







DragGan
任务本质:图像编辑任务
目标:开发一种基于GAN的交互式图像处理方法,用户只需要点击图像来定义一些对(手柄点,目标点)或Mask,并驱动手柄点到达相应的目标点,给用户提供更加方便,更加准确的空间属性进行编辑的方式
当前问题:
1.传统的基于监督的学习方式
通过用户标注的图像标签,可以将图像的特定属性进行编辑,eg:将一个人脸变老

2.通过图像语义编辑的方式
用户只需要对语义图进行重新绘制,就可以改变图像生成的轮廓,这也是一种交互的编辑方式,eg:
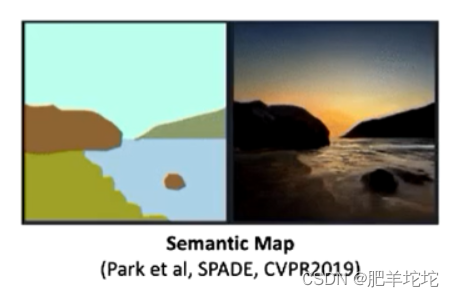
3.通过人体鲜艳进行图像编辑
用户通过改变人体的姿态就可以改变图像,eg:

4.基于文字的图像编辑
扩散模型的发展,基于文字的图像编辑成为热门,因为文字的灵活性,用户可以方便的对文字内容进行编辑,eg:给猫戴帽子、穿衣

以上几种方式都是在特定的问题上取得了成功的编辑效果,很多时候,用户其实希望对图像的空间属性进行编辑(类比现实中行为),传统的方法在编辑的灵活性、准确性及通用性方面都存在一定的限制。
所以作者希望提供一种更符合用户习惯,更方便、更准确的改变空间属性的编辑方式。
效果
方法
研究是基于StyleGan2体系结构,StyleGan2是StyleGan的升级版,StyleGan的前身是ProGan
Gan:
Gan,包含三个部分,生成、判别、对抗,其中**生成** 和**判别**是它的结构组成,对抗则是它的训练过程。
- 生成:生成 和 判别 指的是两个独立的神经网络模型,生成器用来捕获整个数据的分布,其实就是通过生成器去拟合和逼近真实的数据分布.
- 判别:判别器负责判断接受到的数据是否是真实的,即对生成数据进行**真伪鉴别**,试图正确识别所有假数据,它其实是一个二分类问题,会给出一个概率,代表着内容的真实程度;两者使用哪种网络并没有明确的规定,所以原文中作者称其为framework。比如可以使用擅长处理图片的CNN、常见的全连接等等,只要能够完成相应的功能就可以了。
- 对抗:这指的是 GAN 的交替训练过程。以图片生成为例,先让生成器产生一些假图片,和收集到的真图片一起交给辨别器,让它学习区分两者,给真的高分,给假的低分,当判别器能够熟练判断现有数据后;再让生成器以从判别器处获得高分为目标,不断生成更好的假图片,直到能骗过判别器,重复进行这个过程,直到辨别器对任何图片的预测概率都接近0.5,也就是无法分辨图片的真假,就停止训练。
在训练迭代的过程中,两个网络持续地进化和对抗,直到到达一个平衡状态,即判别网络无法识别真假。
我们训练GAN的最终目标就是合成与真实图像无法区分的人工样本。生成器的输入是一个随机向量(噪声),因此其初始输出也是噪声。随着训练的进行,当它收到鉴别器的反馈时,会学习合成更“真实”的图像。鉴别器还通过将生成的样本与真实样本进行比较,随着训练的进行不断改进,使得生成器更难欺骗它。
ProGan
ProGAN是NVIDIA投稿ICLR 2018的一篇文章,ProGAN关键创新在于渐进式训练,它在经典GAN的基础上首先通过学习在低分辨率图像中也可以显示的基本特征,来创建图像的基本部分,并且随着分辨率的提高和时间的推移,学习越来越多的细节。低分辨率图像的训练不仅简单、快速,而且有助于更高级别的训练,因此,整体的训练也就更快。ProGAN被认为是后来大热的StyleGAN的前身。
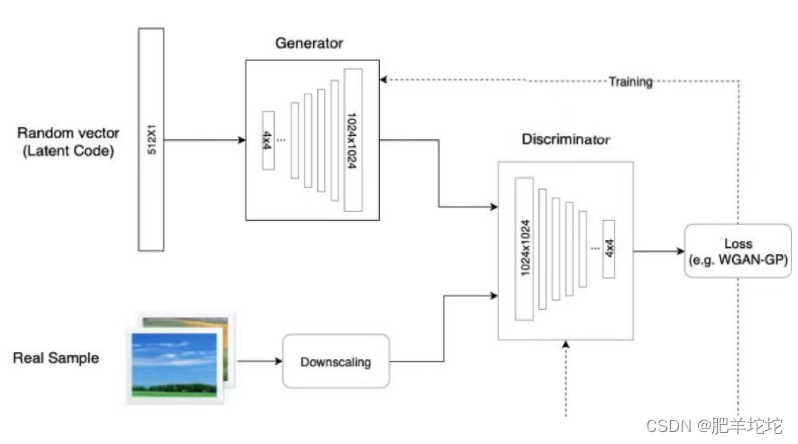
ProGAN的训练部分,从低分辨率的图像开始,通过向网络添加层来逐步提高分辨率,这种递增的性质允许训练首先发现图像分布的大规模结构,然后将注意力转移到越来越精细的细节上,而不是同时学习所有的尺度。使用生成器和鉴别器网络,它们是彼此的镜像,并且总是同步增长。在整个训练过程中,两个网络中的所有现有层都是可训练的。当新的层被添加到网络中时,平稳地将它们淡化,这就避免了对已经训练好的小分辨率层的突然冲击。
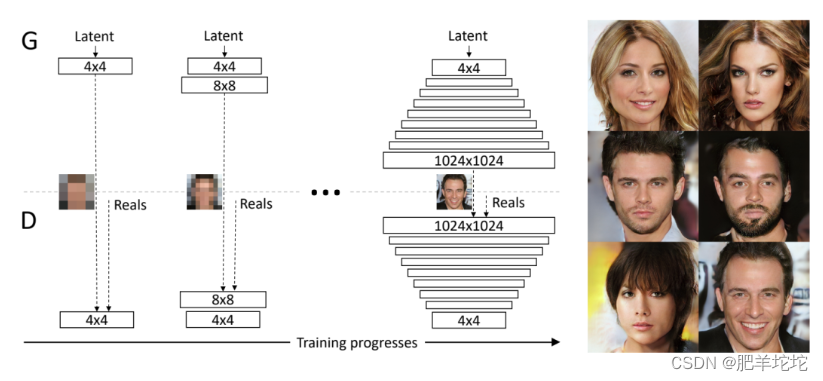 训练刚开始的时候,生成器(G)和判别器(D)的空间分辨率都很低,只有4x4像素。随着训练的进行,逐步增加G和D的层数,从而提高生成图像的空间分辨率。
训练刚开始的时候,生成器(G)和判别器(D)的空间分辨率都很低,只有4x4像素。随着训练的进行,逐步增加G和D的层数,从而提高生成图像的空间分辨率。
从16x16-32x32的过渡。
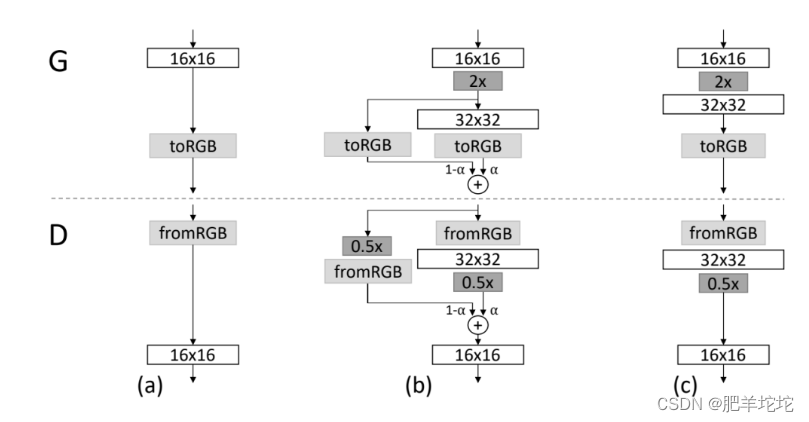
当生成器(G)和鉴别器(D)的分辨率翻倍时,顺利地淡化新层。这个例子说明了从16×16图像(a)到32×32图像(c)的过渡。在过渡期间(b),把在更高的分辨率上操作的层当作一个残差块,其权重α从0到1线性增加。
StyleGan系列模型都是一种无条件生成式模型,无条件生成是指从数据集中无条件地生成样本,即p(y);条件性图像生成是指根据标签有条件地从数据集中生成样本,即p(y|x)。
StyleGan
基本介绍
1.利用stylegan2生成的网红人脸(现实中不存在的假脸)

2.性别转换

3.人脸融合并作表情编辑
(此处省略gif图一张,是给一个人不笑的人加了一个微笑的表情)
- StyleGAN是ProGAN图像生成器的升级版本,重点关注生成器(G)
- StyleGAN中的**Style**是指数据集中人脸的主要属性,比如人物的姿态等信息,而不是风格转换中的图像风格,这里Style是指人脸的风格,包括了脸型上面的表情、人脸朝向、发型等等,还包括纹理细节上的人脸肤色、人脸光照等方方面面。
- StyleGAN 用风格(style)来影响人脸的姿态、身份特征等,用噪声 ( noise ) 来影响头发丝、皱纹、肤色等细节部分。
- 框架图:
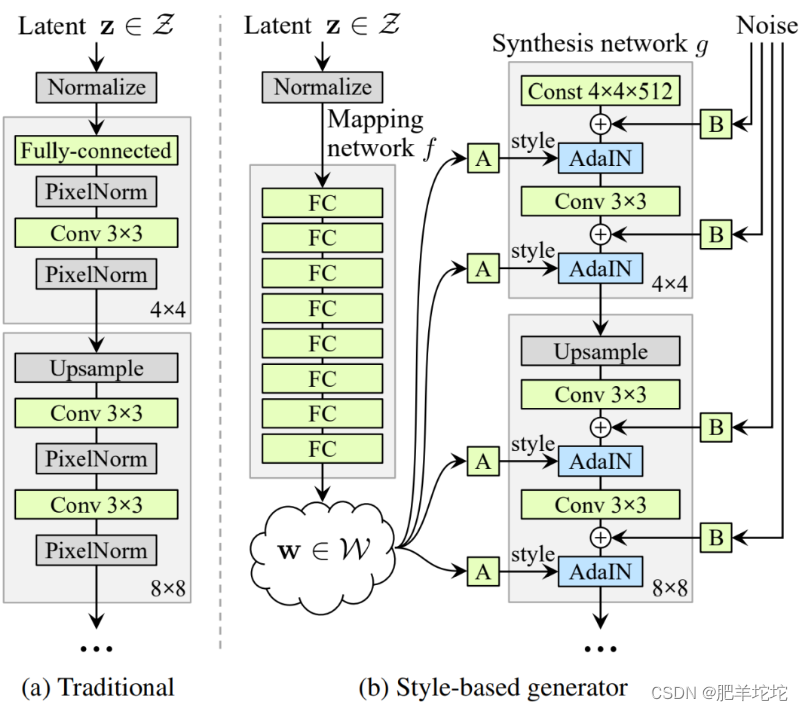
title: 框架图解读
在G部分主要被分为两个子网络:
- Mapping network:用于将隐变量z 转换成为 w,w用来控制生成图像的style
- Synthesis network : 用于生成图像
Mapping network
作用:为输入向量z的特征解耦提供一条学习通道
为什么需要z变成w
z通常是512位的符合均匀分布或者高斯分布的随机变量,所以变量之间的耦合性比较大,比如:头发长度和男子气概之间的相关关系,如果按照z的分布来看,这两个特征之间的关系会非常密切,头发长短会降低或增加男性特征,现实中的话,头发长短是不影响男性特征的,所以需要将z解耦,方便后面的操作,来改变不同的特征。
Mapping network需要做的事情就是对隐变量z解耦
将z转换得到w后,再将w通用一系列仿射变换生成A,将A分别送入Synthesis network的每一层子网络中,进行控制生成图像的style。
Mapping network特征
Mapping network是由8个全连接层组成,其输入层和输出层的大小相同。A是不同的8个控制向量,用来控制不同的视觉特征。
为什么Mapping network能够学习到特征解耦呢
如果仅使用z来控制视觉特征,那么其表现的就非常有限,因为它必须遵循训练数据的概率密度。比如,如果黑发人的图像在数据集中更常见,则更多输入值将映射到该特征。那么z中其他变量也会朝着这个特征靠近,无法更好的映射其他特征,这种现象被称为特征纠缠。所以,Mapping network可以生成一个不必遵循训练数据分布的向量w,减少特征之间的相关性,完成解耦。
Synthesis network
结构:
作用:生成图像
在Synthesis network中,最初的输入向量shape为 512 x 4 x 4,最后输出为 3 x 1024 x 1024。
从4x4 --> 8x8 -->16x16 --> ... -->1024x1024,其中每一个又包含2个卷积层(1个用于上采样,1个用于特征学习),所以一共包含18层,18=1(初始进入的conv层)+8x2(8个全连接层,每个又包含2个卷积层,将初始向量从4x4-->1024x1024)+1(结果层,to_rgb层,图像层)
删除了传统的输入
利用512x4x4的输入代替了传统的初始输入,好处是:
- 避免初始输入值取值不当而生成不正常的图片
- 有助于减少特征纠缠
随机变化(添加噪声noise)
- 之前有说,stylegan是通过噪声来影响头发丝、皱纹、肤色等细节问题。
- 脸上的小特征,比如雀斑、发髻线的准确位置,这些可以使图像更逼真,并增加输出的多样性。将这些小特征插入GAN图像的常用方法是向输入向量添加随机噪声noise。
- 为了控制噪声仅影响图片样式上细微的变化, StyleGAN 采用类似于 AdaIN 机制的方式添加噪声(噪声输入是由不相关的高斯噪声组成的单通道数据,它们被馈送到生成网络的每一层)。 即在 AdaIN 模块之前向每个通道添加一个缩放过的噪声,并稍微改变其操作的分辨率级别特征的视觉表达方式。 加入噪声后的生成人脸往往更加逼真与多样。
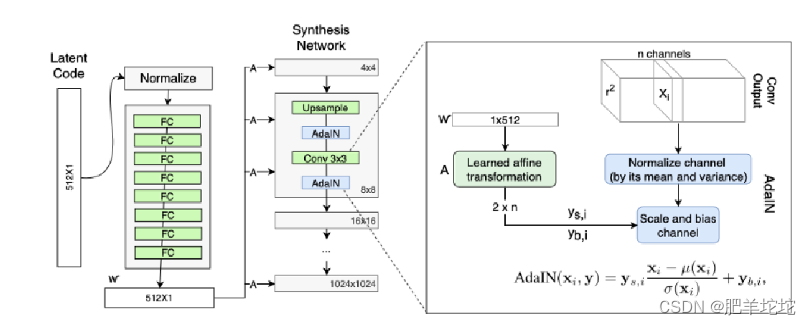
AdaIN(自适应实例归一化)
z得到w,然后w控制style嘛,就有了图片中y(ys,yb),再结合AdaIN就可以实现任意图像风格的转换,特征图的均值和方差中都会有图像的风格信息,所以,在这一层里,特征图减去自己均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,实现转换的目的。styleGan中的风格不是由图像得到的,而是w生成的。
样式混合
作用:进一步定位style(这个在训练过程中使用)
方法:混合正则化
具体操作:在训练过程中,使用2个w(不是1个)。通过Mapping network输入2个z,得到对应的w1和w2(代表2个style),然后利用其中随机的一个w切换到映射转换后来训练一些网络级别,然后用另一个w去训练其余的一些内容,然后混合就生成了既有A又有B的样式风格的新人脸。这种正则化技术可以防止网络假设相邻的风格是相关的。
大致就是:低分辨率的style控制姿态、脸型、配件,比如眼镜、发型等style,高分辨率的style控制肤色,头发颜色,背景色等style
- 针对特征解纠缠(disentanglement)问题
- 为了量化特征分离的表现,提出了量化两种特征分离的新方法:
- 感知路径长度:在两个随机输入之间插值时,测量连续图像之间的差异。剧烈的变化意味着多个功能一起发生了变化,它们可能会相互纠缠。
- 线性可分性:将输入分类为二元类的能力,如男性和女性。分类越好,特征越可分离。
- 为了量化特征分离的表现,提出了量化两种特征分离的新方法:
- 论文创新点
- 加入了可通用的Mapping network
- 样式混合,使用2个中间层的w生成一张图像,扩大了w的训练空间
- 提出了2种量化特征分离的方法(感知路径长度、线性可分性)
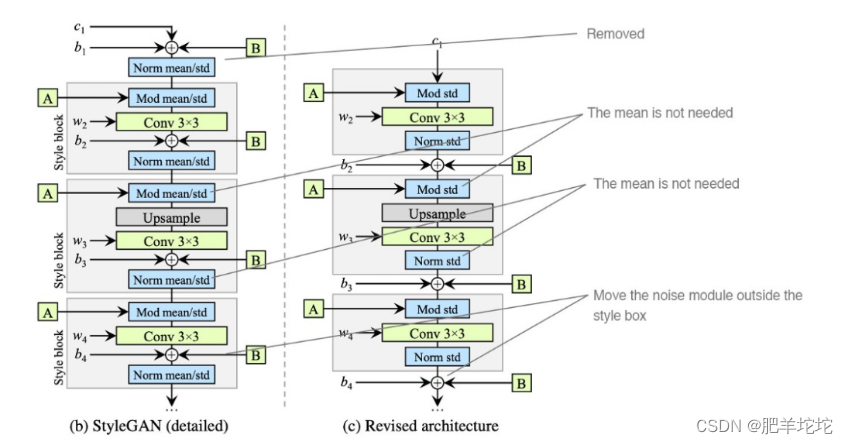
StyleGAN2
- StyleGAN2是为了应对StyleGAN的问题而提出的:少量生成的图片有明显的水珠(water-droplet artifacts),这个水珠也存在于feature map上。
- 导致水珠的原因是 AdaIN,AdaIN对每个feature map进行归一化,因此有可能会破坏掉feature之间的信息。

- 解决方法(重新设计synthesis network)
1. 移除最开始的数据处理
2. 在标准化特征的时候取消均值(均值取消就会噪声容易在样式混合的时候,将某一个特征放大一个数量级甚至更多,为了保留style mix,所以将AdaIN换成了Weight Demodulation,给他加权,根据传入的style对卷积的每个输入特征图进行缩放,或者通过缩放卷积权重来实现,这种方式使得训练加速了约40%)
3. 将噪声noise模块在外部style模块添加
DragGan
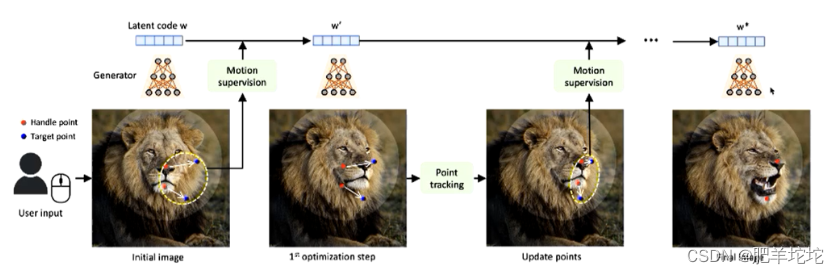
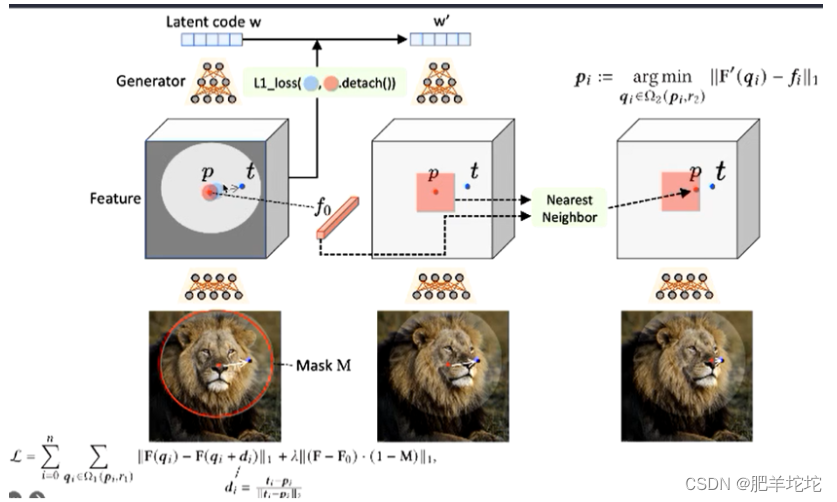
研究流水线
1. 生成器将隐向量映射到图片
2. 用户输入红色的抓取点和蓝色的目标点
3. Motion supervision:设计的一个将红色点拉拽到蓝色目标点的力,这个力就是运动监督的损失函数,用于优化隐向量w,然后就得到了一步优化后新的隐向量,新的隐向量再通过生成器生成新的图片,新图片会相较于旧图片发生一个变化,但是他朝那边运动,运动多少,都不知道,所以加入了点跟踪
4. 点跟踪,更新红色点的位置,让他随着目标物体移动,只有知道点运动到了哪里,最终才能精确的移动到蓝色点所在位置
5. 然后重复上面3,4进行运动监督和点跟踪,一直迭代,直到红色点运动到蓝色点的位置如何实现运动监督和点监督
初始方法
1. 作者最初是想着用光流去将红点移动到蓝点,因为光流是对运动最直观的捕捉
2. 生成器将隐向量w映射到一张图片,为了将红点推向蓝点,他将这张图片copy了一份,在复制的那张上,有一个用户输入的抓取点,将这两张图片送给一个光流预测网络,因为两张图是一样的,所以第一步的光流是(0,0),红点向左移动一步,那么就希望这个光流是能够获取到红点的运动轨迹,体现出相应的变化来,那么预期光流就是(-1,0),然后用目标光流来作为一个LOSS去优化w,通过几步优化,实现红点和蓝色方向重叠。
3. 目标是做一个交互式的东西,能够让用户及时看到效果,而这种基于光流预测网络是一个迭代式模型,效率不高,就不能及时反馈
4. 希望通过光流模型提取对图像对空间位置敏感的特征,然后通过这些特征对物体运动方向的监督最终方法
直接基于Gan自身的特征,因为这些特征有很强的耦合性,所以基于Gan的feature空间设计运动监督,这样就可以不要光流预测了,此外借助Gan feature本身对空间敏感的特性,也没有引入其他的点跟踪网络,都是在基于Gan自身上去做的。
1. 隐向量通过生成器生成的中间的feature space
2. 观察抓取点附近的一小块区域,红色点往目标点运动一小步,到了蓝色区域,把这一小步,数字话成了L1_loss这样子的损失函数,用红色区域的数值去优化蓝色区域,当蓝色区域的值都跟红色一样了,就可以说明红色点移动到了蓝色区域位置,因为希望是红色超蓝色方向运动的单向运动,所以红点到蓝色之后又把红点区域数值拿出来,再向蓝点移动一小步,通过这个运动监督的损失函数去优化隐向量。
3. Mask M的目的就是为了图片背景保持不变,运动监督损失函数只有话M之外的空间
4. 点跟踪,在红色附近直接找离原始抓取点最近的像素

论文创新点
1. 为点跟踪提供了一种新的思考途径
2. 可多点,对于密集性点同时编辑,效果也还不错
3. 反馈及时,生成的图像还挺准确
说明:文章中部分内容来自网络、公主号,但由于学习过程中,打开的链接太多,只摘抄了有助于个人理解的部分,对于链接没有着重记录,如有小伙伴对于引用个人成果介意,请联系我,同时请发送相关链接,比对内容后,会对引用重新做出说明,谢谢。
此外,封面图片来自DragGan论文作者潘新钢老师对该论文的视频分享中


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}