







目录
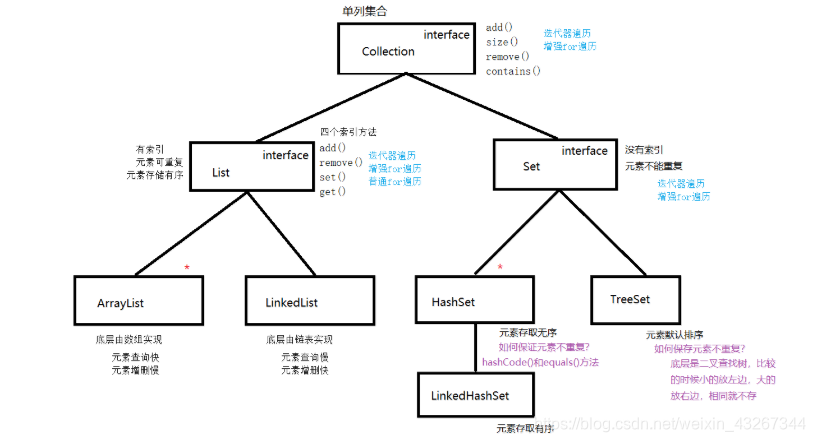
在Java集合中共有两种集合体系,一种是单列集合,一种是双列集合,单列集合的根接口是我们今天学习的Collection接口,而双列集合的根接口是Map接口。
Collection概述:
Collection是一个集合的顶层接口,不能被实例化,并且有多个实现类。
Collection的常用方法:
| 方法 | 说明 |
|---|---|
| boolean add(E e) | 添加方法 |
| void clear()[不用] | 清空集合中的元素 |
| boolean remove(Object e) | 删除集合中的某个元素 |
| boolean contains(Object obj) | 判断集合是否包含某个元素 |
| boolean isEmpty()[不用] | 判断集合是否为空 |
| int size() | 获取集合的长度 |
| Object[] toArray()[不用] | 把集合转成Object[]类型 |
以上既然是Collection的常用方法,那么其实现类也可以使用使用Collection接口中的方法。List和set实现了Collection集合类,那么List和set除了拥有了父类Collection的方法之外,自己还具有一些特有的方法。
List接口及子类
List集合实现了Collection类,在List集合中可以出现重复的元素,并且所有元素都是以一种线性的方式存储的,在程序中通过索引值来访问元素,另外List集合还有一个特点就是元素有序,也就是说存入和取出的顺序一致。
特点:
1)元素存取有序的集合。 2)List是一个带有索引的集合,通过索引值来操作集合中的元素。
3)集合中可以有重复的元素,通过元素的equals方法来比较集合中元素是否为重复的元素。
List集合继承了Collection接口,除了具有Collection中的方法之外,还具有一些特有的方法。如下:
List集合中常用的方法:
| 方法 | 说明 |
|---|---|
| void add(int index, E element) | 在指定的索引添加元素 |
| E get(int index) | 获取指定索引处的元素 |
| E remove(int index) | 删除指定索引处的元素 |
| E set(int index, E element) | 修改指定索引处的元素 |
List方法的代码演示:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test01 {
public static void main(String[] args) {
//创建集合对象(多态)
List<String> list = new ArrayList<>();
list.add("James");
list.add("Tom");
//void add(int index, E element)
//在指定的索引添加元素
list.add(1,"Jerry");
//E get(int index)
//获取指定索引处的元素
String s = list.get(0);
System.out.println(s); //James
//E remove(int index)
//删除指定索引处的元素
list.remove(2);
//E set(int index, E element)
//修改指定索引处的元素
list.set(0,"Tony");
}
}List集具有两个子类:ArrayLlist集合和LinkedList集合(第二种少用,介绍较少)
ArrayList:
Java.util.ArrayList集合是数据存储的结构是数组结构,具有元素增删慢,查找快的特点。在我们日常开发中,使用的最多的功能是查询功能,遍历数据等功能,所以List集合中ArrayList最为常用。
LinkedList:
Java.util.LinkedList集合的数据存储结构是链表结构,具有元素增删快,查找慢的特点。
LinkedList自身具有一些方法
| 方法 | 说明 |
|---|---|
| void addFirst(E e) | 往开头添加元素 |
| void addLast(E e) | 往末尾添加元素 |
| E getFirst() | 获取开头的元素 |
| E getLast() | 获取末尾的元素 |
| E removeFirst() | 删除开头的元素 |
| E removeLast() | 删除末尾的元素 |
| E pop() | 模拟栈的结构,弹出一个元素 |
| void push(E e) | 模拟栈的结构,推入一个元素 |
List小结:
| 集合 | 特点 |
| ArrayList | 元素增删慢,查找快 |
| LinkedList | 元素增删快,查找慢 |
List集合的特点:有索引,元素可重复,元素存储有序
Collection的常用方法:add(),size(),remove(),contains()
List的常用方法:Collection的常用方法、add(int index),remove(int index),set(int index,Element e) ,get(int index);
ArrayList的常用方法:List的常用方法。
LinkedList的常用方法:List的常用方法。
set接口及子类
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,并且set接口没有其他扩充的方法,其添加,删除等方法和其父类Collection的方法基本一样,虽然Set和List都是继承了Collection的接口,但是Set具有不同的特点:
set特点:
1)没有索引
2)存入的元素不出现重复
3)元素存储有序(在哈希表的基础上又额外加了一个链表专门记录存储顺序)
//set集合添加和打印数据
import java.util.LinkedHashSet;
public class Test04 {
public static void main(String[] args) {
//创建对象
LinkedHashSet<Integer> set = new LinkedHashSet<>();
//添加
set.add(123);
set.add(345);
set.add(567);
set.add(111);
set.add(111);
System.out.println(set); //[123, 345, 567, 111]
}
}Set具有HashSet(常用)和TreeSet两个子类
HashSet
HashSet是set接口的一个实现类,java.util.HashSet底层的实现是一个java.util.HashMap支持。HashSet根据对象的哈希值来确定元素在集合中存储的位置,HashSet具有一些特点:
1)没有索引 2)元素不能重复 3)元素存取无序
HashSet的底层数据结构:
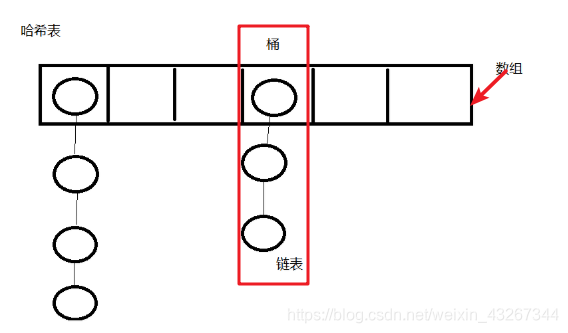
hash值:
Object类中有一个方法hashCode()方法返回的是对象的地址值。每个子类都会重写hashCode()方法,用HashCode()方法返回一个hash值
public class Test02 {
public static void main(String[] args) {
System.out.println("abc".hashCode()); //96354
System.out.println("123".hashCode()); //48690
System.out.println("Aa".hashCode()); //2112 65*31+97
System.out.println("BB".hashCode()); //2112 66*31+66
/*
用"abc"举例:(hash值底层源码计算方式)
int h = 0;
for(int i=0;i<s.length();i++){
h = 31 * h + s.charAt(i);
}
h = 31 * h + 'a' 97
h = 31 * h + 'b' 3105
h = 31 * h + 'c' 96354
*/
}
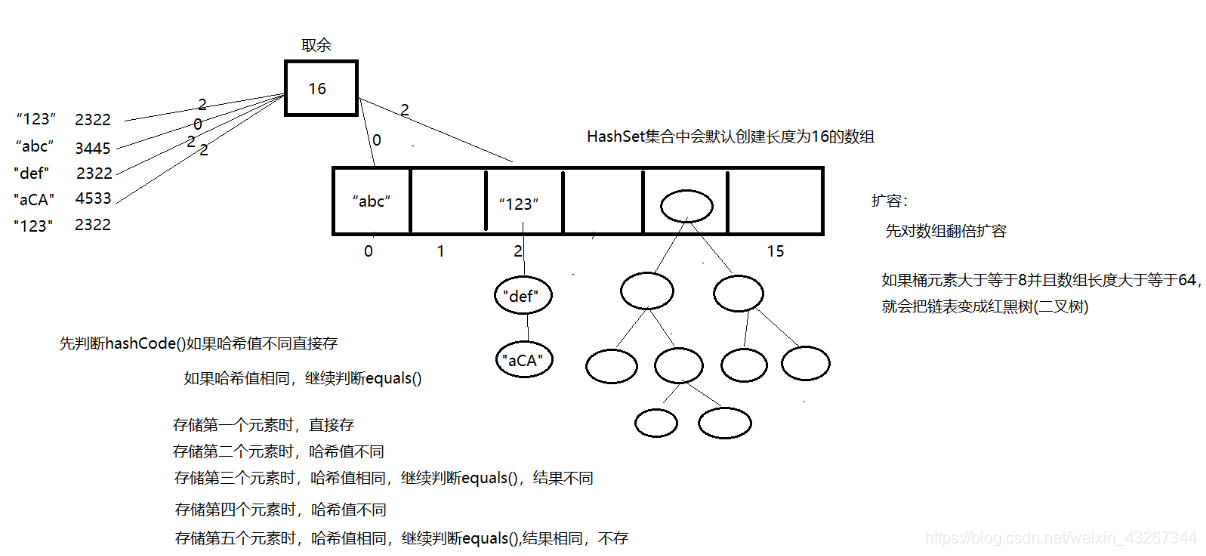
}结论:哈希值不同说明对象一定不同,哈希值相同对象不一定相同
保证元素不重复的源码分析:
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
先调用hashCode()方法判断哈希值是否相同
如果哈希值不同,直接认为元素不重复,就能存储
如果哈希值相同,就调用equals()方法判断对象的内容是否相同
如果内容不相同,就不重复,就能存储
如果内容相同,就重复了,就不存储HashSet的存储图解:
HashSet还有一个子类LinkedHashSet。LinkedHashSet也是根据元素的hashCode值来决定元素的存储位置,但同时使用链表来维护元素的次序,这样使元素看起来是以插入的顺序保存的。
LinkedHashSet集合(了解):
特点:
1)元素没有索引 2)元素不可重复 3)元素存储有序
import java.util.LinkedHashSet;
public class Test04 {
public static void main(String[] args) {
//创建对象
LinkedHashSet<Integer> set = new LinkedHashSet<>();
//添加
set.add(123);
set.add(345);
set.add(567);
set.add(111);
set.add(111);
System.out.println(set); //[123, 345, 567, 111]
}
}TreeSet集合(了解):
特点:
1)没有索引 2)元素不可重复 3)元素自动排序{底层是二叉树查找结构}
import java.util.TreeSet;
public class Test05 {
public static void main(String[] args) {
//创建对象
TreeSet<Integer> set = new TreeSet<>();
//添加
set.add(123);
set.add(345);
set.add(567);
set.add(111);
set.add(111);
System.out.println(set); //[111, 123, 345, 567]
}
}set小结
| 子类 | 特点 |
| HashSet | 无索引,元素不重复,元素存取无序 |
| LinkedHashSet | 无索引,元素不重复,元素存储有序 |
| TreeSet | 无索引,元素不重复,元素默认排序 |
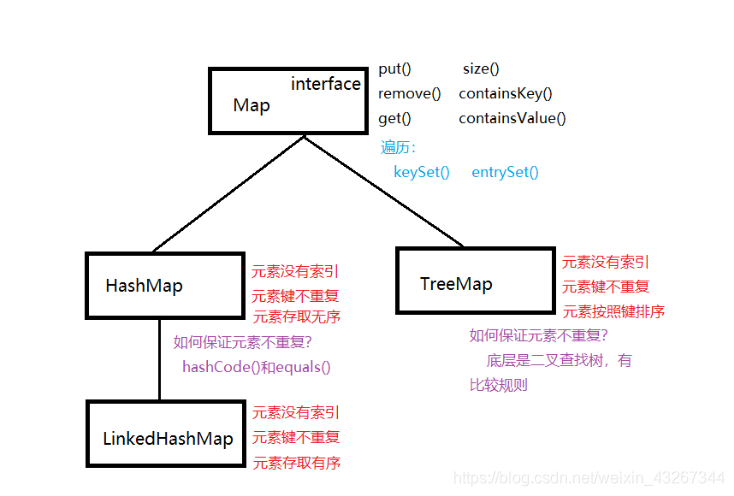
双列Map集合
Map集合的作用:Map集合表示双列集合,用来保存一对一的键值对,也可叫做映射
特点:
1)元素没有索引 2)元素键不重复
| 方法 | 说明 |
|---|---|
| V put(K key, V value) | 添加键值对 |
| V remove(Object key) | 根据键删除对应的键值对 |
| V get(Object key) | 根据键获取值 |
| Set<K> keySet() | 把键转换成Set集合 |
| Set<Map.Entry<K,V>> entrySet() | 把键值对转成Set集合 |
| boolean containsKey(Object key) | 判断是否包含某个键 |
| boolean containsValue(Object value) | 判断是否包含某个值 |
public class MapDemo {
public static void main(String[] args) {
//创建 map对象
HashMap<String, String> map = new HashMap<String, String>();
//添加元素到集合
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
System.out.println(map);
//String remove(String key)
System.out.println(map.remove("邓超"));
System.out.println(map);
System.out.println(map.get("黄晓明"));
System.out.println(map.get("邓超"));
//判断是否存在某键
System.out.println(map.containsKey("文章"))//true;
System.out.println(map.containsKey("马伊琍"))//false
//判断是否存在某值
System.out.println(map.containsValue("文章"))//false;
System.out.println(map.containsValue("马伊琍"))//true
}
}Map的遍历:
两种遍历方式:keySet()键找值得方式和entrySet()键值对的方式。
keySet():键找值的方式:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Test02 {
public static void main(String[] args) {
//创建对象
Map<String,String> map = new HashMap<>();
//添加键值对
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
//把key变成单列集合
Set<String> set = map.keySet();
//增强for
for (String s : set) {
//根据键获取值
String value = map.get(s);
System.out.println(s + " " + value);
}
//快捷键:iter
}
}entrySet()键值对的方式:
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Test03 {
public static void main(String[] args) {
//创建对象
Map<String,String> map = new HashMap<>();
//添加键值对
map.put("黄晓明", "杨颖");
map.put("文章", "马伊琍");
map.put("邓超", "孙俪");
//把键值对变成Set集合
Set<Map.Entry<String, String>> set = map.entrySet();
//增强for
for (Map.Entry<String, String> entry : set) {
//获取键
String key = entry.getKey();
//获取值
String value = entry.getValue();
System.out.println(key + " " +value);
}
}
}Map集合下有两个子类:HashMap(LinkedHashMap)和TreeMap集合。其使用方式和Map的使用方式基本相同,其特点如下:
参考链接:
https://www.cnblogs.com/huze-java/p/11696490.html
https://blog.csdn.net/zfliu96/article/details/83476493#21HashSet_111
https://blog.csdn.net/mashaokang1314/article/details/83721792















 862
862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









