







Spark整理(3)
一,算子
1.1 转换算子
- repartition
增加或减少分区,会产生shuffle
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("Repartition")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3),4)
val result = rdd.repartition(6)
println(result.partitions.length) //输出6个,在控制台可以搜索到shuffle
result.foreach(println)
}
}
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
public class Ja_Repartition {
public static void main(String args[]){
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("zip");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> rdd1 = sc.parallelize(Arrays.asList("i", "love", "you"),3);
JavaRDD<String> rdd = rdd1.repartition(5);
System.out.println(rdd.partitions().size());
rdd.foreach(new VoidFunction<String>() {
@Override
public void call(String s) throws Exception {
System.out.println(s);
}
});
sc.stop();
}
}
- coalesce
常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。
true为产生shuffle, false不产生shuffle. 默认是false
如果coalesce设置的分区数比原来的RDD的分区数还多的话,第二个参数设置为false不会起作用。
coalesce第二个参数如果设置为true,则效果和repartition一样。
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Coalesce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zip")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3),4)
// val rdd1 = rdd.coalesce(2,true) 和repartition效果一致
// val rdd2 = rdd.coalesce(6,false) 增加分区,设置false 也是会产生shuffle
val rdd1 = rdd.coalesce(2)
println(rdd1.partitions.length)
rdd1.foreach(println)
}
}
- groupByKey
作用在K,V格式上的RDD。根据Key进行分组。返回(K,iterable)
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_GroupByKey {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("cache")
val sc = new SparkContext(sparkConf)
val rdd1: RDD[(String, String)] = sc.parallelize(Array(
new Tuple2("a","111"),
new Tuple2("a","222"),
new Tuple2("b","333"),
new Tuple2("b","444"),
new Tuple2("c","555"),
new Tuple2("c","666"),
new Tuple2("d","777")
))
val result: RDD[(String, Iterable[String])] = rdd1.groupByKey(2)
println(result.partitions.length)
result.foreach(x=>{
val list = x._2.toList
list.foreach(y=>{
println(x._1+"------------"+y)
})
})
sc.stop()
}
}
- Zip
将两个RDD中的元素(KV/非KV格式)变成KV格式的RDD,两个RDD的个数必须相同。
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Zip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zip")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array(1,2,3))
val rdd2 = sc.parallelize(Array("a","b","c"))
//rdd1.zip(rdd2).foreach(println)
val rdd3: RDD[(String, String)] = sc.parallelize(Array(
("1","aaa"),
("2","bbb")
))
val rdd4 = sc.parallelize(Array(
(1,2),
(5,10)
))
val result: RDD[((String, String), (Int, Int))] = rdd3.zip(rdd4)
result.foreach(println)
}
}
- zipWithIndex
该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组成KV格式的RDD
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_ZipWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zip")
val sc = new SparkContext(conf)
val rdd3: RDD[(String, String)] = sc.parallelize(Array(
("1","aaa"),
("2","bbb")
),4)
val result: RDD[((String, String), Long)] = rdd3.zipWithIndex()
result.foreach(println)
sc.stop()
}
}
1.2 触发算子
- countByKey
作用到KV格式的RDD上,根据Key计数相同Key的数据集元素
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class Ja_CountByKey {
public static void main(String args[]){
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local").setAppName("intersection");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List<Tuple2<String, Integer>> list = Arrays.asList(
new Tuple2<String, Integer>("a", 111),
new Tuple2<String, Integer>("a", 222),
new Tuple2<String, Integer>("a", 333),
new Tuple2<String, Integer>("b", 55),
new Tuple2<String, Integer>("b", 66),
new Tuple2<String, Integer>("c", 7)
);
JavaPairRDD<String, Integer> javaPairRDD = sc.parallelizePairs(list);
Map<String, Object> map = javaPairRDD.countByKey();
for(String key : map.keySet()){
System.out.println(key+"---->value:"+map.get(key));
}
sc.stop();
}
}
- countByValue
根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class Ja_CountByValue {
public static void main(String args[]){
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local").setAppName("intersection");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
List<Tuple2<String, Integer>> list = Arrays.asList(
new Tuple2<String, Integer>("a", 222),
new Tuple2<String, Integer>("a", 222),
new Tuple2<String, Integer>("a", 222),
new Tuple2<String, Integer>("b", 55),
new Tuple2<String, Integer>("b", 55),
new Tuple2<String, Integer>("c", 7)
);
JavaPairRDD<String, Integer> javaPairRDD = sc.parallelizePairs(list);
Map<Tuple2<String, Integer>, Long> map = javaPairRDD.countByValue();
for(Tuple2 key : map.keySet()){
System.out.println(key+"---->value:"+map.get(key));
}
sc.stop();
}
}
- reduce
根据聚合逻辑聚合数据集中的每个元素
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
object Sp_Reduce {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("union")
val sc = new SparkContext(sparkConf)
val rdd1 = sc.parallelize(Array(1,2,3))
val i: Int = rdd1.reduce(_+_)
println(i)
}
}
二,相关计算案例
2.1 PV,UV
统计网站 pv 和 uv
PV 是网站分析的一个术语,用以衡量网站用户访问的网页的数量。对于广告主,PV 值可预期它可以带来多少广告收入。一般来说,PV 与来访者的数量成正比,但是 PV 并不直接决定页面的真实来访者数量,如同一个来访者通过不断的刷新页面,也可以制造出非常高的 PV。
什么是PV?
PV(page view)即页面浏览量或点击量,是衡量一个网站或网页用户访问量。具体的说,PV 值就是所有访问者在 24 小时(0 点到 24 点)内看了某个网站多少个页面或某个网页多少次。PV 是指页面刷新的次数,每一次页面刷新,就算做一次 PV 流量。度量方法就是从浏览器发出一个对网络服务器的请求(Request),网络服务器接到这个请求后,会将该请求对应的一个网页(Page)发送给浏览器,从而产生了一个 PV。那么在这里只要是这个请求发送给了浏览器,无论这个页面是否完全打开(下载完成),那么都是应当计为 1 个 PV。
什么是UV?
UV(unique visitor)即独立访客数,指访问某个站点或点击某个网页的不同 IP 地址的人数。在同一天内,UV 只记录第一次进入网站的具有独立IP 的访问者,在同一天内再次访问该网站则不计数。UV 提供了一定时间内不同观众数量的统计指标,而没有反应出网站的全面活动.
准备数据,数据格式如下:

- 统计网站PV
1.读取文件数据
2.取出文件中的url,映射关系为-> <url,1>
3.相同key聚合数量,按照数量排序输出即可
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class Ja_PV {
public static void main(String args[]){
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("zip");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> linesRDD = sc.textFile("./data/pvuvdata");
JavaPairRDD<String, Integer> mapRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s.split("\t")[5], 1);
}
});
JavaPairRDD<String, Integer> reduceRDD = mapRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
reduceRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple2) throws Exception {
System.out.println(tuple2);
}
});
sc.stop();
}
}
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_PV {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("union")
val sc = new SparkContext(sparkConf)
//读取数据
val linesRDD: RDD[String] = sc.textFile("./data/pvuvdata")
//转化数据集格式
val mapRDD: RDD[(String, Int)] = linesRDD.map(x=>{
Tuple2(x.split("\t")(5),1)
})
//聚合排序,遍历输出
mapRDD.reduceByKey(_+_).sortBy(x=>x._2,false).foreach(println)
sc.stop()
}
}
- UV
1.读取文件数据
2.取出文件中的url和ip,映射关系为-> <url,Ip>
3.根据key分组,聚合Ip,对ip去重,取数量即为UV
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Collections;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Ja_UV {
public static void main(String args[]){
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("zip");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> linesRDD = sc.textFile("./data/pvuvdata");
JavaPairRDD<String, String> mapRDD = linesRDD.mapToPair(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s) throws Exception {
return new Tuple2<>(s.split("\t")[5], s.split("\t")[0]);
}
});
mapRDD.groupByKey().foreach(new VoidFunction<Tuple2<String, Iterable<String>>>() {
@Override
public void call(Tuple2<String, Iterable<String>> tuple2) throws Exception {
Iterator<String> iterator = tuple2._2().iterator();
Set set = new HashSet();
while (iterator.hasNext()){
set.add(iterator.next());
}
System.out.println(tuple2._1 +"=========="+set.size());
}
});
}
}
scala代码:
package com.shsxt.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Sp_UV {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setMaster("local").setAppName("union")
val sc = new SparkContext(sparkConf)
val linesRDD: RDD[String] = sc.textFile("./data/pvuvdata")
// val countRDD = linesRDD.map(x=>{
// Tuple2(x.split("\t")(5),x.split("\t")(0))
// }).distinct().map(x=>(x._1,1)).countByKey()
//
// countRDD.foreach(println)
val result: RDD[(String, Iterable[String])] = linesRDD.map(x => {
val fields = x.split("\t")
(fields(5), fields(0))
}).groupByKey()
result.foreach(x => {
val key = x._1
val iteratable = x._2
println("key : " + key + " size : " + iteratable.toSet.size)
})
}
}
2.2 二次排序
对于一些数据,默认的排序后无法满足我们所需要的结果,这时候我们可以自定义排序规则来实现,这就叫二次排序(自定义key)。
数据格式:

自定义排序key的java类
SecondSortKey.java
package com.shsxt.spark.java;
import java.io.Serializable;
//和MapReduce的两次排序一样,自定义排序类 需要实现 序列化接口和 Comparable比较器
public class SecondSortKey implements Serializable,Comparable<SecondSortKey> {
private Integer first;
private Integer second;
public SecondSortKey(Integer first,Integer second){
this.first = first;
this.second = second;
}
public int getFirst() {
return first;
}
public void setFirst(int first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
//最重要的是这个方法
@Override
public int compareTo(SecondSortKey o) {
//第一个相同,比较第二个数字的大小
if (this.getFirst()==o.getFirst()){
return this.getSecond()-o.getSecond();
}else {
return this.getFirst()-o.getFirst();
}
}
}
java代码:
package com.shsxt.spark.java;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class Ja_SecondSort {
public static void main(String args[]){
SparkConf conf = new SparkConf();
conf.setMaster("local").setAppName("secondSort");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> linesRDD = sc.textFile("./data/secondSort.txt");
JavaPairRDD<SecondSortKey, Integer> pairRDD = linesRDD.mapToPair(new PairFunction<String, SecondSortKey, Integer>() {
@Override
public Tuple2<SecondSortKey, Integer> call(String s) throws Exception {
Integer first = Integer.valueOf(s.split(" ")[0]);
Integer second = Integer.valueOf(s.split(" ")[1]);
//构建 KV形式的 数据集 框架运行时会自动调用 自动Key中的排序方法 compareTo
Tuple2<SecondSortKey, Integer> tuple2 = new Tuple2<>(new SecondSortKey(first, second), 1);
return tuple2;
}
});
pairRDD.sortByKey(false).foreach(new VoidFunction<Tuple2<SecondSortKey, Integer>>() {
@Override
public void call(Tuple2<SecondSortKey, Integer> tuple2) throws Exception {
System.out.println(tuple2._1.getFirst()+"----"+tuple2._1.getSecond());
}
});
}
}
scala代码:
package com.shsxt.spark.scala
import com.shsxt.spark.java.SecondSortKey
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Sp_SecondSort {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("secondSort")
val sc = new SparkContext(conf)
val linesRDD = sc.textFile("./data/secondSort.txt")
// val rdd1 = sc.parallelize(Array(1,2,3))
//
// //rdd1.sortBy()
// val rdd2: RDD[(Int, Int)] = rdd1.map(x=>(x,1))
//
rdd2.sortBy()
linesRDD.map(x=>{
new Tuple2(new SecondSortKey(Integer.valueOf(x.split(" ")(0)),Integer.valueOf(x.split(" ")(1))),1)
}).sortByKey(false).foreach(x=>{
println(x._1.getFirst+"----"+x._1.getSecond)
})
}
}
2.3 分组取topN
数据如下:

1.读取数据
2.处理数据,KV形式的数据
3.按照key分组,取每组前三个分数最高的
java代码:
package com.shsxt.spark.java;
import org.apache.commons.collections.IteratorUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
public class Ja_TopN {
public static void main(String args[]){
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local").setAppName("topN");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaRDD<String> linesRDD = sc.textFile("./data/scores.txt");
JavaPairRDD<String, Integer> pairRDD = linesRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
String s1 = s.split(" ")[0];
Integer s2 = Integer.valueOf(s.split(" ")[1]);
return new Tuple2<>(s1, s2);
}
});
JavaPairRDD<String, Iterable<Integer>> groupRDD = pairRDD.groupByKey();
//这种方式将数据全部放入list中,数据量大,可能造成内存OOM
// groupRDD.foreach(new VoidFunction<Tuple2<String, Iterable<Integer>>>() {
// @Override
// public void call(Tuple2<String, Iterable<Integer>> it) throws Exception {
// Iterator<Integer> iterator = it._2.iterator();
// List list = IteratorUtils.toList(iterator);
// Collections.sort(list);
//
// for (int i = 0; i < Math.min(3,list.size()); i++) {
// System.out.println(it._1+"----"+list.get(list.size()-i-1));
// }
// }
// });
//这种方式较好,每次对一条数据拿取,再排序
groupRDD.foreach(new VoidFunction<Tuple2<String, Iterable<Integer>>>() {
@Override
public void call(Tuple2<String, Iterable<Integer>> it) throws Exception {
String key = it._1;
Iterator<Integer> iterator = it._2.iterator();
Integer [] top3 = new Integer[3];
while (iterator.hasNext()){
Integer score = iterator.next();
for (int i = 0; i <top3.length; i++) {
if (top3[i]==null){
top3[i]=score;
break;
}else if (score>top3[i]){
for (int j = 2; j >i ; j--) {
top3[j] = top3[j-1];
}
top3[i] = score;
break;
}
}
}
for(Integer score : top3){
if (score!=null){
System.out.println(key+"---value:"+score);
}
}
}
});
}
}
scala代码
package com.shsxt.spark.scala
import org.apache.spark.{SparkConf, SparkContext}
object Sp_TopN {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("topN")
val sc = new SparkContext(conf)
val lineRDD = sc.textFile("./data/scores.txt")
val groupRDD = lineRDD.map(x=> {
new Tuple2(x.split(" ")(0), Integer.valueOf(x.split(" ")(1)))
}).groupByKey()
groupRDD.foreach(x=>{
val key = x._1
val it: Iterator[Integer] = x._2.iterator
val arr: Array[Integer] = new Array[Integer](3)
// println(arr.length)
// println("===================")
while(it.hasNext){
var score = it.next()
var falg = true
for (i<- 0 until arr.length;if falg==true){
if (arr(i)==null){
arr(i) = score
falg=false
}else if (score>arr(i)){
var j = 2
while(j>i){
arr(j)=arr(j-1)
j = j-1
}
arr(i)=score
falg=false
}
}
}
arr.foreach(x=>{
if (x!=null){
println(key+"--------value"+x)
}
})
})
}
}
三,Spark-Submit提交参数
Options
- master
Master_URL,可以是 spark://host:port , mesos://host:port , yarn , yarn-cluster , yarn-client , local
- –deploy-mode
Deploy_Mode,Driver程序运行的地方,client或者cluster,默认是client
- –class
CLASS_NAME 主类名称,含包名
- –jars
逗号分隔的本地JARS,Driver和exector依赖的第三方jar包
- –files
用逗号隔开的文件列表,放置在每个exector工作目录中
- –conf
spark的配置属性
- –driver-memory
Driver程序使用内存大小(例如: 1000M , 5G) ,默认1024M
- –exector-memory
每个exector内存大小(如:1000M,2G),默认1G
Spark standalone with cluster deploy mode only:
- –driver-cores
Driver程序的使用core个数(默认为1),仅限于Spark standalone模式
Spark standalone or Mesos with cluster deploy mode only
- –supervise
失败后是否重启Driver,仅限于Spark alone 或者 Mesos模式
Spark standalone and Mesos only
- –total-exector-cores
exector使用的总核数,仅限于Standalone Mesos模式
Spark standalone and yarn only
- –exector-cores
每个exector使用的core数,Spark on yarn默认为1,standalone默认为worker上所有可用的core数
Yarn only
- –driver-cores
driver使用的core,仅在cluster模式下,默认为1
- –queue
QUEUE_NAME 指定资源队列的名称 默认:default
- –num-exectors
一共启动的exector数量,默认是2个。
四,Spark shell
4.1 概念
SparkShell 是 Spark 自带的一个快速原型开发工具,也可以说是Spark 的 scala REPL(Read-Eval-Print-Loop),即交互式 shell。支持使用 scala 语言来进行 Spark 的交互式编程。
4.2 使用
启动standalone集群, ./start-all.sh
在客户端启动 spark-shell
./spark-shell --master spark://node01:7077
启动 hdfs,创建目录 spark/test,上传文件 wc.txt
启动hdfs集群: start-all.sh
创建目录: hdfs dfs -mkdir /spark
上传数据: wc.txt
运行wordCount
sc.textFile("hdfs://node01:8020/spark/wc.txt")
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
五,SparkUI
5.1 SparkUI界面介绍
可以指定提交Application的名称
./spark-shell --master spark://node01:7077 --name myapp
5.2 配置historyServer
- 临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node01:7077
--name myapp1
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://node01:8020/spark
停止程序,在 Web Ui 中 Completed Applications 对应的ApplicationID 中能查看 history
- 永久配置
在客户端节点,进入conf目录下 spark-default.conf中 最后加入:
//开启记录事件日志的功能
spark.eventLog.enabled true
//设置事件日志存储的目录
spark.eventLog.dir hdfs://node01:8020/spark
//设置 HistoryServer 加载事件日志的位置
spark.history.fs.logDirectory hdfs://node01:8020/spark
- 启动HistoryServer
sbin目录下 ./start-history-server.sh
访问 HistoryServer:node01:18080,之后所有提交的应用程序运行状况都会被记录。
六,Master HA
6.1 Master的高可用原理
Standalone 集群只有一个 Master,如果 Master 挂了就无法提交应用程序,需要给 Master 进行高可用配置,Master 的高可用可以使用**fileSystem(文件系统)**和 zookeeper(分布式协调服务)。
- fileSystem
fileSystem 只有存储功能,可以存储 Master 的元数据信息,用fileSystem 搭建的 Master 高可用,在 Master 失败时,需要我们手动启动另外的备用 Master,这种方式不推荐使用。
- zookeeper
zookeeper 有选举和存储功能,可以存储 Master 的元素据信息,使用zookeeper 搭建的 Master 高可用,当 Master 挂掉时,备用的 Master会自动切换,推荐使用这种方式搭建 Master 的 HA。

6.2 Master高可用搭建
-
在Spark Master节点上配置主Master,配置spark-env.sh
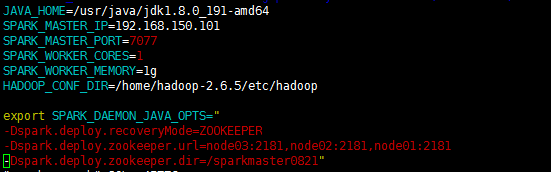
-
发送到其他worker节点上
scp spark-env.sh node02:`pwd`
- 找一台节点(非主Master节点)配置备用Master,修改spark-env.sh 配置节点的MasterIP
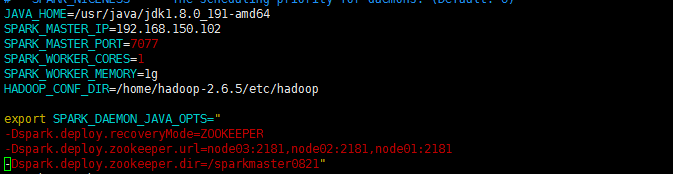
我这边是node02,节点的ip为 192.168.150.102
- 启动集群之间启动zookeeper集群
zkServer.sh start
- 启动spark standalone集群,启动备用Master(在备用节点输入命令)
主节点sbin目录下: ./start-all.sh
备用节点sbin目录下: ./start-master.sh
-
查看WEB页面的从主状态
-
注意
1.主备切换过程中不能提交Application
2.主备切换过程中不影响已经在集群中运行的Application。因为Spark是组粒度申请资源
- 测试HA
kill掉主的Master,观察备用Master是否切换状态到Active状态(切换速度比HDFS的HA慢)















 6366
6366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









