






此文用于个人面经总结,答案可能存在出入,望理性食用~~
1. 分析时间复杂度的工具
2. 数组和链表的区别
数组:线性表,存储空间连续,可以通过下标直接访问元素,查找时间复杂度为O(1),插入的时间复杂度为O(n),需要预分配一定大小的内存空间,有时会造成空间资源的浪费。
链表:线性表,存储空间不连续,插入时间复杂度为O(1),查找的时间复杂度为O(n),每个节点需要额外的空间来存储指针,也会造成资源的浪费。
3. 数组和链表哪个是线性表
线性表是由相同的数据类型的元素组成的有序序列,这些元素按照一个确定的顺序依次排列,其中元素之间存在唯一的前驱和后继关系。
常见的线性表包括:
数组、链表、栈、队列。
4. sql场景题:
4.1. 现在要创建一张用户订单表,里面有四个字段,分别为主键id、订单id、订单来源和用户id,如果让你设计,每个字段会使用那种数据类型,大小是多少,为什么?
主键ID:INT或BIGINT,如果预定订单的数量不超过21亿(2^31),使用INT,如果预计数量会更多,可以使用BIGINT,因为主键是唯一的,并且需要自增,INT和BIGINT都满足这一点。
订单ID:VARCHAR或CHAR,如果订单ID是固定的,那么可以使用CHAR;如果长度可变,使用VARCHAR。通常订单ID的长度在10~50位之间。
订单来源:VARCHAR,订单来源通常是文本描述,VARCHAR可以根据实际内容动态分配空间,比CHAR更灵活且节省空间。
用户ID:INT或BIGINT,取决于用户表使用那个,因为用户ID通常与用户表的主键相对应,因此数据类型要保持一致。
4.2. 半年后,用户的数量达到一千万量级,现有两个场景:查询订单详情和统计用户下单平台喜好,针对上面建的数据库,有需要修改和优化的地方吗?
- 索引优化:
-
- 对于查询订单详情,如果经常根据订单ID查询,确保订单ID字段上有索引。
- 对于统计用户下单平台喜好,如果经常根据用户ID和订单来源进行查询和聚合操作,考虑为这两个字段添加索引,特别是如果它们是查询条件或聚合函数的一部分。
- 分区:
-
- 考虑对用户订单表进行分区,以提高查询和维护的效率。分区可以基于时间(如按月或年分区)、用户ID范围或订单来源。
- 分库分表
4.3. 在社区系统查询信息的场景下,左模糊、右模糊和全模糊查询能否使用索引进行查询?
- 左模糊查询(LIKE '%value'):
-
- 在MySQL的InnoDB存储引擎中,如果使用了全文索引,则左模糊查询可以利用索引,但是如果使用的是标准的B-tree索引,左模糊查询不能有效利用索引,因为索引是按照字符串的开头部分创建的,而左模糊查询需要扫描整个列以找到匹配的行。
- 右模糊查询(LIKE 'value%'):
-
- 右模糊查询可以使用索引,因为大多数数据库的默认索引都是按照列值的升序排列的。这意味着索引已经按照查询模式排列好了,数据库可以快速定位到可能包含匹配项的区域。
- 全模糊查询(LIKE '%value%'):
-
- 全模糊查询不能利用索引,因为它们需要检查列中的每个值以找到匹配项。这种查询模式相当于一个全表扫描,因为数据库无法预测匹配项可能出现的位置。
5. 为什么使用索引的效率高?
6. 索引的底层数据结构和查找原理
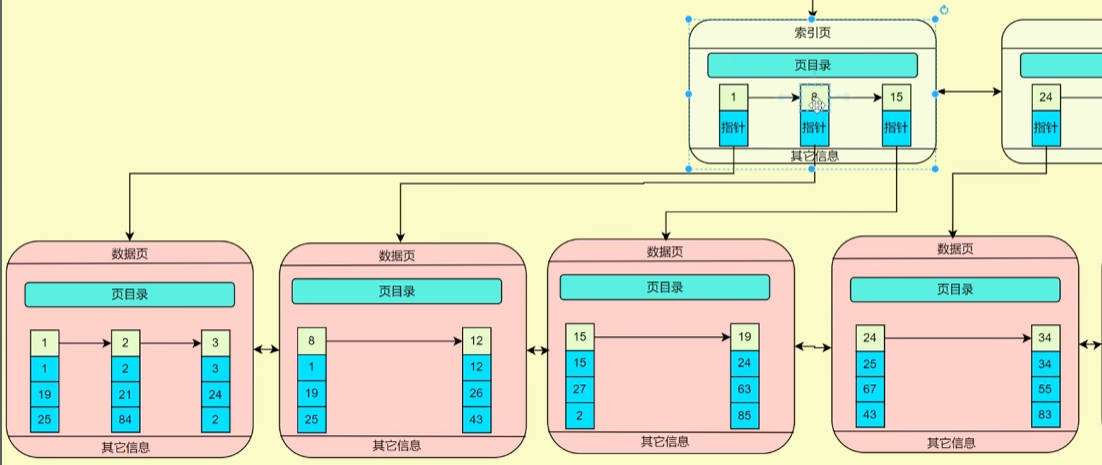
重难点:因为在MySQL中索引的数据结构为B+树,树中的节点就是索引页,索引的查找原理类似于AVL平衡二叉树的查找。在索引B+树中,每个结点存储索引的键(升序存储)和指针,用于指向其他结点,叶子结点存放具体的数据(主键索引则存放主键的值和其他所有字段的值,非聚族索引则存放的是普通索引的键值和它对应的主键id,用于回表查询)。在页目录查询过程中可以使用二分查找来提高查询结点的效率。
关键字:索引页、页目录、二分查找、全表扫描、数据页
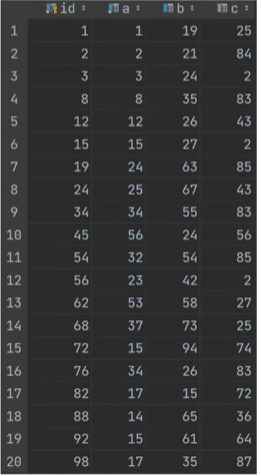
示例:现有数据表test如下,含id、a、b、c三个字段,其中id为主键索引,a和b也有索引
要求:select * from test where c = 83
分析:因此c没有建立索引,因此需要进行全表查询,而a和b索引不是主键索引,其只存储了对应键值和主键id,因此需要去a索引中查询。a索引为主键索引,页内数据是根据主键id升序排序的,因此要查找c则需要先找到B+树最左边的叶节点,然后从左往右进行全表扫描。
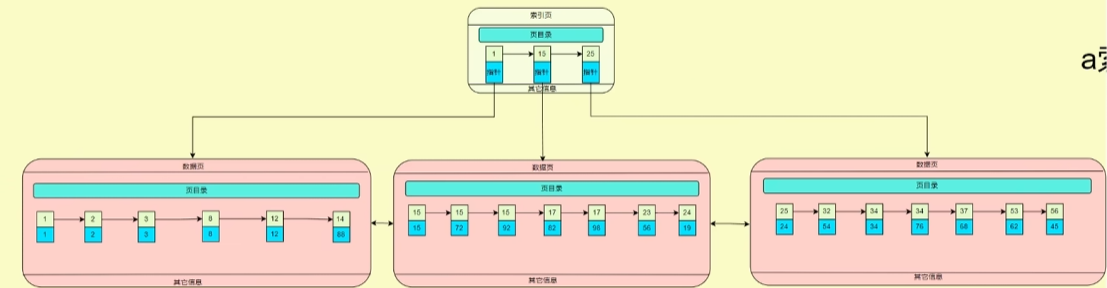
要求2:select * from test where b = 94;
分析:最终要查询处理的结果为id,a,b,c,查询条件为b=94,而b是有索引的,则会根据b的值在索引表中查找其对应的数据页,找到b=94对应的id,然后通过该id回表查询主键索引,找到该id对应的数据页,然后因为主键索引存储了所有数据项,所有返回最终查询的结果id,a,b,c。
记录是如何排序的:
如果表有主键,会根据主键排序;没主键有唯一非空索引,会根据该索引排序;两者都没有,InnoDB会自动生成一个row_id列并根据该列进行排序。
什么是回表查询:
回表查询是指当通过非聚族索引来查询非主键信息时,需要先根据在非聚族索引中找到其对应的主键值,然后根据该主键值再来去主键索引中查询对应的数据,这个二次查询的操作就是回表。
避免回表查询的方法有:建立聚合索引、不随意使用select*、根据场景合理构建索引。


a索引表结构示例:
7. int和Integer的区别?
- Integer是int的包装类;int是基本数据类型。
- Integer变量必须实例化后才能使用;int变量不需要。
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值。
- Integer的默认值是null;int的默认值是0
8. int有默认值吗?什么情况下有默认值,什么情况下没有?
对于类的成员变量和全局变量有默认值,默认值为0,对于局部变量(在方法或块中定义的变量),没有默认值,在使用之前必须初始化。
9. Integer有默认值吗?什么情况下有默认值,什么情况下没有?
对于未初始化的对象引用及成员变量,Integer如果未显式初始化,会被赋予默认值null。
对于局部变量,不会初始化。
10. 原子类的功能和作用
11. 异常和error的区别
Exception和Error都是Throwable类的子类,它们的区别如下:
- 检查型异常(Checked Exceptions):
-
Exception分为检查型异常和非检查型异常。检查型异常是那些编译器要求必须处理的异常(通过throws声明或try-catch块),例如IOException。
- 非检查型异常(Unchecked Exceptions):
-
- 非检查型异常是那些编译器不强制要求处理的异常,通常是由于编程错误导致的,例如
NullPointerException或ArithmeticException。
- 非检查型异常是那些编译器不强制要求处理的异常,通常是由于编程错误导致的,例如
- 错误(Errors):
-
Error用于表示JVM无法处理的错误情况,通常是由于严重问题导致的,比如OutOfMemoryError或StackOverflowError。这些通常是由于资源不足、约束失败或内部错误导致的。
- 恢复可能性:
-
Exception通常被认为是可以被应用程序捕获并恢复的异常情况。Error通常表示严重问题,应用程序无法恢复或继续执行。
- 使用场景:
-
- 异常(
Exception)用于控制流中的异常情况,是程序正常运行时可能遇到的异常条件。 - 错误(
Error)通常用于指示不应该由应用程序捕获的严重问题,比如虚拟机的问题或系统问题。
- 异常(
- 处理方式:
-
- 异常(
Exception)应该被捕获并妥善处理,以避免程序异常终止。 - 错误(
Error)通常不被捕获,因为它们通常指示了无法恢复的情况。即使捕获了,通常也只是记录日志或做一些清理工作。
- 异常(
手撕题:
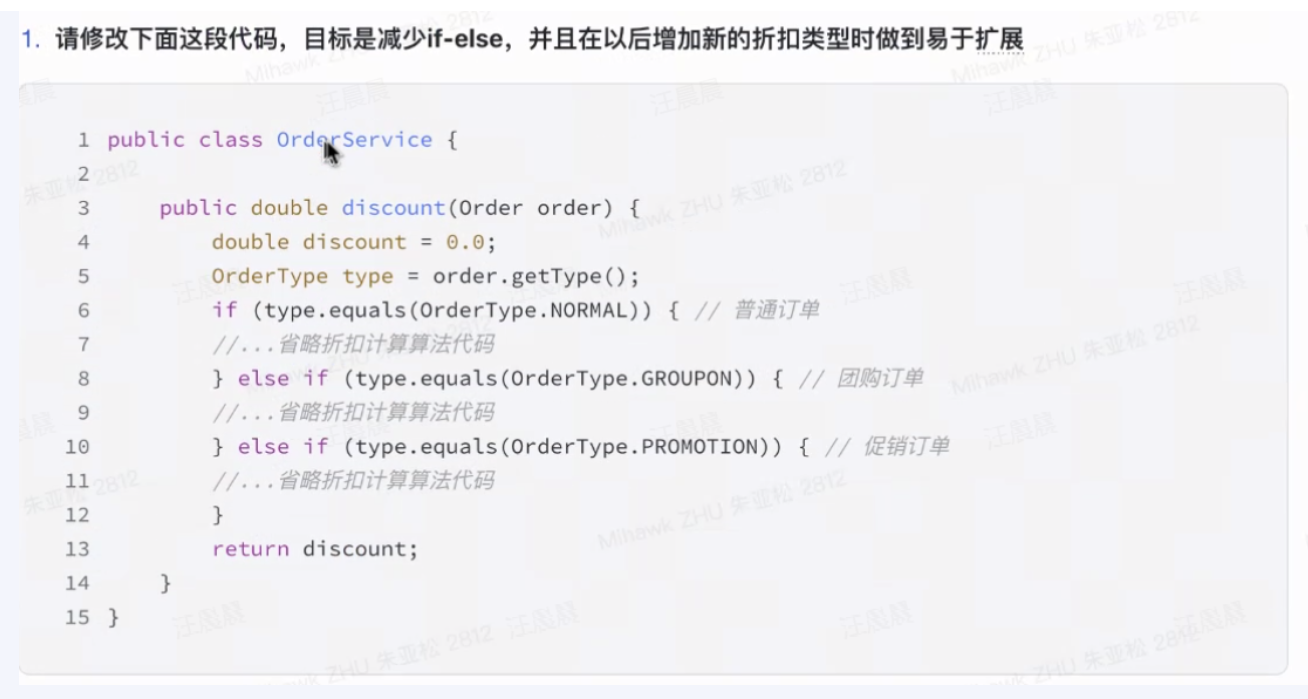
解答:
public class OrderServiceTest {
//订单服务类
class OrderService {
private HashMap<OrderType, DiscountStrategy> discountStrategies = new HashMap<>();
public OrderService() {
//注册不同的折扣策略
discountStrategies.put(OrderType.NORMAL, new NormalOrder());
discountStrategies.put(OrderType.GROUPON, new GroupOder());
discountStrategies.put(OrderType.PROMOTION, new PromotionOder());
}
public double discount(Order order) {
DiscountStrategy discountStrategy = discountStrategies.get(order.getType());
return discountStrategy.caculateDiscount(order);
}
}
//订单抽象策略
interface DiscountStrategy {
double caculateDiscount(Order order);
}
//普通订单具体策略类
class NormalOrder implements DiscountStrategy {
@Override
public double caculateDiscount(Order order) {
//普通订单折扣计算算法
return 0.0;
}
}
//团购订单具体策略类
class GroupOder implements DiscountStrategy {
@Override
public double caculateDiscount(Order order) {
//团购订单折扣计算算法
return 0.0;
}
}
//促销订单具体策略类
class PromotionOder implements DiscountStrategy {
@Override
public double caculateDiscount(Order order) {
//团购订单折扣计算算法
return 0.0;
}
}
}反问:自身的不足和缺点?
答:深度不够,停留在表面,很多细节的地方一笔带过。















 338
338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









