







urllib包,专门处理http请求响应的内置包。
import urllib
urllib包下的_init_.py没写东西,import urllib写法并不会引入其他文件。
import urllib.request
#from urllib import request
#from urllib.request import urlopen
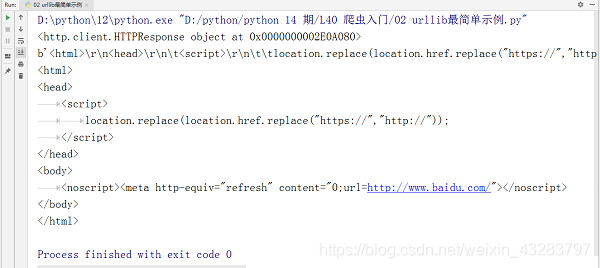
response = urllib.request.urlopen('https://www.baidu.com')
#urlopen(url, data={参数1: 值1, 参数2:值2},timeout=网页响应超时时间)
print(response)
#从响应读信息
html_content = response.read()
print(html_content) # 字节类型的网页信息
print(html_content.decode(encoding='utf-8')) # 字节解码成字符串
运行结果如下:
网上教程urllib urllib2,这两个包的区别,urllib3
py2时代内置处理http的包是urllib,增加改进发布urllib2包。这两个包都是内置。
urllib3第三方开发者开发,语法比较自然,requests包基于urllib3包。
py3时代把py2时代的urllib、urllib2包合并成urllib。
总结: 现在我们用的http相关处理包,主要有内置的urllib,第三方requests这两个包。
urllib 代理示例
为了防止同一个ip频繁访问服务器被封锁,需要不断变化ip通过别人的电脑代理访问服务器。
从哪找代理?
- ip代理平台 http://www.xicidaili.com/nn/
免费的不太稳定有些不可用。付费的稳定。 - 网友搜集爬取的ip代理池。
import urllib.request
import random
#proxies = [{'http': 'http://124.231.50.56:8118'}]
#proxy = random.choice(proxies)
#设置代理操作器
proxy = urllib.request.ProxyHandler({'http':'http://116.7.176.75:8118'})
#构建新的请求器,覆盖默认opener
opener = urllib.request.build_opener(proxy, urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
reponse = urllib.request.urlopen('http://www.baidu.com/s?wd=ip')
html_content = reponse.read().decode('utf-8')
#返回结果中查找“主机ip”看是否变更为代理ip
print(html_content)
- 可能出现的错误:
- 长时间未响应。urllib.error.URLError:<urlopen error[WinError 10060]由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
- 对方服务器拒绝链接。 connectionResetError远程主机关闭了一个现有的连接。
解决 换一个或购买付费接口
- 代理池:一个两个ip不够用,需要列表,手动添加代码麻烦。
解决方案:专门写一个搜集ip代理网站免费信息的爬虫,把爬下来的代理














 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









