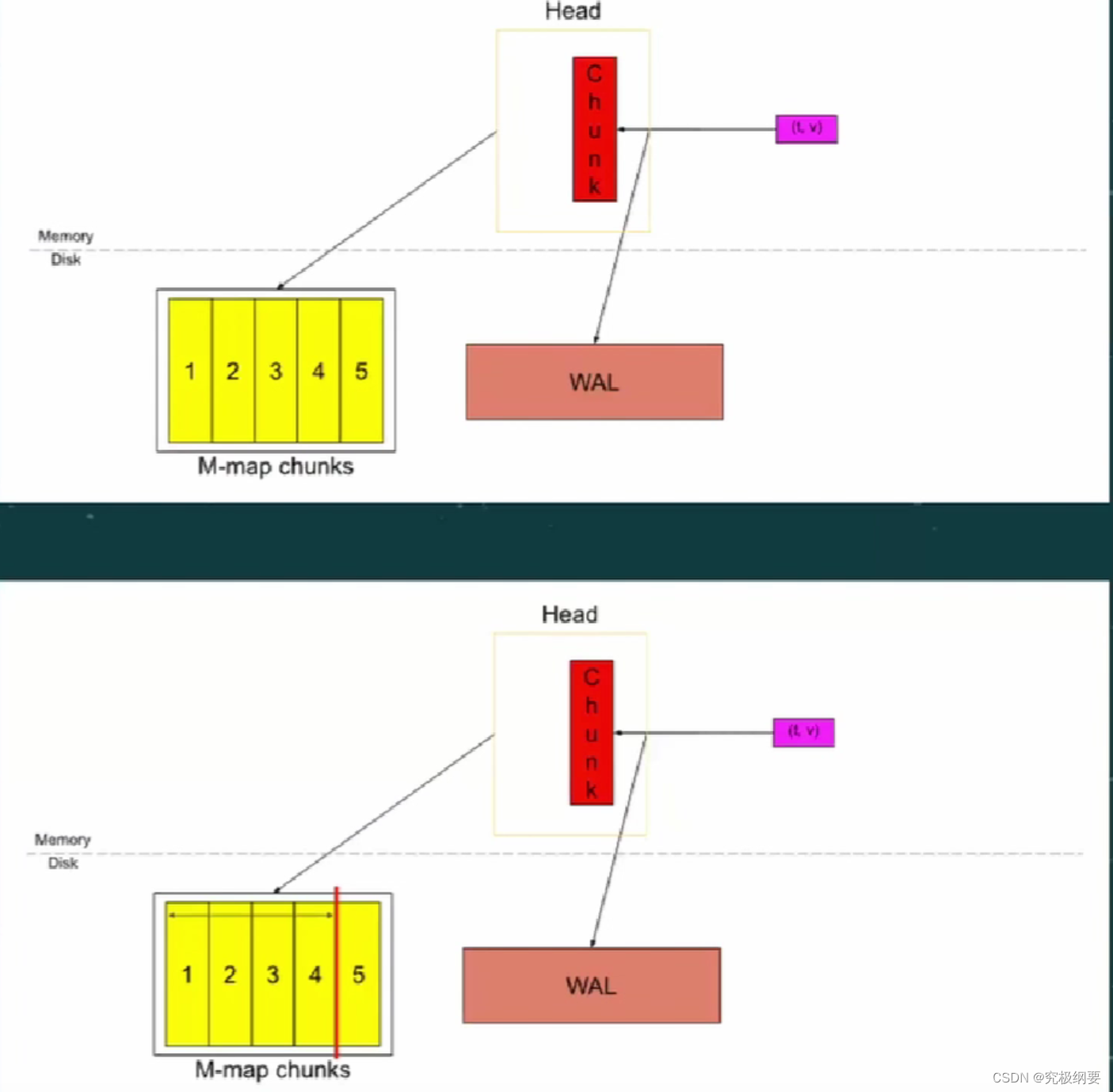
chunk head -> Block
chunks在3h内,前两小时的chunks(1,2,3,4)放到block里
WAL删除,checkpoint生成
-
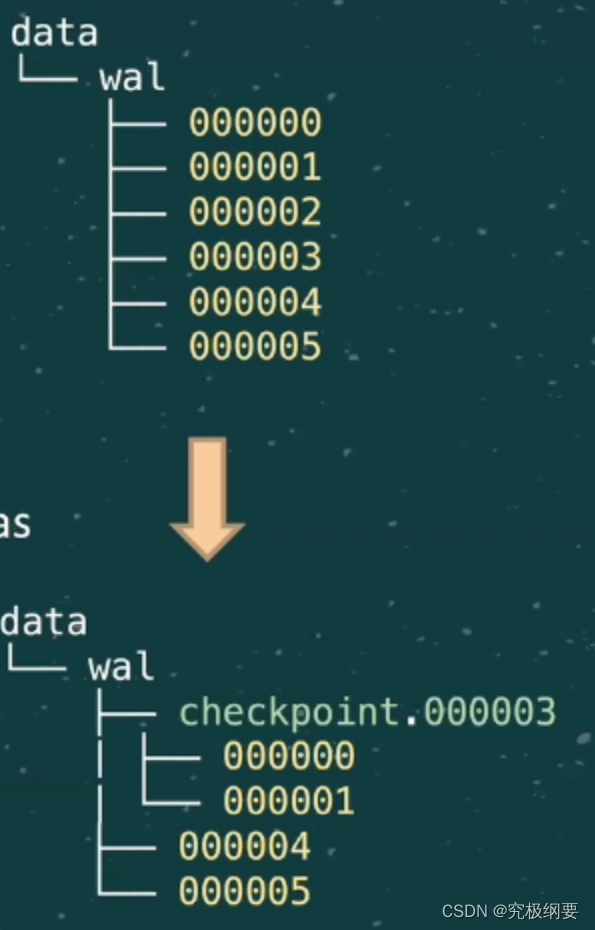
Prometheus WAL & Checkpoint
- WAL里也有许多chunk,到达一定时间点,做checkpoint操作
- wal记录:包括Series以及对于的Samples
- 第一次见到series就进行Series记录
- Sample记录所有包含sample的write请求
- WAL Truncation -Checkpoint
- 删除所有不在Head中的series记录
- 删除时间T之前的所有samples
- 删除时间T之前的使用tombstone记录
- 用从wal出现的同样方式保留剩余的series、samples、tombstone
- wal记录:包括Series以及对于的Samples
- WAL里也有许多chunk,到达一定时间点,做checkpoint操作
-
优点:
- querying time range变容易
- disk write更容易
- chunk保留住了
- 可以灵活调整chunk size
- 删除旧数据变得很容易















 3228
3228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









