






 博客介绍了机器学习相关内容,包括从官网、kaggle或飞桨社区下载数据集,给出特征数据文件下载链接。还提及所需工具包,重点阐述数据处理,将步骤模块化,包含读取、整合数据,清除无效值,统计标签类别等,因台式机内存问题建议放远程服务器处理。
博客介绍了机器学习相关内容,包括从官网、kaggle或飞桨社区下载数据集,给出特征数据文件下载链接。还提及所需工具包,重点阐述数据处理,将步骤模块化,包含读取、整合数据,清除无效值,统计标签类别等,因台式机内存问题建议放远程服务器处理。
1. 数据集下载
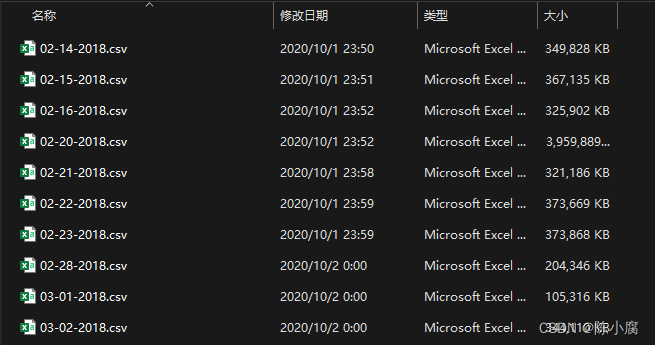
具体过程略过,从官网或kaggle等渠道下载。全部数据集包含pcap文件和特征数据文件,官网下载可能会很慢,因为暂且用不到pcap文件,笔者直接从飞桨社区下载了特征数据文件,包含10个不同日期的csv文件,下载链接贴给大家。
数据集地址 :https://aistudio.baidu.com/datasetdetail/60692
2. 需要用到的工具包
import csv
import pandas as pd
import numpy as np
3. 数据处理
笔者参考了其他作者的处理思路,将步骤模块化,方便理解和使用。在处理数据前,我自己先查看了这些csv文件的表头并对应官网给的释义,将其记录在一个head表格中。具体方法如下:
''' Record CSV heads, features of those traffic '''
def record_csv():
with open((data_path+'02-14-2018.csv'), 'r') as f:
reader = csv.reader(f)
print(type(reader))
result = list(reader)
print(result[0])
df = pd.DataFrame(result[0], columns=['Column Name'])
df.to_excel(data_path+'heads.xlsx')
print('----------Save DONE-----------')
f.close()
读取数据
Step 1:定义路径,以及处理结果所保存的文件名。
# Change your data path here
data_path = 'D://datasets//CICIDS2018//'
file_name = 'total.csv'
Step 2:读取数据为dataFrame,并将数据整合。
''' Write Data '''
def write_csv(path):
print('Loading csv file: '+path)
data = pd.read_csv(path, header=None, low_memory=False)
return data
''' Get Data '''
def get_data():
f1 = data_path+'02-14-2018.csv'
fr1= write_csv(f1).drop([0])
f2 = data_path+'02-15-2018.csv'
fr2= write_csv(f2).drop([0])
f3 = data_path+'02-16-2018.csv'
fr3= write_csv(f3).drop([0])
f4 = data_path+'02-20-2018.csv'
fr4= write_csv(f4).drop([0])
f5 = data_path+'02-21-2018.csv'
fr5= write_csv(f5).drop([0])
f6 = data_path+'02-22-2018.csv'
fr6= write_csv(f6).drop([0])
f7 = data_path+'02-23-2018.csv'
fr7= write_csv(f7).drop([0])
f8 = data_path+'02-28-2018.csv'
fr8= write_csv(f8).drop([0])
f9 = data_path+'03-01-2018.csv'
fr9= write_csv(f9).drop([0])
f10 = data_path+'03-02-2018.csv'
fr10= write_csv(f10).drop([0])
data_frame = [fr1, fr2, fr3, fr4, fr5, fr6, fr7, fr8, fr9, fr10]
return data_frame
整合数据
清除数据中的Nan和Infinity值,将数据写入csv文件。
''' Merge data '''
def merge_data(data_frame):
data = pd.concat(data_frame, ignore_index=True)
# clear Nan and Infinity
data = data[~data.isin([np.nan, np.inf, -np.inf]).any(axis=1)].dropna()
return data
''' Merge data into total.csv '''
def merge_csv():
data_frame = get_data()
data = merge_data(data_frame)
file = data_path+file_name
data.to_csv(file, index=False, header=False)
print('----------Total CSV Save Done---------')
统计标签类别
由于自己在实现过程中发现整合的数据结果有包含无意义的数据(统计标签时发现了标签为Label的行,这些行的内容是表头),因此,笔者多加了一行代码删除这些数据。
''' Count Labels '''
def count_labels():
raw_data = pd.read_csv(data_path+file_name, header=None, low_memory=False)
index_num = raw_data.shape[1]-1
# There are "Headers" in data, delete these data
raw_data = raw_data.drop(raw_data[raw_data[index_num] == 'Label'].index, axis=0)
print(raw_data[index_num].value_counts())
运行
''' Main Program '''
merge_csv()
count_labels()
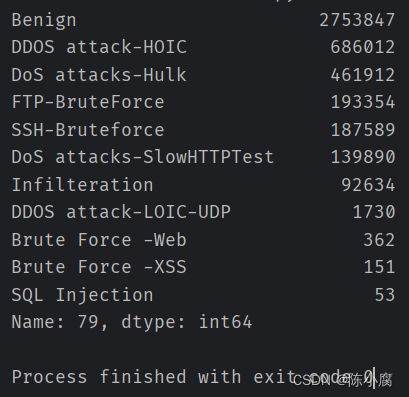
运行结果如下。由于实验室台式机内存不够,直接处理10个文件还是太吃力了hhh。
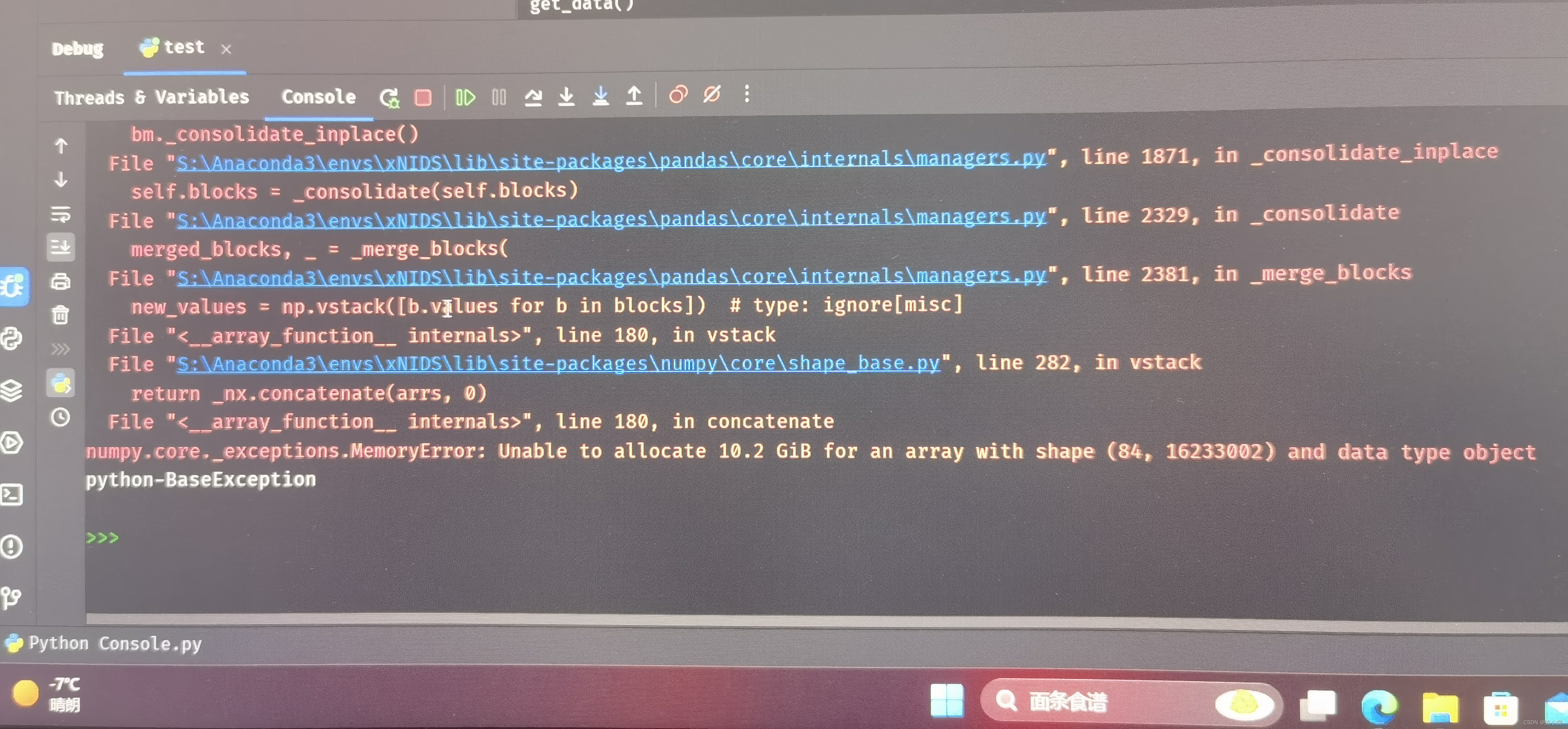
笔者只使用5个文件先进行了调试,统计的类别是不全的,大家还是要放到远程服务器去处理~
参考博客:
[1] https://blog.csdn.net/u013698706/article/details/106422480
[2] https://blog.csdn.net/yuangan1529/article/details/115024175

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









