







Spark对聚合做了优化,有几种AggMode
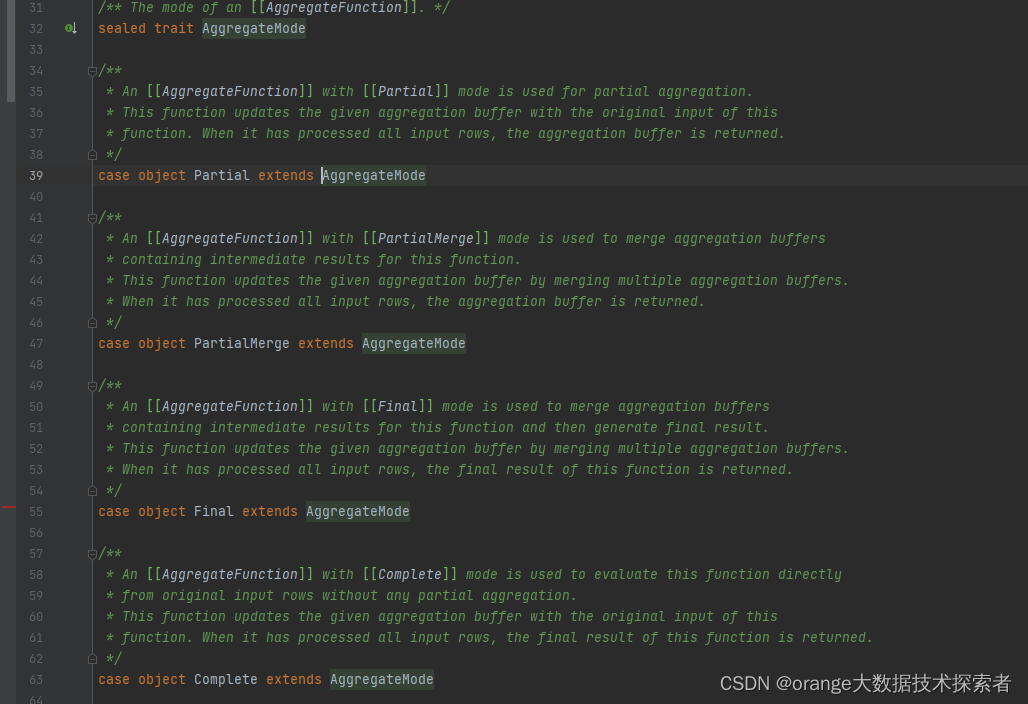
Partial: 局部数据的聚合。会根据读入的原始数据更新对应的聚合缓冲区,当处理完所有的输入数据后,返回的是局部聚合的结果
PartialMerge: 主要是对Partial返回的聚合缓冲区(局部聚合结果)进行合并,但此时仍不是最终结果,还要经过Final才是最终结果(count distinct 类型)
Final: 起到的作用是将聚合缓冲区的数据进行合并,然后返回最终的结果
Complete: 不进行局部聚合计算,应用在不支持Partial模式的聚合函数上(比如求百分位percentile_approx)
非distinct类的聚合函数的路线:Partial --> Final
distinct类的聚合函数的路线:Partial --> PartialMerge --> Partial --> Final
在hive中,我们常用两次group代替count(distinct)来做优化,避免结果数据在一个reduce运行,但是spark其实帮我们做了优化
先通过hash保证同一个value不会分配到多个task,我只需要对当前task统计,合并求sum就行了
有人会问那要是我有多个distinct怎么办,会对数据做expand,比如 select count(distinct uid),count(distinct device_id)
物理执行计划有:Expand [[uid#7818, null, 1], [null, device_id#7821, 2]]
当然了,会导致数据膨胀的问题
具体执行类是 HashAggregateExec















 3373
3373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











