










股指与国家经济数学建模
原题再现
自1990年12月19日上海证券交易所挂牌成立,经过30年的快速发展,中国证券市场已经具有相当规模,在多方面取得了举世瞩目的成就,对国民经济的资源配置起着日益重要的作用。截至2019年年底,上海和深圳两个证券交易所交易的股票约4000种。目前,市场交易制度、信息披露制度和证券法规等配套制度体系已经建立起来,投资者日趋理性和成熟,机构投资者迅速发展已具规模,政府对证券市场交易和上市公司主体行为的监管已见成效。
随着近年来我国资本市场的发展和证券交易规模的不断扩大,越来越多的资金投资于证券市场,与此同时市场价格的波动也十分剧烈,而波动作为证券市场中最本质的属性和特征,市场的波动对于人们风险收益的分析、股东权益最大化和监管层的有效监管都有着至关重要的作用,因此研究证券市场波动的规律性,分析引起市场波动的成因,是证券市场理论研究和实证分析的重要内容,也可以为投资者、监管者和上市公司等提供有迹可循的依据。
问题一:投资者购买目标指数中的资产,如果购买全部,从理论上讲能够完美跟踪指数,但是当指数成分股较多时,购买所有资产的成本过于高昂,同时也需要很高的管理成本,在实际中一般不可行。
(1)在附件数据的分析和处理的过程中,请对缺损数据进行补全。
(2)投资者购买成分股时,过多过少都不太合理。对于附件的成分股数据,请您通过建立模型,给出合理选股方案和投资组合方案。
问题二:尝试给出合理的评价指标来评估问题一中的模型,并给出您的分析结果。
问题三:通过附件股指数据和您补充的数据,对当前的指数波动和未来一年的指数波动进行合理建模,并给出您合理的投资建议和策略。
附件:十支股票的相关重要参数。
先说一下对数据的处理 初步处理数据属性之间的关联性
问题分析
由于题目一中要求的是量化分析从2019年1月29日至2020年3月25日时间段题中所给十支股票每天的开盘价、最高价、最低价、收盘价、成交量数据,并根据分析数据结果预测2020年3月26日开盘价、最高价、最低价、收盘价得出2020年3月26日的成交量数据。投资者购买目标指数中的资产,如果购买全部,从理论上讲能够完美跟踪指数,但是当指数成分股较多时,购买所有资产的成本过于高昂,同时也需要很高的管理成本,在实际中一般不可行。但是由于投资者购买成分股时,过多过少都不太合理。对于附件的成分股数据,通过建立数学模型,给出合理选股方案和投资组合方案。因此,我们要具体分析附件中十支股票从2019年1月29日至2020年3月25日该段时间中哪一支股票波动大、哪一支股票稳定,使得股票购买投资合理。
通过筛选出大量数据,并运用现在已知道的数据通过拉格朗日插值预测的方法进行预测并绘制出相关模型线性回归曲线。
奖级评判模型(Award level evaluation model)来源于企业中的绩效评估模型,借助定量化的评分,考察定性指标之间的内在联系。为研究评估模型与最终指标数值之间的相关性,可以令评估标准总分作为输入变量,以最终指标数值作为输出变量,充分借助线性相关分析法,研究两者之间的定量关系。首先借助SPSS软件、MATLAB软件原始数据进行预处理,分别计算出十支股票所有指标平均分x_,均方差σ,标准分x;然后将标准分进行求和排序,获得前55%的股票发展较好情况;最后根据指标标准总分、最终模型进行纵向、横向分析,研究两者之间的相关性,并评价股票购买的可靠性。
为了更好的得出股票数据波动的原因,我们又将波动较大的6支股票价格数据用SPSS软件做出统计分析表。
十支股票的预测趋势 股盘交易图
问题一的分析
本题要求针对附件中的十只指数成分股相关数据进行预处理分析,主要包括异常值分析,缺失数据补齐等操作。并且利用预处理之后的数据进行建模,要求建立适当的数学模型来给出具体的投资组合方案,从尽可能的追踪指数,并且满足收益最大,风险最小的目标。
针对数据的预处理分析,本文首先选取一只股票进行相关参数的定性分析,主要分析该股票的波动趋势以及数据的分布状况。对于股票波动趋势的分析,可以通过添加趋势线来获取可视化的趋势分析。对于股票历史数据的预处理分析,本文主要通过箱线图分析进行异常值数据处理,对于缺损数据的补齐,常用的缺失值填充方法包括中位数填补,均值填补以及拟合插值填补。为了更加准确的进行缺失值数据的填补,本文考虑利用基于最大似然估计的 EM 算法来进行缺失值的填充。通过上述数据预处理步骤,我们利用预处理之后的股票相关数据建立投资组合模型。针对投资组合方案的选取,我们主要是根据附件十只股票数据来选取最佳的投资方案。对于投资组合方案的确定,本文可以通过建立组合优化模型来获取最佳的投资方案。一般来说,风险资产的投资首先需要解决的是两个核心问题:即预期收益与风险。如何测定组合投资的风险与收益和如何平衡这两项指标进行资产分配也是投资者迫切需要解决的问题。本文参考马科维茨理论,考虑证券组合预期收益、风险方差计算等建立了考虑一定收益水平下的均值-方差模型。由于马科维茨组合模型的主要目标是限制投资效用下的风险最小化。但是该模型需要设定一个投资收益率限制条件,因此本文考虑在马科维茨模型的基础上添加目标投资收益最大化,从而构建一个多目标优化模型。其中主要目标为投资风险方差最小化,投资收益最大化,比较重要的约束条件有每只股票投资比例大于等于 0,股票投资不可以卖空等。主要的决策变量为每只股票的投资占比。对于多目标优化模型的求解,可以利用线性加权,主要目标法等转化为单目标求解。但是考虑到转化为单目标求解,无法得到一个较好寻优结果,本文考虑利用遗传算法等启发式算法来寻优,从而尽可能的搜索到一个全局最优解。
问题二的分析
本题要求给出合理的评价指标来评估问题一的模型,主要是通过建立综合评价模型来评价问题一投资组合模型。对于合理的评价指标选取,我们通过选取一些针对优化模型的检验指标来进行综合评估。对于指标的选取,我们主要从三个方面来选取,分别是是模型的合理性,模型求解结果,模型可操作性等三个角度选取不同的评价指标。对于问题一模型的综合评估,我们可以根据相关指标数据来进行量化评分。但是考虑到很多评价指标无法获取量化数据,因此本文考虑构建一个层次结构模型,根据指标专家打分或者人为设定权重来评价问题一模型优劣。进一步根据利用模糊算子,基于最大隶属度原则,给出评价结果。通过层次结构模型确定目标权重,利用模糊评价法来获取针对问题一模型的定性评价。最终通过建立的模糊层次结构模型来获取最终的评价结果。对于评价目标,考虑到问题一针对投资组合方案建立的数学模型,我们可以抽出多个数学模型和本文建立的多目标优化模型进行评价对比,从而说明本文针对问题一建立
投资组合模型的优劣程度。
问题三的分析
本题要求利用附件一的相关数据,给出当前指数的波动情况。并且利用已有数据来预测未来一年的指数波动状况,从而给出一些合理的投资建议和策略。对于当前指数波动状况的分析,本文首先利用附件十只股票数据来量化一个股票综合指数,对于综合指数的量化,我们主要是利用十只成分股来集权计算出一个成分股指数。进一步针对该指数的变化趋势进行分析。而对于未来一年指数波动情况的预测,我们综合考虑指数波动的周期性,可以建立时间序列模型进行预测。对于时间序列预测模型,常用的包括自回归移动平均混合模型 ARIMA,指数平滑法等。我们考虑建立基于周期性变化的 Prophet 时间序列预测模型来预测未来的指数变化趋势,该模型参数设置简单,更加符合目前的时间序列建模趋势。为了重复说明时间序列预测指数波动的优越性,我们还建立了基于不同核函数的支持向量机回归(SVR)来验证 Prophet 时间序列预测的有效性。
模型的假设
1.假设购买股票期间经济政治始终稳定和平;
2.假设每支股票之间独立存在,互不影响;
3.假设该十支股票不存在破产倾覆的情况;
4.假设投资者的决定仅仅是依据证券的风险和收益,不考虑各种外界因素的影响;
5.假设在一定的风险水平上,投资者期望收益最大;相对应的是在一定的收益水平上,投资者希望风险最小;
6.假设投资者每一次投资选择的主要依据是某一时间内的证券收益的概率分布。
模型的建立与求解
附件一的成分股数据中包含了一共 10 只股票,我们首先针对单一股票的相关走势进行分析。我们首先给出了其中一只股票 abc001 所有参数随着时间的变化趋势,具体的走势如下:
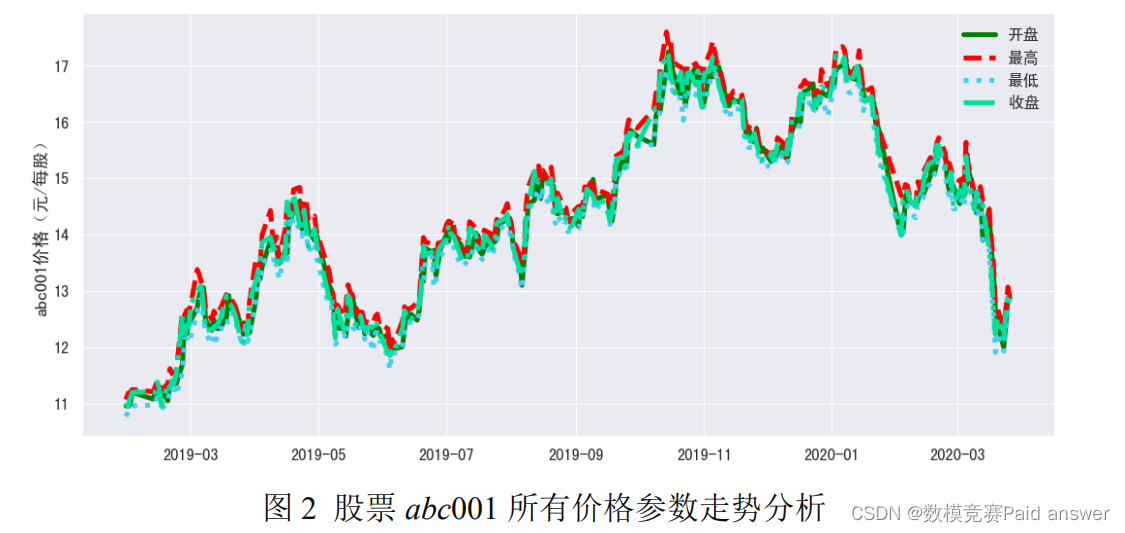
根据上图我们可以得到一只股票的开盘,最高,最低,收盘等参数的走势基本一致。因此本文后续主要针对股票的收盘价,成交量等参数进行分析。为了进一步验证相关参数走势基本一致的结论,本文利用皮尔逊相关性分析来研究各种参数之间的相关关系。为了进一步的分析变量之间的线性关系,我们利用清洗好的数据集进行线性相关性分析。根据数据得到相关系数矩阵,计算它们的相关系数矩阵[4]:
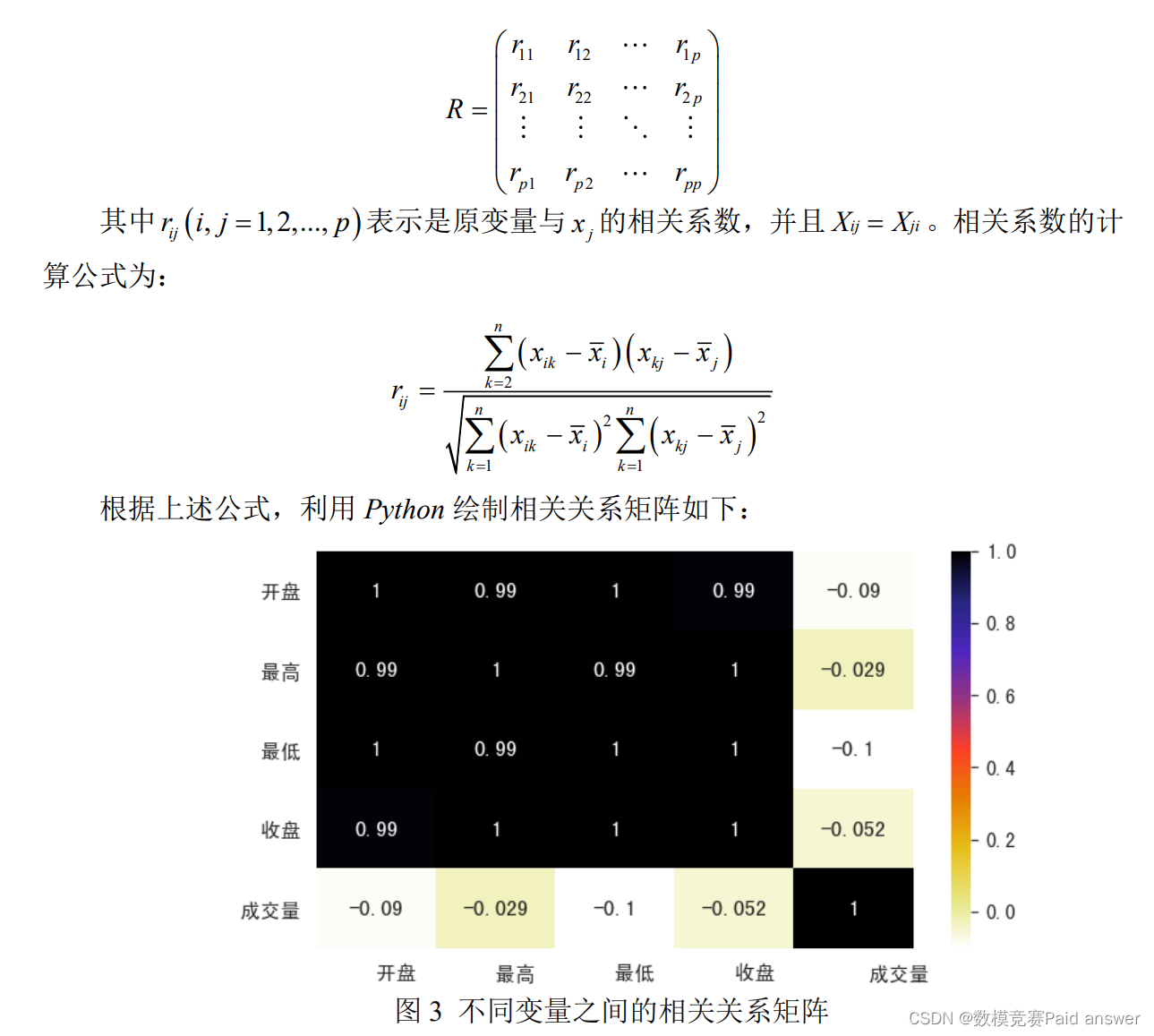
根据相关关系矩阵,我们可以看出开盘,最高,最低,收盘四个参数之间是一种显著正相关关系,相关系数在 0.99 以上,这也说明了四个参数趋势基本一致。进一步分析可以得到股票成交量和股票各种价格参数之间没有显著的相关关系,相关系数普遍低于0.1。为了进一步分析股票价格走势情况,我们主要针对收盘价和成交量进行分析。给出了
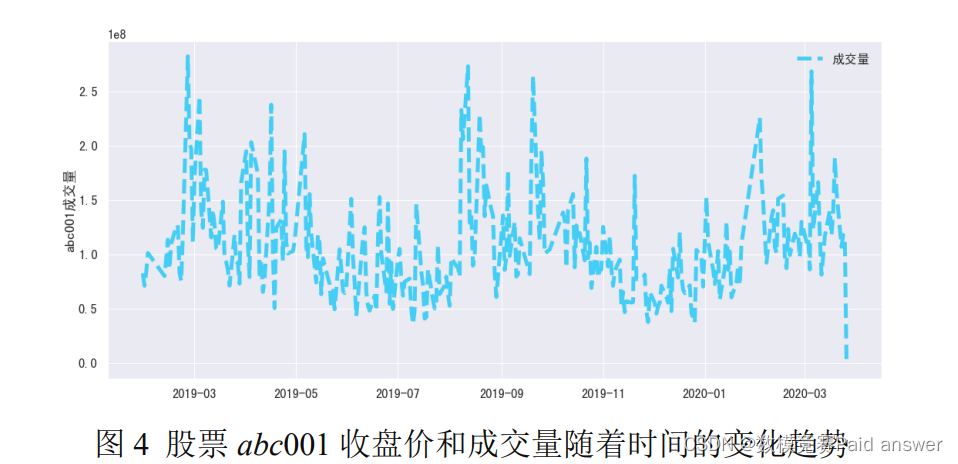
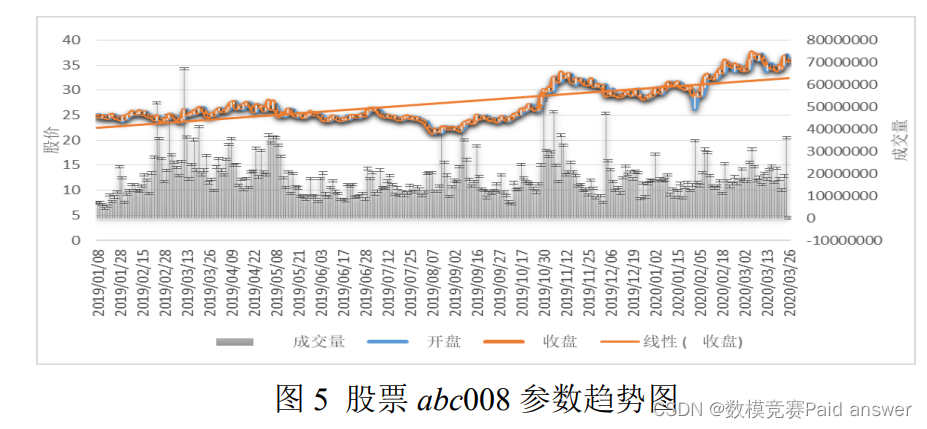
为了进一步分析股票收盘价与成交量指标,我们又给出了 abc008 相关参数指标随着时间的变化趋势。
中间过程太多 省略了。。。有想要的私信我
模型检验
首先分析模型的拟合效果误差,得到两种模型在测试集上的预测误差对比表如下

根据上表可以得到加权随机森林回归模型在已有数据集的测试上明显的比时间序列模型效果要差。这主要是因为时间序列建模虽然只能考虑单一时间维度要素,并且从中发现规律,但是因为考虑指数变化的周期性因此效果比较好。而且时间序列虽然能够
发现指数变化的一般趋势,但是对于短时间预测的效果较差,进行长期趋势预测效果很好。
本文建立的 Prophet 模型不仅可以考虑周期变化,而且还可以定量的计算这些指标对于预测结果的重要程度。可以说该模型是预测未来指数的一种较好方法。
模型优点
1.该模型运用的方法把研究对象作为一个系统,按照分解、比较判断、综合的思维方式进行决策。
2. 使复杂的系统分解,能将人们的思维过程数学化、系统化,便于人们接受,且能把多目标、多准则又难以全部量化处理的决策问题化为多层次单目标问题,通过两两比较确定同一层次元素相对上一层次元素的数量关系后,最后进行简单的数学运算。计算简便,并且所得结果简单明确,容易为决策者了解和掌握。
3. 该模型主要是从评价者对评价问题的本质、要素的理解出发,比一般的定量方法更讲求定性的分析和判断。由于层次分析法是一种模拟人们决策过程的思维方式的一种方法,层次分析法把判断各要素的相对重要性的步骤留给了大脑,只保留人脑对要素的印象,化为简单的权重进行计算。这种思想能处理许多用传统的最优化技术无法着手的实际问题。
模型缺点
1. 该模型只能为提供近期精准的预测结果,但是不能为长远问题提供其他的解决方案。
2. 当指标过多时,数据统计量大,且权重难以确定。
3.没有时间尝试更过的启发式算法对多目标优化模型进行寻优;
4.问题三针对成分股指数趋势预测,没有考虑一些特殊因素影响,只是单纯从时间角度出发;
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
import os
# sns.set(style="darkgrid") #这是 seaborn 默认的风格
mpl.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei',font_scale=1.5) # 解决 Seaborn 中文显示问题并调整字体大小
df = pd.read_excel('data/附件:十支股票参数.xlsx',encoding='utf_8',sheet_name='abc001')
df.head()
print(df.columns)
fig = plt.figure(figsize=(11, 6))
ax = fig.add_subplot(111)
# sns.heatmap(data.corr(), ax=ax, annot=True, linewidths=0.05, fmt= '.2f',cmap="magma")
print(df.iloc[:,1::].corr())
sns.set_context({"figure.figsize":(8,8)})
sns.heatmap(df.iloc[:,1::].corr(),annot=True,cmap="CMRmap_r")
df['date'] = pd.to_datetime(df['时间'])
df.set_index("date", inplace=True)
plt.figure(figsize=(18, 8))
plt.plot(df['开盘'], label='开盘', color='green', linestyle='-',linewidth = '5')
plt.plot(df['最高'], label='最高', color='red', linestyle='--',linewidth = '5')
plt.plot(df['最低'], label='最低', color='#44cef6', linestyle=':',linewidth = '5')
plt.plot(df['收盘'], label='收盘', color='#00e09e', linestyle='-.',linewidth = '5')
# plt.plot(df[' 时 间 '], df[' 现存疑似 '], label=' 现存疑似 ', color='#00e09e',
linestyle='-.',linewidth = '5')
#添加图例
plt.legend()
#添加网格
plt.grid(True)
print(type(df['时间']))
plt.ylabel("abc001 价格(元/每股)")
df.head()
df['date'] = pd.to_datetime(df['时间'])
df.set_index("date", inplace=True)
plt.figure(figsize=(18, 8))
plt.plot(df['收盘'], label='收盘', color='#00e09e', linestyle='-',linewidth = '5')
plt.ylabel("abc001 收盘价格(元/每股)")
#添加图例
plt.legend()
df['date'] = pd.to_datetime(df['时间'])
df.set_index("date", inplace=True)
plt.figure(figsize=(18, 8))
plt.plot(df['成交量'], label='成交量', color='#44cef6', linestyle='--',linewidth = '5')
plt.ylabel("abc001 成交量")
#添加图例
plt.legend()
#实验样本索引查看
df1 =df.iloc[:,1:-1]
#实验数据导出
# df1.to_csv('C:/Users/13109/desktop/df1.csv',encoding="gb2312")
#绘制原始的箱线图,并返回异常值字典
p = df1.plot.box(sym='r+',return_type = 'dict')
df0 = pd.read_excel('data/附件:十支股票参数.xlsx',encoding='utf_8',sheet_name='汇总')
df0.head()
print(df0.columns)
df0
df_shoupan = df0.loc[:,['时间','abc001 收盘','abc002 收盘','abc003 收盘','abc004 收盘
','abc005 收盘','abc006 收盘','abc007 收盘','abc008 收盘','abc009 收盘','abc010 收盘']]
df_shoupan['date'] = pd.to_datetime(df_shoupan['时间'])
df_shoupan.set_index("date", inplace=True)
df_shoupan.head()
df_shoupan.plot(figsize=(18, 8),linewidth = '3')
plt.ylabel('十只股票的收盘价')
plt.xlabel('')
plt.show()
df_cheng.plot(figsize=(18, 8),linewidth = '3')
plt.ylabel('十只股票的成交量走势')
plt.xlabel('')
plt.show()
fig, ax = plt.subplots(1, 2, figsize=(18,4))
time_val = df['收盘'].values
sns.distplot(time_val, ax=ax[0], color='r')
ax[0].set_title('收盘价分布趋势', fontsize=14)
ax[1].set_xlim([min(time_val), max(time_val)])
sns.distplot(np.log(time_val), ax=ax[1], color='b')
ax[1].set_title('收盘价对数分布趋势', fontsize=14)
ax[1].set_xlim([min(np.log(time_val)), max(np.log(time_val))])
plt.show()
#导入依赖库
import pandas as pd
from scipy import stats
#绘制并打印 QQ 图
fig, ax = plt.subplots(1, 2, figsize=(18,4))
stats.probplot(df['收盘'], dist="norm",plot=ax[0])
ax[0].set_title('abc001 收盘价正态分布检验 qq 图', fontsize=14)
stats.probplot(df['成交量'], dist="norm",plot=ax[1])
ax[1].set_title('abc001 成交量价正态分布检验 qq 图', fontsize=14)
plt.show()
df_avg = df_shoupan.resample('m')['abc001 收盘','abc002 收盘','abc003 收盘','abc004 收盘
','abc005 收盘','abc006 收盘','abc007 收盘','abc008 收盘','abc009 收盘','abc010 收盘'].mean()
# df_avg[['abc001 收盘','abc002 收盘']].apply(lambda x: (x - np.min(x)) / (np.max(x) -
35
np.min(x))) ##对每一列数据标准化
def calculate_rate(df_avg):
rate_data = pd.DataFrame()
for j in range(10):
rate_list = []
for i in range(len(df_avg)-1):
rate = (df_avg.iloc[i+1,j]-df_avg.iloc[i,j])/df_avg.iloc[i,j]
rate_list.append(rate)
rate_data['abc00'+str(j+1)] = rate_list
# rate_data['date'] = pd.date_range('2019-2', '2020-4',freq='M')
rate_data.set_index(pd.date_range('2019-2', '2020-4',freq='M'), inplace=True)
# print(rate)
return rate_data
rate_data = calculate_rate(df_avg)
rate_data
rate_mean = rate_data.mean()
# rate_data.to_csv('data/question1/十只股票月平均收益率.csv',encoding='utf_8_sig')
# rate_mean.to_csv('data/question1/十只股票的综合平均收益率.csv',encoding='utf_8_sig')
# rate_df = pd.DataFrame(rate_mean)
rate_mean
df_cumulate = pd.DataFrame()
df_cumulate['综合平均收益率']=rate_mean.sort_values(ascending=False)
df_cumulate
f,ax=plt.subplots(figsize=(8,8))
sns.barplot(y=df_cumulate.index,x =df_cumulate[' 综 合 平 均 收 益 率
'],data=df_cumulate,palette='cubehelix',
ax=ax,ci=85,errcolor='yellow', errwidth=5, capsize=0.1,alpha=0.7)
dd = df_shoupan[['abc001 收盘','abc002 收盘','abc003 收盘','abc004 收盘','abc005 收盘
','abc006 收盘','abc007 收盘','abc008 收盘','abc009 收盘','abc010 收盘']].var()
# df_avg[['abc001 收盘','abc002 收盘']].apply(lambda x: (x - np.min(x)) / (np.max(x) -
np.min(x))) ##对每一列数据标准化
df_var = pd.DataFrame()
df_var['十只股票的波动方差']=dd.sort_values(ascending=False)
# df_var.loc['abc007 收盘','十只股票的波动方差']=506.4598
36
df_var.to_csv('data/question1/十只股票的波动方差.csv',encoding='utf_8_sig')
df_var
f,ax=plt.subplots(figsize=(8,8))
sns.barplot(y=df_var.index,x =df_var[' 十 只 股 票 的 波 动 方 差
'],data=df_var,palette='cubehelix',
ax=ax,ci=85,errcolor='yellow', errwidth=5, capsize=0.1,alpha=0.7)
df_cm = pd.DataFrame()
df_cm['十只股票的平均成交量']=df_cheng[['abc001 成交量','abc002 成交量','abc003 成交
量','abc004成交量','abc005成交量','abc006成交量','abc007成交量','abc008成交量','abc009
成交量','abc010 成交量']].mean()
# df_var.loc['abc007 收盘','十只股票的波动方差']=506.4598
df_cm.to_csv('data/question2/十只股票的平均成交量.csv',encoding='utf_8_sig')
f,ax=plt.subplots(figsize=(8,8))
sns.barplot(y=df_cm.index,x =df_cm[' 十 只 股 票 的 平 均 成 交 量
'],data=df_cm,palette='cubehelix',
ax=ax,ci=85,errcolor='yellow', errwidth=5, capsize=0.1,alpha=0.7)
df_cm
df_cmrate = df_cm.apply(lambda x:x/sum(x))
df_cmrate.to_csv('data/question2/十只股票的平均成交量占比.csv',encoding='utf_8_sig')
df_cmrate
np.dot(df_shoupan.iloc[:,1:].values,df_cmrate.values)
df_shoupan['成分股指数'] = np.dot(df_shoupan.iloc[:,1:11].values,df_cmrate.values)
df_shoupan.to_csv('data/question3/成分股综合指数计算结果.csv',encoding='utf_8_sig')
df_shoupan.head()
如果想用matlab做的建议使用拉格朗日,我此处给个程序仅供参考:
function f = Lagrange(x,y,x0)
%求已知数据点的拉格朗日多项式
%x是已知数据点的x坐标向量
%y是已知数据点的y坐标向量
%x0为插值点的x坐标
%f为求得的拉格朗日多项式或x0出的插值
syms t;
if(length(x)==length(y))
n=length(x);
else
disp('x和y的维数不相等!');
return;
end %检错
f=0.0;
for (i=1:n)
l=y(i);
for (j=1:i-1)
l=l*(t-x(j))/(x(i)-x(j));
end;
for(j=i+1:n)
l=l*(t-x(j))/(x(i)-x(j));%计算拉格朗日基函数
end;
f=f+l; %计算拉格朗日插值函数
simplify(f); %化简
if(i==n)
if(nargin==3)
f=subs(f,'t',x0); %计算插值点的函数值.subs是替换函数,吧x0用t替换
else
f=collect(f); %将插值多项式展开
f=vpa(f,6); %将插值多项式的系数化成6位精度的小数
end
end
end

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









