







- 哈希表基础

使用O(1)的查找操作
一、将元素转换为索引的函数叫作哈希函数, 如 f(ch)=ch-‘a’,接下来在哈希表上进行操作即可
注意,这种转换是一一对应的转换,将“键”转换为“索引”
如:一个班的学生学号:1~30
其中字符串、浮点数、日期都可以做键,需要找到合适的哈希函数保证一一对应
但是很难保证每一个“键”通过哈希函数的转换对应不同的“索引”——哈希冲突
但是有些情况不行,比如 身份证号-610404199009121314 18位数做数组?
所以,做哈希表最关键的两个问题就是,如何设计哈希函数,如何解决哈希冲突
哈希表充分体现了算法设计领域的经典思想:空间换时间
如果我们有n的空间,可以用O(1)时间完成各项操作
如果我们有1的空间,只能用O(n)时间完成各项操作(线性表)
哈希表是时间和空间之间的平衡
哈希函数的设计是很重要的
二、哈希函数的设计
“键”通过哈希函数得到的“索引”分布越均匀越好
对于一些特殊领域,有特殊领域的哈希函数设计方式,甚至有专门的论文
我们只关注一般的哈希函数的设计
1.整型:
小范围正整数直接使用
小范围负整数进行偏移 -100~100 => 0~200
大整数进行取模(有局限,分布不均,没有利用所有信息,增加哈希冲突)
比如 身份证号 610404199009121314 取后四位,等同于 mod 10000 =>1314
取后六位,等同于 mod 1000000 => 121314 分布不均匀
 2.浮点型:
2.浮点型:
转成整型处理
在计算机中都是32为或者64为的二进制展示,只不过计算机解析成了浮点数
3.字符串:
转成整型处理
166=1 *10^2 + 6 *10^1 + 6 *10^0
code=c *26^3 + o *26^2 + d *26^1 + e *26^0
code=c *B^3 + o *B^2 + d *B^1 + e *B^0
hash(code)=(c *B^3 + o *B^2 + d *B^1 + e *B^0)%M
数学优化
hash(code)=( ( ( ( c * B ) + o ) * B+d ) * B + e ) % M
可能整型溢出
hash(code)=( ( ( ( c % M ) * B + o ) % M * B+d ) % M * B + e ) % M
int hash=0; //初始化哈希函数为0
int B; int M;
for(int i=0;i<s.length();i++){
hash=(hash*B+s.charAt(i))%M;
}
4.复合类型:
转成整型处理
Date:year,month,day
hash(date)=( ( ( date.year % M ) * B + date.month ) % M * B + date.day ) % M
转成整型处理,并不是唯一的方法!
5.原则
<1>一致性:如果a==b,则hash(a)==hash(b)
<2>高效性:计算高效简便
<3>均匀性:哈希值均匀分布
三、Java中的hashCode
- Object中的hashCode
public native int hashCode();
任何子类的hashCode函数都继承自Object;
在子类没有重写该函数之时,子类的哈希值由Object的hashCode函数计算
该函数默认将对象的物理内存地址当做哈希值;
2.基本数据类型中的hashCode
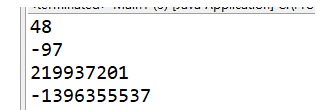
int a=48;//对于整型来说,值为多少,hashCode()返回的值就是多少
System.out.println(((Integer)a).hashCode());//包装类,强制类型转换
int b=-97;
System.out.println(((Integer)b).hashCode());
double p=3.1415926;
System.out.println(((Double)p).hashCode());
String s="banada";
System.out.println(s.hashCode());
实验结果:
3**.String类中的hashCode**
重写了Object的hashCode,为什么没有%M
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
4.自定义类中的hashCode()
重写hashCode()和equals()===
package org.yanan.哈希表;
public class Student {
private int grade;
private int cla;
private String firstName;
private String lastName;
public Student(int grade, int cla, String firstName, String lastName) {
super();
this.grade = grade;
this.cla = cla;
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public int hashCode() {//虽然是整型计算,结果可能可能会溢出,计算结果
int B=31;//可能不是两数相加的数学结果,不同语言对溢出的操作不同,但值会被返回
int hash=0;
hash=hash*B+grade;
hash=hash*B+cla;
hash=hash*B+firstName.toUpperCase().hashCode();
hash=hash*B+lastName.toUpperCase().hashCode();
return hash;
}
@Override
public boolean equals(Object obj) {
if(this==obj){//自己和自己比
return true;
}
if(obj==null){
return false;
}
if(getClass()!=obj.getClass()){
return false;
}
//强转后一个一个成员变量的比
Student another=(Student) obj;
return this.grade==another.grade &&this.cla==another.cla
&&this.firstName.toUpperCase().equals(another.firstName.toUpperCase())
&&this.lastName.toUpperCase().equals(another.lastName.toUpperCase());
}
}
四、Java中的哈希表
Java中自带HashSet集合和HashTable映射
hashCode()函数只能计算出元素对应在哈希表中的索引,但是正如上文所述,不同的元素也可能计算出相同的索 引,那么怎么处理呢?
Student s1=new Student(3, 2, “xixi”);
Student s2=new Student(3, 2, “xixi”);
如代码所示,s1和s2都是3年级2班的名称为"xiix"的学生,如果不重写Student类的hashCode函数的话,默认使用Object的,就用对象的地址作为哈希值,那么,s1和s2是两个对象,其地址肯定不同,所以哈希值也不同,则两者都能存入到哈希表中
但是,如果从业务逻辑考虑的话,年级相同,班级相同,姓名也相同的话,表示同一个人,那么此时s1和s2虽然是两个对象,却也是业务中的同一人,但是也能存在哈希表中,这样子不符合逻辑
如何处理呢? 这就是哈希冲突,
目前解决的思路是: 如果哈希值相同,就比较内容,如何比较内容,就需要重写equals方法,
内容相同,意味着两个对象计算的哈希值一样,且内容一样,表示同一人,哈希表不存s2 ;
内容不相同,意味着两个对象计算的哈希值一样 但内容不一样,表示两个人 哈希表存s2。
- Java中自带的哈希表,计算步骤
所以,对于Java中自带的哈希表,计算步骤如下
<1>. 先调用对象的hashCode计算哈希值
<2> 通过哈希值寻表中的位置
<3>. 如果该位置中没有元素,则直接存入
<4>. 如果该位置中已有元素,则调用后者的equals和已存在元素进行比较
a. 内容相同,后者不存如
b. 内容不同,后者存入(链地址法 )
3.哈希冲突的处理:链地址法(Seperate Chaining)
哈希表的本质就是一个数组,一个位置如果存多个元素怎么办?链表挂接

- TreeMap实现的哈希表、哈希表的时间复杂度分析和动态空间处理
package org.yanan.哈希表;
import java.util.TreeMap;
public class HashTable<K,V> {//哈希表底层就看做是一个红黑树实现的,但K不用继承Comparable,只要实现hashCode()
//在java中所有类都是Object子类,Object默认实现了hashCode()方法
private static final int[] capacity={53,97,193,389,//2倍的扩容可能会导致哈希值分布不均,2*M不是素数,创建素数表
769,1543,3079,6151,12289,24593,
49157,98317,196613,393241,768433,1572869,3145739,6291469,
12582917,25165843,50331653,100663319,201326611,402653189,
805306457,1610612741 };
private static final int upperTol=10;//设置平均每个地址哈希冲突的上界,平均每个地址元素数超过上界,扩容
private static final int lowerTol=2;//设置平均每个地址哈希冲突的下界,每个地址元素数小于下界,缩容
private int capacityIndex=0;//指向数组下标的索引
private TreeMap<K,V>[] hashtable;//定义一个红黑树数组,数组中存放的也是键值形式的数据
//由于M是用户指定货默认的,不会改变,所以哈希表整体时间复杂度不会是O(1)级别,
private int M;//哈希表的长度,即选择一个合适的长度
private int size;//哈希表中存储了多少个元素
//1.定义构造函数
public HashTable(){//用户可传入一个指定大小的哈希表
this.M=capacity[capacityIndex];
size=0;
hashtable=new TreeMap[M];//初始化数组,有M个TreeMap
for(int i=0;i<hashtable.length;i++){
//实例化每一个TreeMap
hashtable[i]=new TreeMap<>();
}
}
/*//传入一个无参的构造函数
public HashTable(){
this(initCapacity);//默认给一个哈希表的长度
}*/
//2.定义一个辅助函数,寻找任意传入的key的索引(哈希值)
private int hash(K key){//将key转成当前的哈希表中所对应的索引值
return (key.hashCode()&0x7fffffff) % M;//消除整型的负号,再对M取模
}
//3.获取哈希表中元素的个数
public int getSize(){
return size;
}
//4.添加一个键值对
public void add(K key,V value){
int index=hash(key);//先找到key所对应的索引
TreeMap<K,V> map=hashtable[index];//根据索引找到数组中对应的TreeMap
if(map.containsKey(key)){//判断数组中是否包含该key
map.put(key, value);
}else{
map.put(key, value);
size++;
}
if(size>=upperTol*M && capacityIndex+1<capacity.length){//upperTol=N/M
//扩容,避免整型向浮点型转化,用乘法运算,扩容时防止数组下标越界
capacityIndex++;
resize(capacity[capacityIndex]);
}
}
//5.删除键
public V remove(K key){
TreeMap<K,V> map=hashtable[hash(key)];
V res=null;
if(map.containsKey(key)){
res=map.remove(key);
size--;
if(size<lowerTol*M && capacityIndex-1>=0){//缩容时注意边界,防止越界
capacityIndex--;
resize(capacity[capacityIndex]);
}
}
return res;
}
private void resize(int newM) {
TreeMap<K,V>[] newhashtable=new TreeMap[newM];//创建新数组并初始化
//实例化新数组
for(int i=0;i<newhashtable.length;i++){
newhashtable[i]=new TreeMap<>();
}
int oldM=M;
M=newM;
//将原先hashtable中的内容放入newhashtable中
for(int i=0;i<oldM;i++){
//newhashtable[i]=hashtable[i];
TreeMap<K,V> map=hashtable[i];
//遍历map中的每一个元素,即从map.keySet()中遍历每一个键
for(K key:map.keySet()){
//将每个key及对应的value重新放入newhashtable中
newhashtable[hash(key)].put(key, map.get(key));
//但此时hash()中调用的M应该是newM
}
}
hashtable=newhashtable;
}
//6.修改
public void set(K key,V value){
TreeMap<K,V> map=hashtable[hash(key)];
if(!map.containsKey(key)){
throw new IllegalArgumentException("key not exist");
}
map.put(key, value);
}
//7.查询:是否包含key
public boolean contains(K key){
TreeMap<K,V> map=hashtable[hash(key)];
return map.containsKey(key);
}
//8.查询:根据key得到value
public V get(K key){
int index=hash(key);
TreeMap<K,V> map=hashtable[index];
return map.get(key);
}
}
总结: 哈希表时间复杂度下来了(均摊复杂度O(1)),牺牲了什么?顺序性
那么至此,集合和映射可以用线性表,平衡树,哈希表实现,线性表就不考虑了
有序集合,有序映射,红黑树实现,TreeSet,TreeMap
无序集合,无序映射,哈希表,HashSet,HashMap/HashTable
更多处理哈希冲突的方法:
1.开放地址法Open Addressing
线性探测法,遇到哈希冲突 +1
平方探测,遇到哈希冲突+1 +4 +9 +16
二次哈希法 +hash2(key)
开放地址法也有可能将数组占满,也需要扩容,与负载率有关
2.再哈希法 Rehashing 重新计算hash值
3.Colasced Hashing 融合了链地址法和开放地址发
- 哈希表的动态素数空间实现
package org.yanan.哈希表;
import java.util.TreeMap;
public class HashTable<K,V> {//哈希表底层就看做是一个红黑树实现的,但K不用继承Comparable,只要实现hashCode()
//在java中所有类都是Object子类,Object默认实现了hashCode()方法
private static final int[] capacity={53,97,193,389,
769,1543,3079,6151,12289,24593,
49157,98317,196613,393241,768433,1572869,3145739,6291469,
12582917,25165843,50331653,100663319,201326611,402653189,
805306457,1610612741 };
private static final int upperTol=10;//设置平均每个地址哈希冲突的上界,平均每个地址元素数超过上界,扩容
private static final int lowerTol=2;//设置平均每个地址哈希冲突的下界,每个地址元素数小于下界,缩容
private int capacityIndex=0;
private TreeMap<K,V>[] hashtable;//定义一个红黑树数组,数组中存放的也是键值形式的数据
//由于M是用户指定或默认的,不会改变,所以哈希表整体时间复杂度不会是O(1)级别,
private int M;//哈希表的长度,即选择一个合适的长度
private int size;//哈希表中存储了多少个元素
//1.定义构造函数
public HashTable(){//用户可传入一个指定大小的哈希表
this.M=capacity[capacityIndex];
size=0;
hashtable=new TreeMap[M];//初始化数组,有M个TreeMap
for(int i=0;i<hashtable.length;i++){
//实例化每一个TreeMap
hashtable[i]=new TreeMap<>();
}
}
/*//传入一个无参的构造函数
public HashTable(){
this(initCapacity);//默认给一个哈希表的长度
}*/
//2.定义一个辅助函数,寻找任意传入的key的索引(哈希值)
private int hash(K key){//将key转成当前的哈希表中所对应的索引值
return (key.hashCode()&0x7fffffff) % M;//消除整型的负号,再对M取模
}
//3.获取哈希表中元素的个数
public int getSize(){
return size;
}
//4.添加一个键值对
public void add(K key,V value){
int index=hash(key);//先找到key所对应的索引
TreeMap<K,V> map=hashtable[index];//根据索引找到数组中对应的TreeMap
if(map.containsKey(key)){//判断数组中是否包含该key
map.put(key, value);
}else{
map.put(key, value);
size++;
}
if(size>=upperTol*M && capacityIndex+1<capacity.length){//upperTol=N/M
//扩容,避免整型向浮点型转化,用乘法运算
capacityIndex++;
resize(capacity[capacityIndex]);
}
}
//5.删除键
public V remove(K key){
TreeMap<K,V> map=hashtable[hash(key)];
V res=null;
if(map.containsKey(key)){
res=map.remove(key);
size--;
if(size<lowerTol*M && capacityIndex-1>=0){//缩容时注意边界
capacityIndex--;
resize(capacity[capacityIndex]);
}
}
return res;
}
private void resize(int newM) {
TreeMap<K,V>[] newhashtable=new TreeMap[newM];//创建新数组并初始化
//实例化新数组
for(int i=0;i<newhashtable.length;i++){
newhashtable[i]=new TreeMap<>();
}
int oldM=M;
M=newM;
//将原先hashtable中的内容放入newhashtable中
for(int i=0;i<oldM;i++){
//newhashtable[i]=hashtable[i];
TreeMap<K,V> map=hashtable[i];
//遍历map中的每一个元素,即从map.keySet()中遍历每一个键
for(K key:map.keySet()){
//将每个key及对应的value重新放入newhashtable中
newhashtable[hash(key)].put(key, map.get(key));
//但此时hash()中调用的M应该是newM
}
}
hashtable=newhashtable;
}
//6.修改
public void set(K key,V value){
TreeMap<K,V> map=hashtable[hash(key)];
if(!map.containsKey(key)){
throw new IllegalArgumentException("key not exist");
}
map.put(key, value);
}
//7.查询:是否包含key
public boolean contains(K key){
TreeMap<K,V> map=hashtable[hash(key)];
return map.containsKey(key);
}
//8.查询:根据key得到value
public V get(K key){
int index=hash(key);
TreeMap<K,V> map=hashtable[index];
return map.get(key);
}
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









