






LeetCode面试题12: 深度优先搜索(DF)、广度优先搜索和递归算法
 图1
图1
深度优先搜索
深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为:
- 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以,需要标记 V1 的状态为访问过;
- 然后遍历 V1 的邻接点,例如访问 V2 ,并做标记,然后访问 V2 的邻接点,例如 V4 (做标记),然后 V8 ,然后 V5 ;
- 当继续遍历 V5 的邻接点时,根据之前做的标记显示,所有邻接点都被访问过了。此时,从 V5 回退到 V8 ,看 V8 是否有未被访问过的邻接点,如果没有,继续回退到 V4 , V2 , V1 ;
- 通过查看 V1 ,找到一个未被访问过的顶点 V3 ,继续遍历,然后访问 V3 邻接点 V6 ,然后 V7 ;
- 由于 V7 没有未被访问的邻接点,所有回退到 V6 ,继续回退至 V3 ,最后到达 V1 ,发现没有未被访问的;
- 最后一步需要判断是否所有顶点都被访问,如果还有没被访问的,以未被访问的顶点为第一个顶点,继续依照上边的方式进行遍历。
总结:所谓深度优先搜索,是从图中的一个顶点出发,每次遍历当前访问顶点的临界点,一直到访问的顶点没有未被访问过的临界点为止。然后采用依次回退的方式,查看来的路上每一个顶点是否有其它未被访问的临界点。访问完成后,判断图中的顶点是否已经全部遍历完成,如果没有,以未访问的顶点为起始点,重复上述过程。
上图的遍历次序为:V1 -> V2 -> V4 -> V8 -> V5 -> V3 -> V6 -> V7。
矩阵搜索执行顺序:
- 先执行行(列),一直执行行(列)。
- 直到符合终止条件时,再返回上一节点,检索是否有未被访问到的邻接点,如果有,那一定是列(行),就一直执行列(行)。
- 执行列(行)直到符合终止条件时,再返回上一节点,检索是否有未被访问到的邻接点。
- 重复以上步骤。
编程要点:
- 查全终止条件;
- 在递归函数中设置递归条件。
广度优先搜索:
广度优先搜索类似于树的层次遍历。从图中的某一顶点出发,遍历每一个顶点时,依次遍历其所有的邻接点,然后再从这些邻接点出发,同样依次访问它们的邻接点。按照此过程,直到图中所有被访问过的顶点的邻接点都被访问到。最后还需要做的操作就是查看图中是否存在尚未被访问的顶点,若有,则以该顶点为起始点,重复上述遍历的过程。
假设 V1 作为起始点,遍历其所有的邻接点 V2 和 V3 ,以 V2 为起始点,访问邻接点 V4 和 V5 ,以 V3 为起始点,访问邻接点 V6 、 V7 ,以 V4 为起始点访问 V8 ,以 V5 为起始点,由于 V5 所有的起始点已经全部被访问,所有直接略过, V6 和 V7 也是如此。
V1 -> V2 -> v3 -> V4 -> V5 -> V6 -> V7 -> V8。
递归:
一个很好的例子来说明,求阶乘:
public static int factrial(int n){
if(n<1){
return 1;
}
return n*factrial(n-1);
}
同样功能如下:
public static int factrialDetail(int n){
if(n<1){
System.out.println("拆解问题完毕,开始分而治之");
return 1;
}
System.out.println("f("+n+")="+n+" * f("+(n-1)+")");
int z= n*factrialDetail(n-1);
System.out.println("f("+n+")="+z);
return z;
}
输出如下:
f(5)=5 * f(4)
f(4)=4 * f(3)
f(3)=3 * f(2)
f(2)=2 * f(1)
f(1)=1 * f(0)
拆解问题完毕,开始分而治之
f(1)=1
f(2)=2
f(3)=6
f(4)=24
f(5)=120
递归(Recursion)在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法,其核心思想是分治策略。
从上面的步骤我们可以清晰的看到递归算法的第一步是分治,把复杂的大的问题,给拆分成一个一个小问题,直到不能再拆解,通过退出条件retrun,然后再从最小的问题开始解决,只到所有的子问题解决完毕,那么最终的大问题就迎刃而解。上面的打印信息,符合栈数据结构的定义,先进后出,通过把所有的子问题压栈之后,然后再一个个出栈,从最简单的步骤计算,最终解决大问题,非常形象。
实际运行过程如下图:
第一阶段:
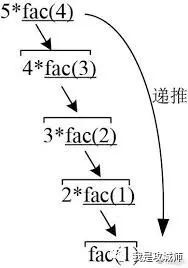
第二阶段:
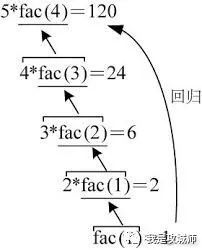
编程要点:
理解难点: 在执行完“递推”操作时(达到终止条件时),直接执行递归语句下面的所有语句直至函数结束,然后执行“回归”过程,再执行递归语句下面的所有语句直至函数结束,直至“回归”过程结束,终止。
总结
递归算法的使用,关键在于如何把大问题给分解成相同类型的子问题,然后对一个一个子问题各自击破,当所有的子问题都解决了,那么大的问题也就解决了。最后,使用递归算法需要记住,一定要有让递归回归的约束条件,这才是正确编写递归的前提。
















 4624
4624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









