






前向分步算法
利用线性组合将一系列的弱学习器结合,已解决单一弱学习器在测试集上泛化能力不强的境况。这个想法被称作加法模型,表示如下:
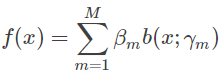
式中βm是基函数b(x;γm)的系数。
在给定训练数据和损失函数L(y,f(x))的条件下,学习加法模型f(x)成为经验风险极小化(即损失函数极小化问题) 。
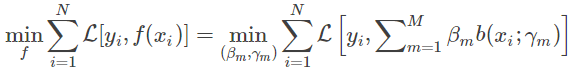
通常这是一个复杂的优化问题,如果能从前向后每一步只学习一个基函数及其系数,逐步逼近优化目标函数式,那么就可以简化优化的复杂度。而每一步学习一个基函数及其系数:
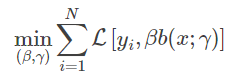
逐步地使得其减小,直到最后逼近0,即达到优化目的,这便是前向分步算法的思想。
算法过程:
负梯度拟合
Boosting Decision Tree迭代过程中,假设我们前一轮迭代得到的强学习器是
f(t−1)(x),损失函数是L(y,ft−1(x)) L(y,f_{t-1}(x))L(y,f (t−1)(x)),我们本轮迭代的目标是找到一个回归树模型的弱学习器ht(x) ,让本轮的损失L(y,ft(x))=L(y,ft−1(x)+ht(x)) (x))最小。也就是说,本轮迭代找到的决策树,要让样本的损失函数尽量变得更小。
我们利用损失函数的负梯度来拟合本轮损失函数的近似值,进而拟合一个CART回归树。其中第t轮的第i个样本的损失函数的负梯度表示为
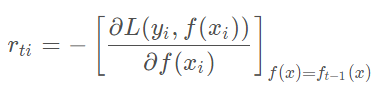
通过拟合一颗CART回归树,可以得到第t颗回归树。针对每一个叶子节点中的样本,我们求出使损失函数最小,也就是拟合叶子节点最好的输出值ctj。其中决策树中叶节点值已经生成一遍,此步目的是稍加改变决策树中叶节点值,希望拟合的误差越来越小。
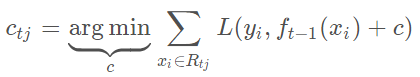
这样我们便得到本轮的决策树拟合函数。
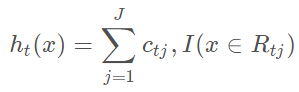
从而本轮最终得到的强学习器表达式如下
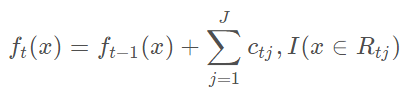
通过损失函数的负梯度拟合,我们找到一种通用的拟合损失函数的方法,这样无论是分类问题还是回归问题,我们通过其损失函数的负梯度拟合,就可以用GBDT来解决我们的分类回归问题。
损失函数
回归算法损失函数
- 均方差
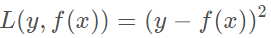
- 绝对损失和对应的负梯度误差。
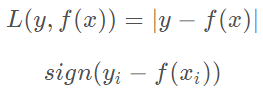
- Huber损失是均方差和绝对损失的折衷产物,对于远离中心的异常点,采用绝对损失,而中心点附近采用均方差。这个界限一般用分位数点来度量,损失函数和对应的负梯度误差如下。
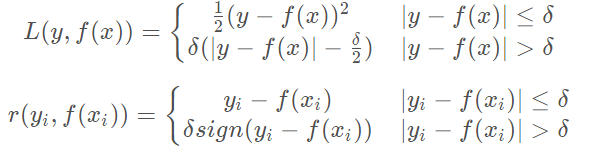
- 分位数损失和负梯度误差如下所示。其中其中θ \thetaθ为分位数,需要我们在回归前指定。
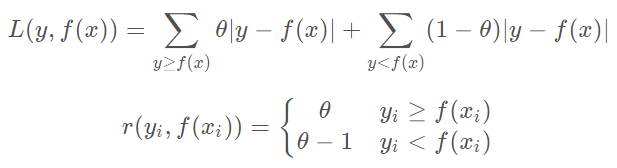
分类算法损失函数
- 对数损失函数。
- 指数损失函数。
回归
假设训练集样本T={(x,y1),(x,y2),…,(x,ym)} ,最大迭代次数为T,损失函数L,输出是强学习器f(x)。回归算法过程如下所示:

分类
GBDT分类算法在思想上和回归算法没有区别,但是由于样本输出不是连续的值,而是离散的类别,导致我们无法直接从输出类别去拟合类别输出的误差。为解决此问题,我们尝试用类似于逻辑回归的对数似然损失函数的方法,也就是说我们用的是类别的预测概率值和真实概率值来拟合损失函数。对于对数似然损失函数,我们有二元分类和多元分类的区别。
二分类
对于二元GBDT,如果用类似于逻辑回归的对数似然损失函数,则损失函数表示为
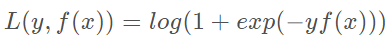
其中y∈{−1,1} ,则此时的负梯度误差为
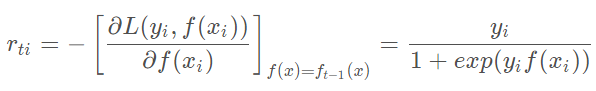
对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
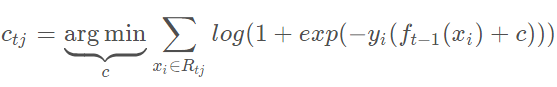
由于上式比较难优化,我们一般使用近似值代替。
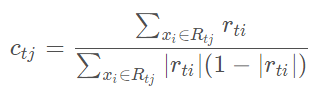
多分类
多元GBDT要比二元GBDT复杂一些,对应的是多元逻辑回归和二元逻辑回归的复杂度差别。假如类别数为K,则我们的对数似然函数为
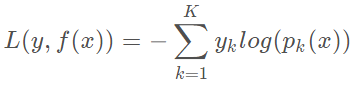
其中如果样本输出类别为k,则yk=1,第k类的概率pk(x)的表达式为
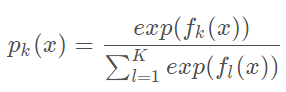
集合上两式,我们可以计算出第t轮的第i个样本对应类别l的负梯度误差为
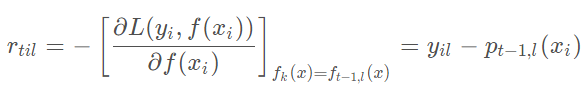
其实这里的误差就是样本i对应类别l的真实概率和t-1轮预测概率的差值。对于生成的决策树,我们各个叶子节点的最佳残差拟合值为
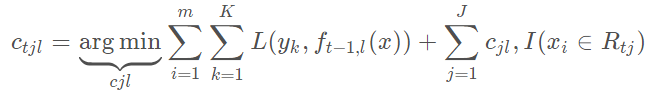
正则化
针对GBDT正则化,我们通过子采样比例方法和定义步长v方法来防止过拟合。
- 子采样比例:通过不放回抽样的子采样比例(subsample),取值为(0,1]。如果取值为1,则全部样本都使用。如果取值小于1,利用部分样本去做GBDT的决策树拟合。选择小于1的比例可以减少方差,防止过拟合,但是会增加样本拟合的偏差。因此取值不能太低,推荐在[0.5, 0.8]之间。
- 定义步长v:针对弱学习器的迭代,我们定义步长v,取值为(0,1]。对于同样的训练集学习效果,较小的v意味着我们需要更多的弱学习器的迭代次数。通常我们用步长和迭代最大次数一起来决定算法的拟合效果。
优缺点
优点:
- 相对少的调参时间情况下可以得到较高的准确率。
- 可灵活处理各种类型数据,包括连续值和离散值,使用范围广。
- 可使用一些健壮的损失函数,对异常值的鲁棒性较强,比如Huber损失函数。
缺点:
- 弱学习器之间存在依赖关系,难以并行训练数据。
sklearn参数
总结的较好的调参实例:http://www.cnblogs.com/DjangoBlog/p/6201663.html
参考链接:
https://blog.csdn.net/sinat_30353259/article/details/81587775#七-gbdt小结















 267
267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









