







- 集合基础概念
一、collection的子接口
--------Deque
--------List
--------Queue
--------Set
--------SortedSet

Map的已知实现类
-------------map<K,V>
-------------HashMap
-------------Hashtable
-------------LinkedHashMap
-------------TreeMap 基于红黑树实现的
二、set
1.集合(Set) 集合:
存储不重复元素的容器
有序集合中的元素具有顺序性,基于搜索树实现
无序集合中的元素没有顺序性,基于哈希表实现
顺序性,是指按照元素的大小进行排序,并非指插入的顺序
有序性,是指元素的进场顺序和出场顺序一致
应用场合: 客户统计 词汇量统计
2.java内部set用红黑树、哈希表、哈希链表实现
自己写可以用:线性表、BST二分搜索树时实现
- 基于二分搜索树实现的集合
package org.openlab.集合与映射;
import org.yanan.二分搜索树.BinarySearchTree;
//基于二分搜索树实现的集合
public class BSTSet<E extends Comparable<E>> implements Set<E> {
private BinarySearchTree<E> tree;
//构造函数
public BSTSet(){
tree=new BinarySearchTree<E>();
}
@Override
public void add(E e) {//O(logn)
if(!tree.contains(e)){
tree.add(e);
}
}
@Override
public void remove(E e) {//O(logn)
tree.remove(e);
}
@Override
public boolean contains(E e) {//O(logn)
return tree.contains(e);
}
@Override
public int getSize() {
return tree.size();
}
@Override
public boolean isEmpty() {
return tree.isEmpty();
}
}
=====================统计不重复单词的个数============================
package org.openlab.集合与映射;
import java.util.ArrayList;
public class Main2 {
public static void main(String[] args) {
ArrayList<String> words=new ArrayList<>();
FileOperation.readFile("a-tale-of-two-cities.txt", words);//将傲慢与偏见文档的所有单词读入ArrayList中
long startTime=System.currentTimeMillis();
BSTSet<String> set=new BSTSet<>();
for(int i=0;i<words.size();i++){
set.add(words.get(i));
}
long endTime=System.currentTimeMillis();
double second=(endTime-startTime)/1000.0;
System.out.println("用时"+second+"秒");
System.out.println("双城记一共有多少个单词:"+words.size());
System.out.println("双城记有多少个单词,不能算重复的:"+set.getSize());
}
}
- 基于链表实现的集合
package org.openlab.集合与映射;
import org.yanan.link.LinkedList;
//基于链表实现的集合
public class LinkedSet<E> implements Set<E> {
private LinkedList<E> list;
//构造行数
public LinkedSet(){
list=new LinkedList<E>();
}
@Override
public void add(E e) {//O(n)
if(!list.contain(e)){
list.addFirst(e);//O(1)
}
}
@Override
public void remove(E e) {//O(n)
list.removeElement(e);
}
@Override
public boolean contains(E e) {//O(n)
return list.contain(e);
}
@Override
public int getSize() {
return list.getSize();
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
}
=====================统计不重复单词的个数============================
package org.openlab.集合与映射;
import java.util.ArrayList;
public class Main1 {
public static void main(String[] args) {
ArrayList<String> words=new ArrayList<>();
FileOperation.readFile("pride-and-prejudice.txt", words);//将傲慢与偏见文档的所有单词读入ArrayList中
long startTime=System.currentTimeMillis();
LinkedSet<String> set=new LinkedSet<>();
for(int i=0;i<words.size();i++){
set.add(words.get(i));
}
long endTime=System.currentTimeMillis();
double second=(endTime-startTime)/1000.0;
System.out.println("用时"+second+"秒");
System.out.println("傲慢与偏见一共有多少个单词:"+words.size());
System.out.println("傲慢与偏见有多少个单词,不能算重复的:"+set.getSize());
}
}
- 映射Map基础
Map的已知实现类
-------------map<K,V>
-------------HashMap
-------------Hashtable
-------------LinkedHashMap
-------------TreeMap
映射->字典->键值对的集合
姓名->ID
单词->释义
学生->学号
[张三 李四 王五]
[10 11 12]
class Person
name
id
[p1,p2,p3]
Key不能重复(把所有key拿出来组装成set) value可以重复(可以用list完成value)
{Key-Value} 键值对
{Key-Value} 键值对
{Key-Value} 键值对
{Key-Value} 键值对
{Key-Value} 键值对
Key Value 字典中:
单词 ——> 释义
名册中: 身份证号 ——> 人
车辆管理中: 车牌号 ——> 车
数据库中: id ——> 信息
词频统计: 单词 ——> 频率
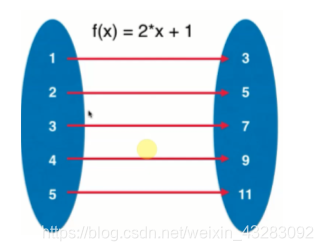
映射就是存储(键,值)
数据对的数据结构(Key,Value)。
根据键(Key),寻找值(Value)
有序映射中的键具有顺序性,基于搜索树实现
无序映射中的键没有顺序性,基于哈希表实现
将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。映射顺序定义为迭代器在映射的 collection 视图上返回其元素的顺序。某些映射实现可明确保证其顺序,如 TreeMap 类;另一些映射实现则不保证顺序,如 HashMap 类。
某些映射实现对可能包含的键和值有所限制。例如,某些实现禁止 null 键和值,另一些则对其键的类型有限制。尝试插入不合格的键或值将抛出一个未经检查的异常,通常是 NullPointerException 或 ClassCastException。试图查询是否存在不合格的键或值可能抛出异常,或者返回 false;某些实现将表现出前一种行为,而另一些则表现后一种。一般来说,试图对不合格的键或值执行操作且该操作的完成不会导致不合格的元素被插入映射中时,将可能抛出一个异常,也可能操作成功,这取决于实现本身。这样的异常在此接口的规范中标记为“可选”。
entrySet方法
Set<Map.Entry<K,V>> entrySet()返回此映射中包含的映射关系的 Set 视图。该 set 受映射支持,所以对映射的更改可在此 set 中反映出来,反之亦然。如果对该 set 进行迭代的同时修改了映射(通过迭代器自己的 remove 操作,或者通过对迭代器返回的映射项执行 setValue 操作除外),则迭代结果是不确定的。set 支持元素移除,通过 Iterator.remove、Set.remove、removeAll、retainAll 和 clear 操作可从映射中移除相应的映射关系。它不支持 add 或 addAll 操作。
返回:
此映射中包含的映射关系的 set 视图
- 基于二分搜索树实现的映射
package org.openlab.集合与映射;
import org.yanan.data.List;
public class BSTMap<K extends Comparable<K>,V> implements Map<K, V> {
//1.定义内部类结点
private class Node{
public K key;
public V value;
public Node left,right;
public Node(K key,V value){
this.key=key;
this.value=value;
left=null;
right=null;
}
public Node(){
this(null,null);
}
//打印结点
@Override
public String toString() {
return key.toString()+value.toString();
}
}
//2.定义成员变量,进行针对性初始化,即构造函数
private Node root;
private int size;
public BSTMap(){
root=null;
size=0;
}
//3.添加键值对
@Override
public void add(K key, V value) {
root=add(root,key,value);
}
private Node add(Node node, K key, V value) {
if(node==null){
size++;
return new Node(key,value);
}
if(key.compareTo(node.key)<0){
node.left=add(node.left,key,value);
}else if(key.compareTo(node.key)>0){
node.right=add(node.right,key,value);
}
return node;
}
//4.根据K删除V,先获取看所删值是否存在,递归实现
@Override
public V remove(K key) {
Node n=getNode(root, key);//获取要删除的结点
if(n==null){//找不到该节点,返回null
return null;
}
root=remove(root,key);//否则从根开始找,删除key,删完后返回新树的根
return n.value;//最终返回要删除的值
}
private Node remove(Node node,K key){//此Node不代表所删除的结点,而是删除后新的树的根节点
if(node==null){
return null;
}
if(key.compareTo(node.key)<0){
node.left=remove(node.left,key);
return node;//删除后继续返回给上一层
}else if(key.compareTo(node.key)>0){
node.left=remove(node.right,key);
return node;//删除后继续返回给上一层
}else{
if(node.left==null){//左子树为空,返回右子树
Node leftNode=node.right;//把node的右子树给其父节点做左子树
node.right=null;
size--;
return leftNode;
}
if(node.right==null){
Node rightNode=node.left;
node.left=null;
size--;
return rightNode;
}
//将要删除的结点的左子树的最大值或右子树的最小值替换给要删除的值
Node successor=minimum(node.right);//找到要删除的结点的右子树的最小值
//把要删除结点的右子树的全部(除开 successor本身)给 successor,左子树的全部给 successor
successor.right=removeMin(node.right);
successor.left=node.left;
node.left=node.right=null;
return successor;
}
}
private Node removeMin(Node node) {
if(node.left==null){
Node rightNode=node.right;
node.right=null;
size--;
return rightNode;
}
node.left=removeMin(node.left);
return node;
}
private Node minimum(Node node) {//找最小值
if(node.left==null){
return node;
}else{
return minimum(node.left);
}
}
//5.判断是否包含,引入辅助函数
@Override
public boolean contains(K key) {
Node n=getNode(root, key);
return n==null?false:true;
}
//6.根据K得到V
@Override
public V get(K key) {
Node n=getNode(root, key);
return n==null?null:n.value;
}
//7.修改
@Override
public void set(K key, V value) {
Node n=getNode(root, key);
if(n==null){
throw new IllegalArgumentException("don't exist");
}
n.value=value;
}
@Override
public int getSize() {
return size;
}
@Override
public boolean isEmpty() {
return size==0;
}
//8.返回映射中键的集合
@Override
public Set key() {
Set<K> set=new BSTSet<K>();
inOder(root,set);//中序遍历二分搜索树
return set;
}
private void inOder(Node node, Set<K> set) {
if(node==null){
return;
}
inOder(node.left,set);
set.add(node.key);
inOder(node.right,set);
}
//返回映射中值的集合
@Override
public List value() {
return null;
}
private Node getNode(Node node,K key){
if(node==null){
return null;
}
//为什么不写成:node.left=add(node.left,key,value);只是查询,并不修改,不用更新值
if(key.compareTo(node.key)<0){
return getNode(node.left,key);
}else if(key.compareTo(node.key)>0){
return getNode(node.right,key);
}else{
return node;
}
}
}
==================================================================
package org.openlab.集合与映射;
import java.util.ArrayList;
public class Main4 {
public static void main(String[] args) {
ArrayList<String> words=new ArrayList<>();
FileOperation.readFile("pride-and-prejudice.txt", words);
long startTime=System.currentTimeMillis();
BSTMap<String,Integer> map=new BSTMap<>();
for(int i=0;i<words.size();i++){
String word =words.get(i);
if(map.contains(word)){
map.set(word, map.get(word)+1);
}else{
map.add(word, 1);
}
}
long endTime=System.currentTimeMillis();
double second=(endTime-startTime)/1000.0;
System.out.println("用时"+second+"秒");
System.out.println("map的长度,不重复单词的个数"+map.getSize());
System.out.println("she出现的次数:"+map.get("she"));//查一个单词的次数
System.out.println(map.key());
}
}
- 基于动态链表实现的映射
package org.openlab.集合与映射;
import org.yanan.data.List;
import org.yanan.link.LinkedList;
//基于动态链表实现的映射
public class LinkedListMap<K,V> implements Map<K, V> {//k虽然不能重复,但不用在此说明它不具有可比性
//不能直接使用已经写过的LinkedList,因为有两个值要存
//1.定义内部类结点
private class Node{
public K key;
public V value;
public Node next;
public Node(K key,V value){
this.key=key;
this.value=value;
next=null;
}
public Node(){
this(null,null);
}
@Override
public String toString() {
return key.toString()+":"+value.toString();//打印结点,即打印结点的key和value值
}
}
//2.定义成员变量
private Node head;//定义一个头指针
private int size;
//3.构造函数
public LinkedListMap() {
head=new Node();//虚拟头结点
//head=null代表head是头结点
size=0;
}
//4.为操作方便,定义一个辅助函数
private Node getNode(K key){
//迭代
/*Node p=head.next;
while(p!=null){
if(p.key.equals(key)){
return p;
}
p=p.next;
}
return null;//两种情况:p==null或遍历LinkedList也没有找到
*/
return getNode(head.next,key);
}
private Node getNode(Node node,K key) {
if(node==null){
return null;
}
if(node.key.equals(key)){
return node;
}else{
return getNode(node.next,key);
}
}
//5.添加键值对,迭代实现,没必要递归,看需求,递归默认为尾插法;若不存在就直接加,存在就改
@Override
public void add(K key, V value) {
Node n=getNode(key);
if(n==null){//n不存在,直接插入头插
n=new Node(key,value);//结点不存在,将结点创建出来
n.next=head.next;
head.next=n;
size++;
}else{
n.value=value;//若存在直接替换value值
}
}
//6.根据K删除V,需要遍历,找到要删除元素的前驱
@Override
public V remove(K key) {
Node pre=head;//从head开始,若从head.next开始,还需判断head.next是否为要删除的元素
while(pre.next!=null){
if(pre.next.key.equals(key)){
break;
}
pre=pre.next;
}
//两种退出情况:找到删除元素的前驱或pre.next==null找不到该元素
if(pre.next!=null){
Node n=pre.next;//取出要删除的结点
pre.next=n.next;
n.next=null;//这一步有没有无所谓
size--;
return n.value;
}
return null;//若找不到该元素直接返回null
}
//7.判断是否包含
@Override
public boolean contains(K key) {
return getNode(key)!=null;
}
//8.根据K得到V
@Override
public V get(K key) {
Node n=getNode(key);
return n==null?null:n.value;
}
//9.修改,添加中包含修改,所以找不到时就抛异常
@Override
public void set(K key, V value) {
Node n=getNode(key);
if(n==null){
throw new IllegalArgumentException("don't exist!");
}else{
n.value=value;
}
}
@Override
public int getSize() {
return size;
}
@Override
public boolean isEmpty() {
return size==0;
}
//11.返回映射中键的集合
@Override
public Set key() {
Set<K> set =new LinkedSet<K>();//二分搜索树的元素必须具有可比较性,所以选用LinkedSet
Node cur=head.next;
while(cur!=null){
set.add(cur.key);
}
return set;
}
//12.返回映射中值的集合
@Override
public List value() {
List<V> list=new LinkedList<V>();//经常插入和删除,所以不用ArrayList
Node cur=head.next;
while(cur!=null){
list.addLast((cur.value));
}
return list;
}
}
=======================统计每个单词出现的个数========================
package org.openlab.集合与映射;
import java.util.ArrayList;
public class Main3 {
public static void main(String[] args) {
ArrayList<String> words=new ArrayList<>();
FileOperation.readFile("pride-and-prejudice.txt", words);
long startTime=System.currentTimeMillis();
LinkedListMap<String,Integer> map=new LinkedListMap<>();
for(int i=0;i<words.size();i++){
//先获取单词
String word=words.get(i);
//判断该单词是否在map中
if(map.contains(word)){//若包含,改map,将map中value值加1
map.set(word, map.get(word)+1);
}else{
map.add(word, 1);//不包含,将该单词加入map中
}
}
long endTime=System.currentTimeMillis();
double second=(endTime-startTime)/1000.0;
System.out.println("用时"+second+"秒");
System.out.println("map的长度,不重复单词的个数"+map.getSize());
System.out.println("prejudice出现的次数"+map.get("prejudice"));//查一个单词出现的次数
}
}














 4356
4356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









