









2021中青杯C题
在线教学的分析与研究
随着教育信息化的发展,在线教学与传统教学深度融合已成为必然趋势。多媒体课件的展示,或MOOC教学在高校中已经是非常常见的一种教学模式。在线教学智能教室的建设,正在不断颠覆传统的教学模式和方法。

在线教学是在一定教学理论和思想指导下,应用多媒体和网络技术来完成教学的一中教学方式,该技术需要通过借助多媒体教学信息来实现教学目标。近年来,在线教学不断发展,打破了传统教学受地点和空间的约束,因此受到了很大一部分学生的喜爱。值得思考的是,在线教学虽然时间和空间相对自由,但老师却很难对学生进行管控,为了更好的提高教学质量,请结合提供的附表并设计相关问卷调查,收集另需的相关数据,完成下列各题。
1.问题一:请你选择一个学校,根据学校现有的教学资源,建立合适的数学模型,给出一种组合式教学方案,并预估该方案的实施效果。
2.问题二:由于城乡之间的教学资源相差较大,而在线教学则不受空间地域的限制,请你建立合适的数学模型,分析在线教学如何在乡村地区进行实施,并根据你研究的成果,给教育部门写一封建议信。
3.问题三:基于你的研究成果,分析面对市场上多样化的资源工具和平台,如何选择正确的教学模式,利用合适的教学平台,做好网络教学工作。
问题求解
在对题目中所给数据进行分析时,我们首先要对数据进行处理,将原数据矩阵转置并通过python读取,读取后的数据由图1图2所示:
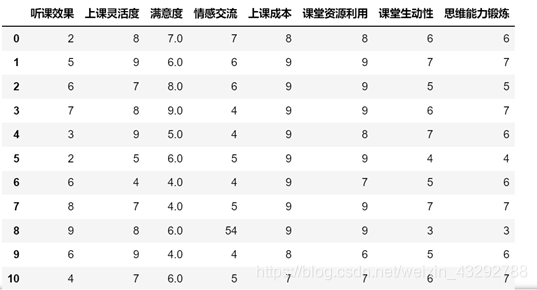
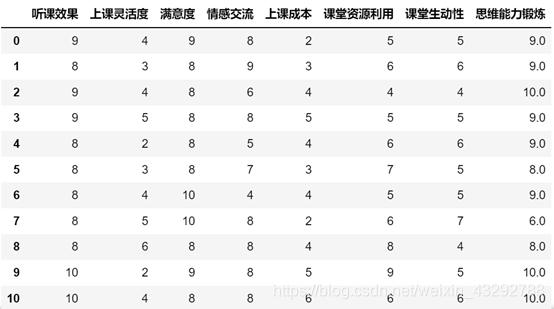
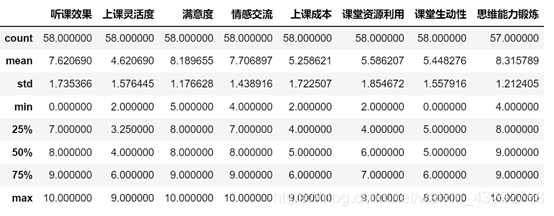
由我们读取的数据及题中所给要求可知,该数据值范围应为0~10,由该限制条件,我们将原数据进行清洗,删掉互联网教学表中情感交流数值为54的数据,数据处理完成后,通过python中的不告诉你函数,我们查看互联网教学及传统教学数据的波动情况及8种上课效果对比情况。
import copy
minsupport = 2
# 最小支持度的频数
# 除去子集不是频繁项集的候选项集
# word or pdf
def subset(sen_c_items, item):
sub_set = []
for i in sen_c_items:
candidate = set(i)
# 将K-1项集中的候选项变成集合形式
t_record = set(item)
# 将交易数据库中的数据项变成集合形式
if candidate.issubset(t_record):
sub_set.append(i) # 保留子集部分
return sub_set
# 找出K项候选集
def apriori_gen(sub_k_items, n):
sen_k_items = set([])
for p in range(len(sub_k_items)):
for q in range(p + 1, len(sub_k_items)):
flag = True
p_item = list(sub_k_items[p])
q_item = list(sub_k_items[q])
for i in range(n):
if p_item[n - 1] == q_item[n - 1]:
flag = False
break
elif p_item[i] != q_item[i] and i < n-1:
flag = False
if flag:
c = list(sub_k_items[p] + q_item[n - 1]) # 将q中的最后一项添加到p中
c.sort()
if has_frequent_subset(c, sub_k_items, n):
c = "".join(c)
sen_k_items.add(c)
print("候选", n + 1, "-项集:", sorted(sen_k_items))
return sen_k_items
def has_frequent_subset(c, freq_items, n):
num = len(c) * n
count = 0
flag = False
for c_item in freq_items:
if set(c_item).issubset(set(c)):
count += n
if count == num:
flag = True
return flag
# 剔除不频繁的项集
def op_freq_item(d):
for item in list(d.keys()):
if d[item] < minsupport:
del d[item]
l = sorted((d.keys()))
return l
if __name__ == '__main__':
dataset = ["ABCD", "BCE", "ABCE", "BDE", "ABCD", ]
d = {}
for t in dataset: # 挑选频繁1项集
for index in range(len(t)):
if t[index] in d:
d[t[index]] += 1
else:
d[t[index]] = 1
l1 = op_freq_item(d) # 剔除不符合的1项集
sub_c_items = l1
c_items_freq = {} # 用于存放K-1候选项集,并统计其出现的频数
freq_items = [sub_c_items] # 保存频繁项集
n = 0
while True:
n += 1
print("寻找", n + 1, "-候选项集")
sen_c_items = list(apriori_gen(sub_c_items, n)) # 找到K项集 sen_c_items
for t in dataset:
k_subset = sorted(subset(sen_c_items, t)) # 获取K项集包含候选项集的item的子集 new_c_item
print(t, "的子集:", k_subset)
for c_item in k_subset:
if c_item in sen_c_items and c_item in c_items_freq:
c_items_freq[c_item] += 1 # 找到了加1
else:
c_items_freq[c_item] = 1 # 未找到则创建并初始数量为1
print("待挑选的频繁:", c_items_freq)
if len(op_freq_item(c_items_freq)):
sub_c_items = op_freq_item(c_items_freq) # 选出K-1候选项集
freq_items.append(sub_c_items) # 将频繁K项集加入频繁项集freq_items中
print(sub_c_items)
else:
break
c_items_freq.clear() # 清楚字典里的元素
print()
print("频繁项集:", freq_items)
问题二模型的建立与求解
使用Apriori算法来解决
一般来说,支持度高的数据不一定构成频繁项集,但是支持度太低的数据肯定不构成频繁项集。
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。如果我们有两个想分析关联性的数据X和Y,X对Y的置信度为
Confidence(X⇐Y)=P(X|Y)=P(XY)/P(Y)
Confidence(X⇐Y)=P(X|Y)=P(XY)/P(Y)
也可以以此类推到多个数据的关联置信度,比如对于三个数据X,Y,Z,则X对于Y和Z的置信度为:
Confidence(X⇐YZ)=P(X|YZ)=P(XYZ)/P(YZ)

问题三求解:
基于问题一、问题二建立的数据模型及所得结论,已得出正确的教学模式:针对于不同课程,比如说数学、物理注重思维能力锻炼的一定要采用传统教学、针对于化学、物理、美术、音乐注重课堂互动实验的课程要采取传统教学,针对于自习、培养独立完成能力的课程采用互联网教学,针对于英语听力、口语能力培养的课程。接下来的任务为分析如何利用市场上多样化的资源工具和平台,做好网络教学工作。


















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









