






写在前面:本文为个人复习sql所用,整理了sql之母的内容,请大家理性食用~~
附上一个个人觉得不错的sql刷题网站:sql之母(SQL之母 - SQL自学网站 (yupi.icu))
1. 基础语法 - 条件查询 - 模糊查询
模糊查询是一种特殊的条件查询,它允许我们根据模式匹配来查找符合特定条件的数据,可以使用 LIKE 关键字实现模糊查询。
在 LIKE 模糊查询中,我们使用通配符来代表零个或多个字符,从而能够快速地找到匹配的数据。
有如下 2 种通配符:
- 百分号(%):表示任意长度的任意字符序列。
- 下划线(_):表示任意单个字符。
模糊查询的应用场景:假设你是一名侦探,你需要根据目标人物的一部分线索信息来找到匹配的目标,比如你可以根据目标的名字中包含的关键字或字符来查找。
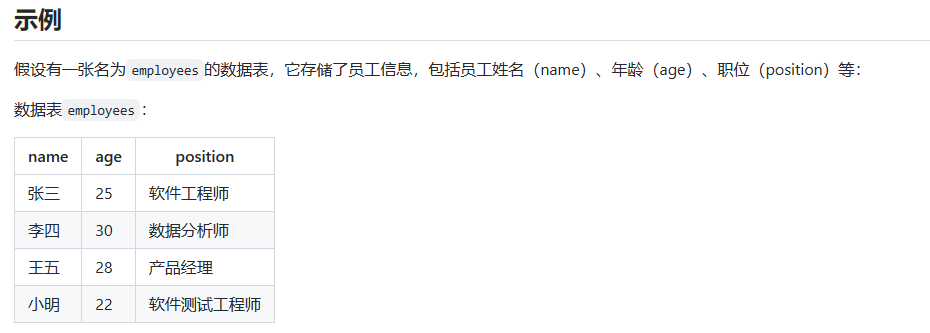
使用模糊查询匹配开头和结尾:
-- 只查询以 "张" 开头的数据行
select name, age, position from employees where name like '张%';
-- 只查询以 "张" 结尾的数据行
select name, age, position from employees where name like '%张';2. 基础语法 - 去重
在数据表中,可能存在重复的数据记录,但如果我们想要过滤掉重复的记录,只保留不同的记录,就要使用 SQL 的去重功能。
在 SQL 中,我们可以使用 DISTINCT 关键字来实现去重操作。
举个应用场景:假设你是班长,要统计班级中有哪些不同的学生,而不关心他们重复出现的次数,就可以使用去重。
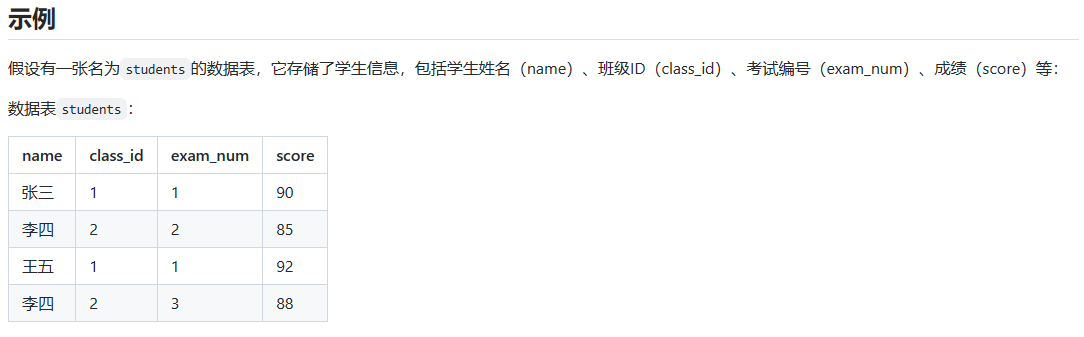
现在,我们使用DISTINCT关键字来找出不同的班级 ID:
-- SQL 查询语句
select distinct class_id from students;
除了按照单字段去重外,DISTINCT 关键字还支持根据多个字段的组合来进行去重操作,确保多个字段的组合是唯一的。
distinct 字段1, 字段2, 字段3, ...3. 基础语法 - 排序
在查询数据时,我们有时希望对结果按照某个字段的值进行排序,以便更好地查看数据。
在 SQL 中,我们可以使用 ORDER BY 关键字来实现排序操作。ORDER BY 后面跟上需要排序的字段,可以选择升序(ASC)或降序(DESC)排列。若不加排序要求,默认为升序

现在,我们使用ORDER BY关键字来对学生表进行排序:
-- SQL 查询语句 1
select name, age from students order by age asc;
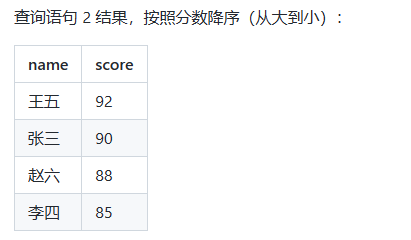
-- SQL 查询语句 2
select name, score from students order by score desc;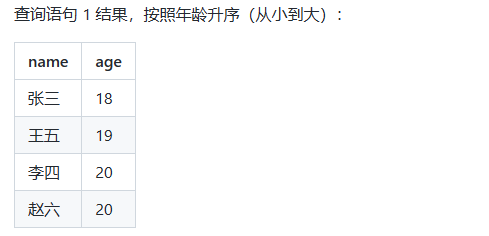
在排序的基础上,我们还可以根据多个字段的值进行排序。当第一个字段的值相同时,再按照第二个字段的值进行排序,以此类推。
order by 字段1 [升序/降序], 字段2 [升序/降序], ...4. 基础语法 - 截断和偏移
我们先用一个比喻来引出截断和偏移的概念。
假设你有一张待办事项清单,上面有很多任务。当你每次只想查看其中的几个任务时,会怎么办呢?
1)你可以使用手指挡住不需要看的部分(即截断)
2)根据任务的编号,直接翻到需要查看的位置(即偏移)
在 SQL 中,我们使用 LIMIT 关键字来实现数据的截断和偏移。
截断和偏移的一个典型的应用场景是分页,即网站内容很多时,用户可以根据页号每次只看部分数据。
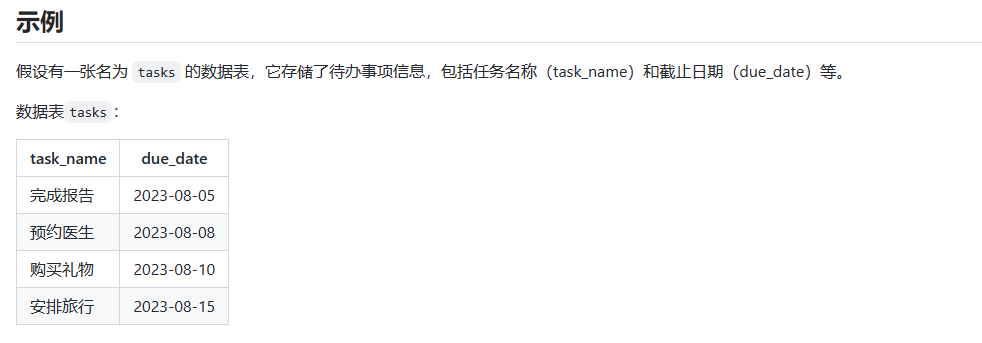
现在,我们使用LIMIT关键字来进行分页查询:
-- LIMIT 后只跟一个整数,表示要截断的数据条数(一次获取几条)
select task_name, due_date from tasks limit 2;
-- LIMIT 后跟 2 个整数,依次表示从第几条数据开始、一次获取几条
select task_name, due_date from tasks limit 2, 2;

5. 基础语法 - 条件分支
条件分支 case when 是 SQL 中用于根据条件进行分支处理的语法。它类似于其他编程语言中的 if else 条件判断语句,允许我们根据不同的条件选择不同的结果返回。
使用 case when 可以在查询结果中根据特定的条件动态生成新的列或对现有的列进行转换。
举个例子:假设你是一位餐厅的服务员,客人点了不同的菜品,而你需要根据客人点的菜来确定服务的方式。如果客人点了鱼,你会用餐具和服务方式适合吃鱼的方式来招待他们;如果客人点了牛排,你会用适合牛排的餐具和服务方式。case when 就像你根据客人点的菜品来选择不同服务方式的过程。
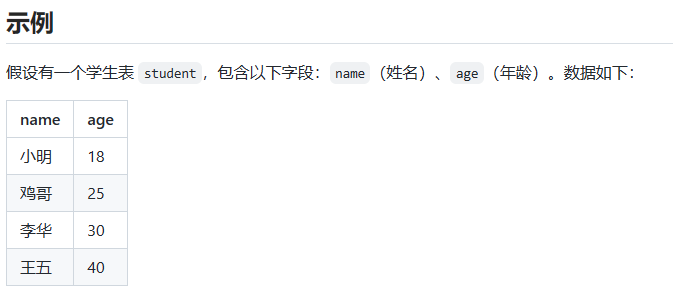
使用条件分支 case when ,根据 name 来判断学生是否会说 RAP,并起别名为 can_rap。
SELECT
name,
CASE WHEN (name = '鸡哥') THEN '会' ELSE '不会' END AS can_rap
FROM
student;
case when 支持同时指定多个分支,示例语法如下:
CASE WHEN (条件1) THEN 结果1
WHEN (条件2) THEN 结果2
...
ELSE 其他结果 END6. 函数 - 时间函数
在 SQL 中,时间函数是用于处理日期和时间的特殊函数。它们允许我们在查询中操作和处理日期、时间、日期时间数据,从而使得在数据库中进行时间相关的操作变得更加方便和灵活。
常用的时间函数有:
- DATE:获取当前日期
- DATETIME:获取当前日期时间
- TIME:获取当前时间
使用时间函数获取当前日期、当前日期时间和当前时间:
-- 获取当前日期
SELECT DATE() AS current_date;
-- 获取当前日期时间
SELECT DATETIME() AS current_datetime;
-- 获取当前时间
SELECT TIME() AS current_time;查询结果:
为了方便对比,放到同一个表格
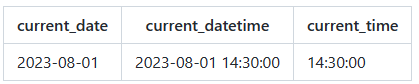
注意,这里的日期、日期时间和时间将根据当前的系统时间来生成,实际运行结果可能会因为当前时间而不同。
7. 函数 - 字符串处理
在 SQL 中,字符串处理是一类用于处理文本数据的函数。它们允许我们对字符串进行各种操作,如转换大小写、计算字符串长度以及搜索和替换子字符串等。字符串处理函数可以帮助我们在数据库中对字符串进行加工和转换,从而满足不同的需求。

1)使用字符串处理函数 UPPER 将姓名转换为大写:
-- 将姓名转换为大写
SELECT name, UPPER(name) AS upper_name
FROM employees;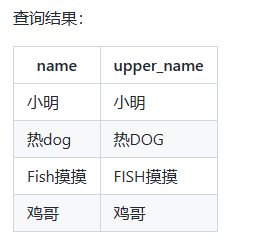
2)使用字符串处理函数 LENGTH 计算姓名长度:
-- 计算姓名长度
SELECT name, LENGTH(name) AS name_length
FROM employees;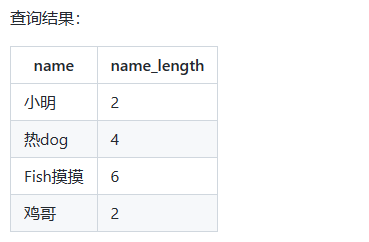
3)使用字符串处理函数 LOWER 将姓名转换为小写:
-- 将姓名转换为小写并进行条件筛选
SELECT name, LOWER(name) AS lower_name
FROM employees;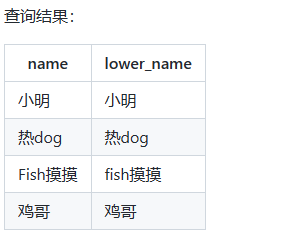
8. 函数 - 聚合函数
在 SQL 中,聚合函数是一类用于对数据集进行 汇总计算 的特殊函数。它们可以对一组数据执行诸如计数、求和、平均值、最大值和最小值等操作。聚合函数通常在 SELECT 语句中配合 GROUP BY 子句使用,用于对分组后的数据进行汇总分析。
常见的聚合函数包括:
- COUNT:计算指定列的行数或非空值的数量。
- SUM:计算指定列的数值之和。
- AVG:计算指定列的数值平均值。
- MAX:找出指定列的最大值。
- MIN:找出指定列的最小值。
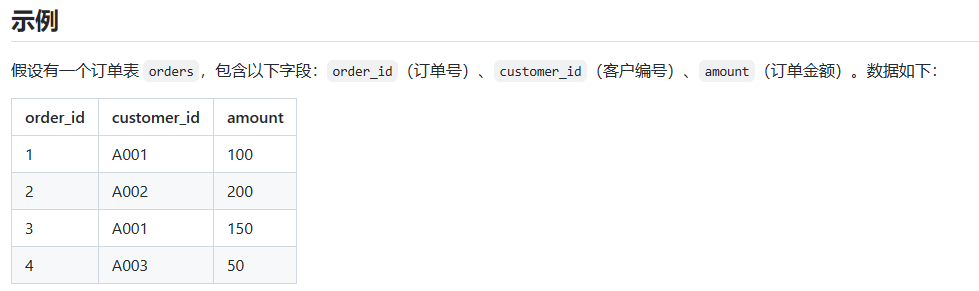
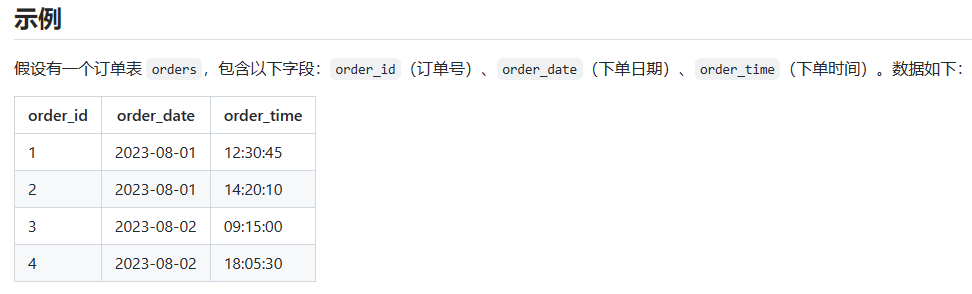
1)使用聚合函数 COUNT 计算订单表中的总订单数:
SELECT COUNT(*) AS order_num
FROM orders;
2)使用聚合函数 COUNT(DISTINCT 列名) 计算订单表中不同客户的数量:
SELECT COUNT(DISTINCT customer_id) AS customer_num
FROM orders;3)使用聚合函数 SUM 计算总订单金额:
SELECT SUM(amount) AS total_amount
FROM orders;
9. 分组聚合 - 单字段分组
在 SQL 中,分组聚合是一种对数据进行分类并对每个分类进行聚合计算的操作。它允许我们按照指定的列或字段对数据进行分组,然后对每个分组应用聚合函数,如 COUNT、SUM、AVG 等,以获得分组后的汇总结果。
举个例子:某个学校可以按照班级将学生分组,并对每个班级进行统计。查看每个班级有多少学生、每个班级的平均成绩。这样我们就能够对学校各班的学生情况有一个整体的了解,而不是单纯看个别学生的信息。
在 SQL 中,通常使用 GROUP BY 关键字对数据进行分组。
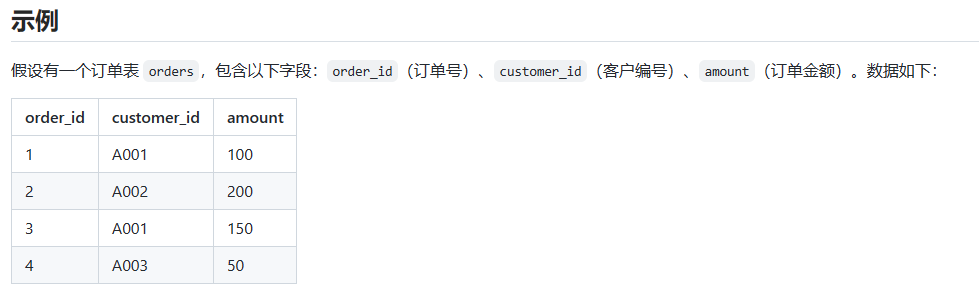
1)使用分组聚合查询中每个客户的编号:
SELECT customer_id
FROM orders
GROUP BY customer_id;
2)使用分组聚合查询每个客户的下单数:
SELECT customer_id, COUNT(order_id) AS order_num
FROM orders
GROUP BY customer_id;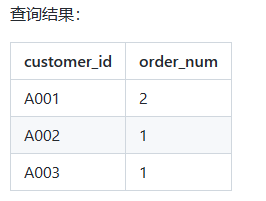
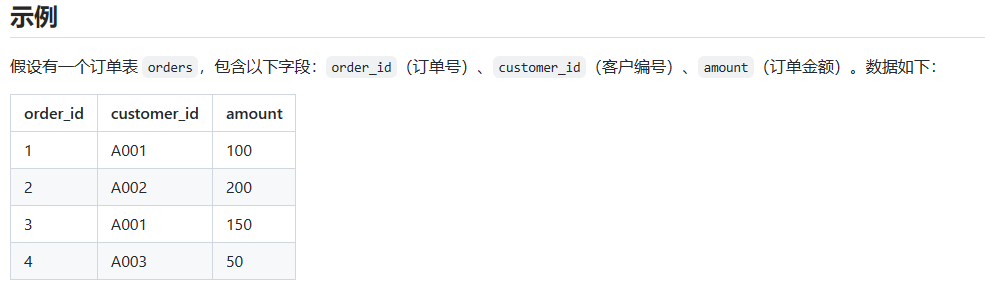
示例:
SELECT customer_id, COUNT(order_id) AS order_num
FROM orders
GROUP BY customer_id;
执行流程:
FROM子句:首先,数据库系统会从orders表中检索所需的数据。
GROUP BY子句:然后,根据customer_id字段对数据进行分组。这意味着将具有相同customer_id值的记录归为一组。
SELECT子句:接下来,对每个分组内的数据计算order_id字段的总和,并将结果作为order_num列返回。同时,还会选择customer_id列作为结果集的一部分。
结果显示:最后,将按照customer_id的分组结果和对应的总和order_id组成的结果集返回给用户。
总的执行顺序是:FROM -> GROUP BY -> SELECT。在实际执行过程中,数据库系统可能会根据数据量、索引等因素进行优化处理,但通常遵循这种逻辑执行顺序。10. 分组聚合 - 多字段分组
有时,单字段分组并不能满足我们的需求,比如想统计学校里每个班级每次考试的学生情况,这时就可以使用多字段分组。
多字段分组和单字段分组的实现方式几乎一致,使用 GROUP BY 语法即可。
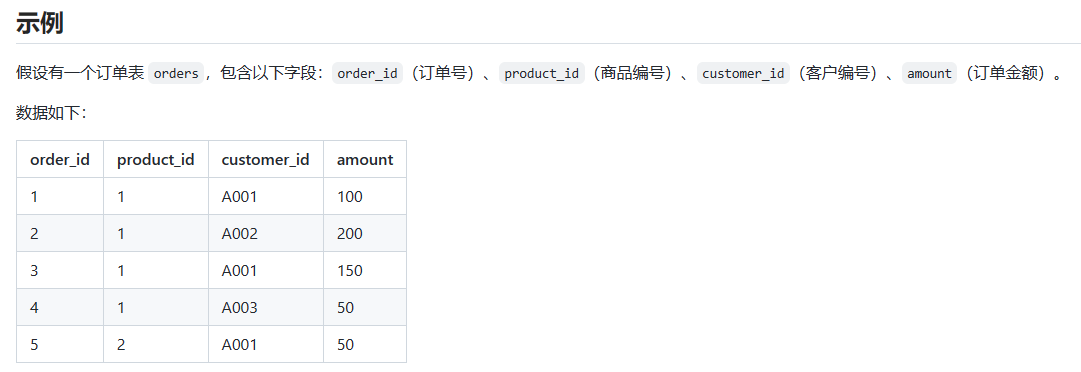
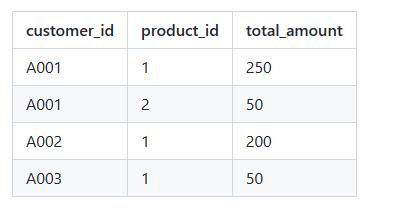
要查询使用多字段分组查询表中 每个客户 购买的 每种商品 的总金额,相当于按照客户编号和商品编号分组:
-- 查询每个用户购买的每种商品的总金额,按照客户编号和商品编号分组
SELECT customer_id, product_id, SUM(amount) AS total_amount
FROM orders
GROUP BY customer_id, product_id;查询结果:因为要查询不同客户购买的不同商品,因此要使用多字段同时分组
11. 分组聚合 - having 子句
在 SQL 中,HAVING 子句用于在分组聚合后对分组进行过滤。它允许我们对分组后的结果进行条件筛选,只保留满足特定条件的分组。
HAVING 子句与条件查询 WHERE 子句的区别在于,WHERE 子句用于在 分组之前 进行过滤,而 HAVING 子句用于在 分组之后 进行过滤。
1)使用 HAVING 子句查询订单数超过 1 的客户:
SELECT customer_id, COUNT(order_id) AS order_num
FROM orders
GROUP BY customer_id
HAVING COUNT(order_id) > 1;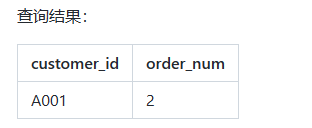
2)使用 HAVING 子句查询订单总金额超过 100 的客户:
-- 查询订单总金额超过100的客户
SELECT customer_id, SUM(amount) AS total_amount
FROM orders
GROUP BY customer_id
HAVING SUM(amount) > 100;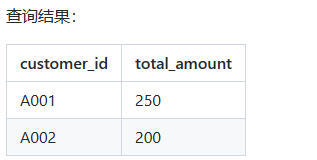
12. 查询进阶 - 关联查询 - cross join
在之前的教程中,我们所有的查询操作都是在单个数据表中进行的。但有时,我们可能希望在单张表的基础上,获取更多额外数据,比如获取学生表中学生所属的班级信息等。这时,就需要使用关联查询。
在 SQL 中,关联查询是一种用于联合多个数据表中的数据的查询方式。
其中,CROSS JOIN 是一种简单的关联查询,不需要任何条件来匹配行,它直接将左表的 每一行 与右表的 每一行 进行组合,返回的结果是两个表的笛卡尔积。
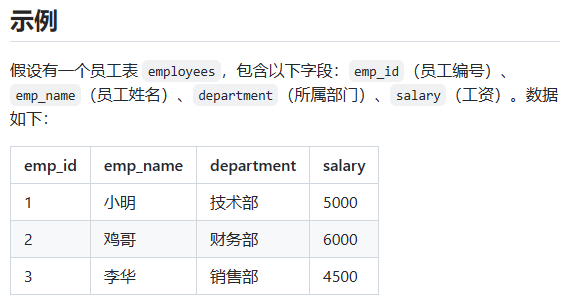

使用 CROSS JOIN 进行关联查询,将员工表和部门表的所有行组合在一起,获取员工姓名、工资、部门名称和部门经理,示例 SQL 代码如下:
SELECT e.emp_name, e.salary, e.department, d.manager
FROM employees e
CROSS JOIN departments d;注意,在多表关联查询的 SQL 中,我们最好在选择字段时指定字段所属表的名称(比如 e.emp_name),还可以通过给表起别名(比如 employees e)来简化
13. 查询进阶 - 关联查询 - inner join
在 SQL 中,INNER JOIN 是一种常见的关联查询方式,它根据两个表之间的关联条件,将满足条件的行组合在一起。
注意,INNER JOIN 只返回两个表中满足关联条件的交集部分,即在两个表中都存在的匹配行。


使用 INNER JOIN 进行关联查询,根据员工表和部门表之间的公共字段 部门名称(department) 进行匹配,将员工的姓名、工资以及所属部门和部门经理组合在一起:
SELECT e.emp_name, e.salary, e.department, d.manager
FROM employees e
JOIN departments d ON e.department = d.department;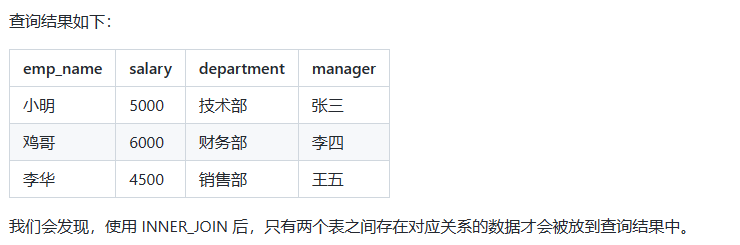
14. 查询进阶 - 关联查询 - outer join
在 SQL 中,OUTER JOIN 是一种关联查询方式,它根据指定的关联条件,将两个表中满足条件的行组合在一起,并 包含没有匹配的行 。
在 OUTER JOIN 中,包括 LEFT OUTER JOIN 和 RIGHT OUTER JOIN 两种类型,它们分别表示查询左表和右表的所有行(即使没有被匹配),再加上满足条件的交集部分。

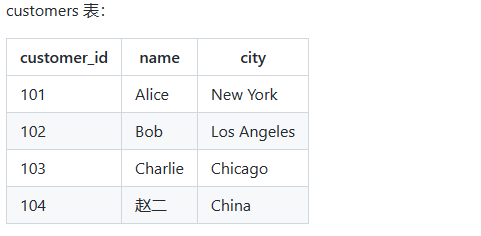
假设还有一个部门表 departments,包含以下字段:department(部门名称)、manager(部门经理)、location(所在地)。数据如下:

使用 LEFT JOIN 进行关联查询,根据员工表和部门表之间的部门名称进行匹配,将员工的姓名、工资以及所属部门和部门经理组合在一起,并包含所有员工的信息:
SELECT e.emp_name, e.salary, e.department, d.manager
FROM employees e
LEFT JOIN departments d ON e.department = d.department;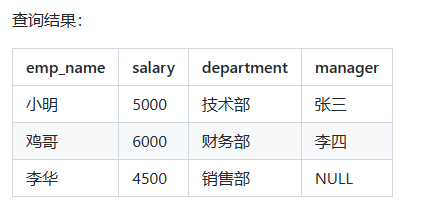
关注下表格的最后一条数据,李华所属的销售部并没有在部门表中,但仍然返回在了结果集中,manager 为 NULL。
有些数据库并不支持 RIGHT JOIN 语法,那么如何实现 RIGHT JOIN 呢?
其实只需要把主表(from 后面的表)和关联表(LEFT JOIN 后面的表)顺序进行调换即可!
15. 查询进阶 - 子查询
子查询是指在一个查询语句内部 嵌套 另一个完整的查询语句,内层查询被称为子查询。子查询可以用于获取更复杂的查询结果或者用于过滤数据。
当执行包含子查询的查询语句时,数据库引擎会首先执行子查询,然后将其结果作为条件或数据源来执行外层查询。
打个比方,子查询就像是在一个盒子中的盒子,外层查询是大盒子,内层查询是小盒子。执行查询时,我们首先打开小盒子获取结果,然后将小盒子的结果放到大盒子中继续处理。

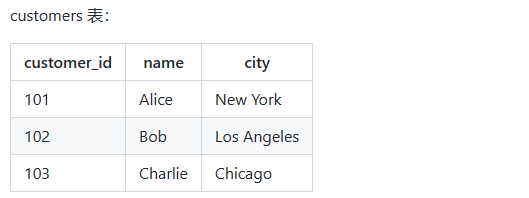
现在,我们希望查询出订单总金额 > 200 的客户的姓名和他们的订单总金额,示例 SQL 如下:
-- 主查询
SELECT name, total_amount
FROM customers
WHERE customer_id IN (
-- 子查询
SELECT DISTINCT customer_id
FROM orders
WHERE total_amount > 200
);在上述 SQL 中,先通过子查询从订单表中过滤查询出了符合条件的客户 id,然后再根据客户 id 到客户信息表中查询客户信息,这样可以少查询很多客户信息数据。
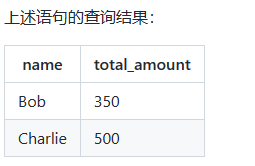
16. 查询进阶 - 子查询 - exists
之前的教程讲到,子查询是一种强大的查询工具,它可以嵌套在主查询中,帮助我们进行更复杂的条件过滤和数据检索。
其中,子查询中的一种特殊类型是 "exists" 子查询,用于检查主查询的结果集是否存在满足条件的记录,它返回布尔值(True 或 False),而不返回实际的数据。

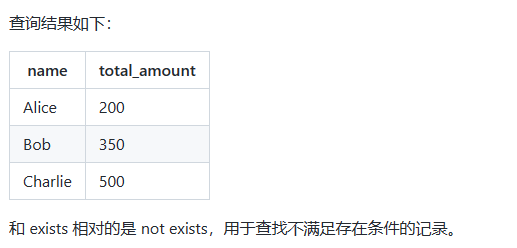
现在,我们希望查询出 存在订单的 客户姓名和订单金额。
使用 exists 子查询的方式,SQL 代码如下:
-- 主查询
SELECT name, total_amount
FROM customers
WHERE EXISTS (
-- 子查询
SELECT 1
FROM orders
WHERE orders.customer_id = customers.customer_id
);上述语句中,先遍历客户信息表的每一行,获取到客户编号;然后执行子查询,从订单表中查找该客户编号是否存在,如果存在则返回结果。















 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









