









 本文探讨了数学建模中数据可视化的关键作用,通过散点图、直方图和饼形图的实例展示了如何增强文章的视觉效果。利用matplotlib库创建了不同类型的图表,如散点图用于展示数据随时间的变化趋势,直方图用于描绘数据分布,饼形图则用于比例和分类数据的展示。这些图形有助于读者更好地理解和解读模型结果。
本文探讨了数学建模中数据可视化的关键作用,通过散点图、直方图和饼形图的实例展示了如何增强文章的视觉效果。利用matplotlib库创建了不同类型的图表,如散点图用于展示数据随时间的变化趋势,直方图用于描绘数据分布,饼形图则用于比例和分类数据的展示。这些图形有助于读者更好地理解和解读模型结果。
数学建模中极为重要的一点
数据可视化
说白了就是为了使整篇数学建模文章中富有颜色色彩,使得整个文章好看赏心悦目,不那么单调。因此才需要有分析图的陪衬才能使让评委给你高分,一般一篇文章中绘制5至8个图不等。
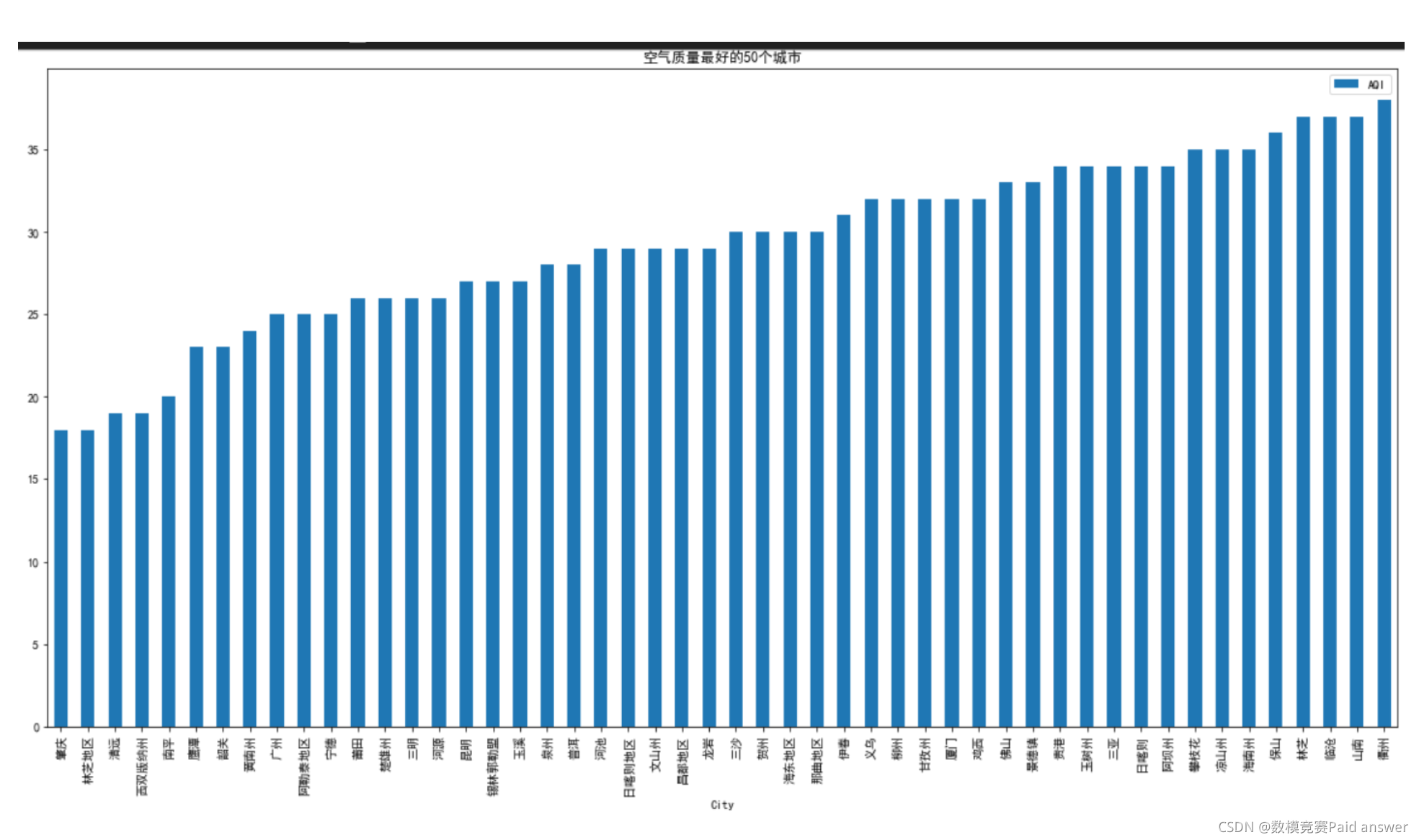
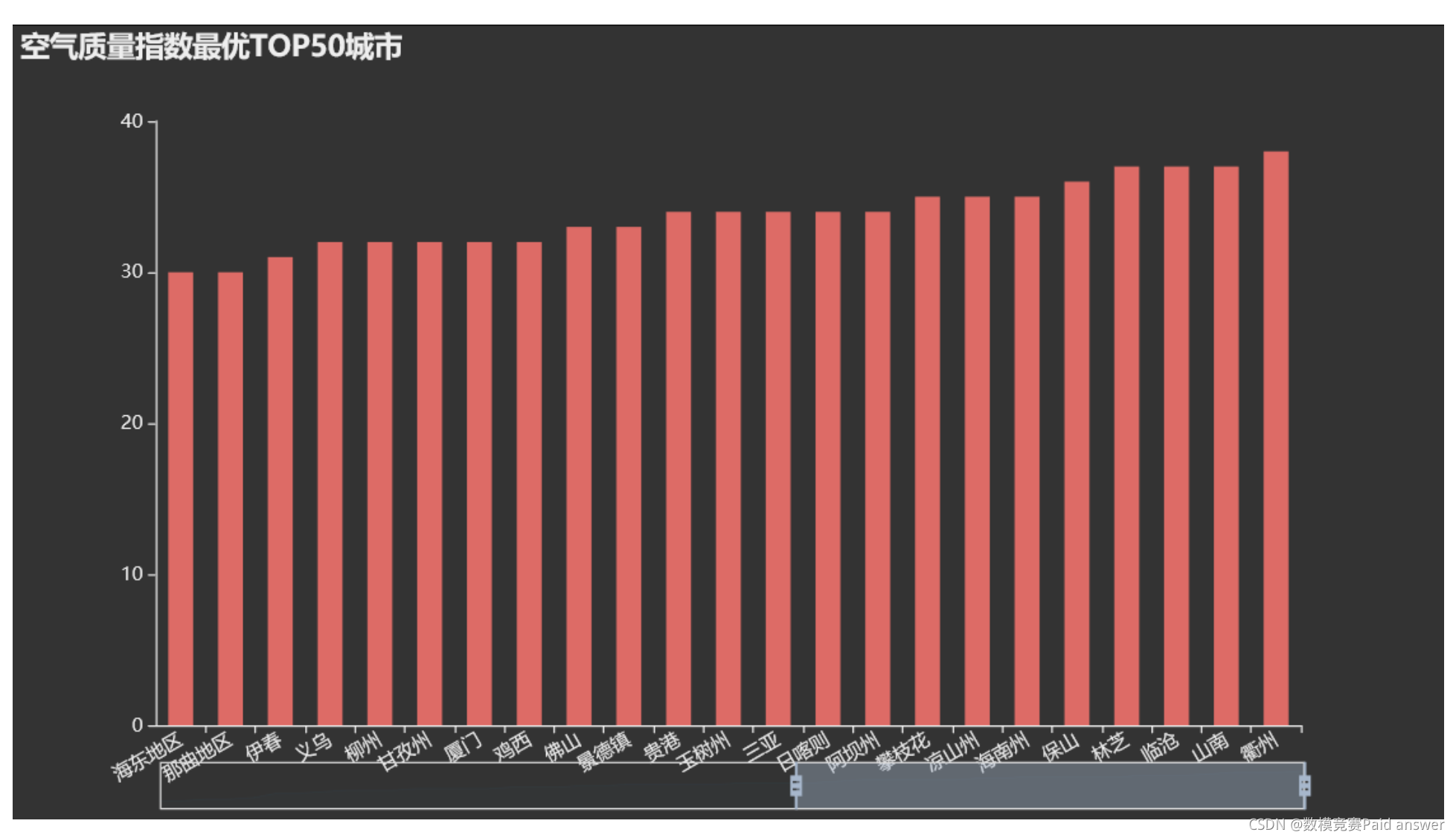
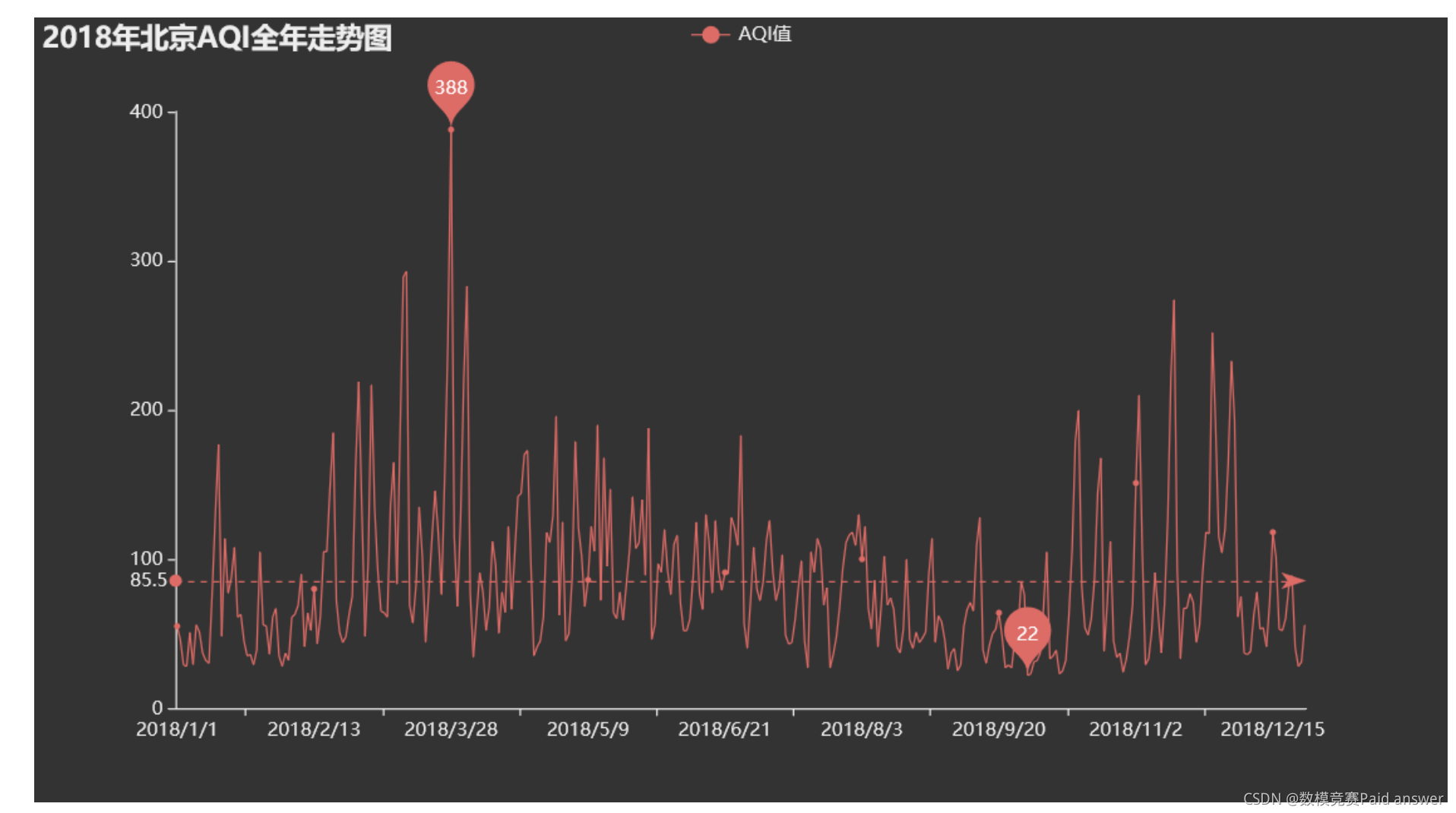
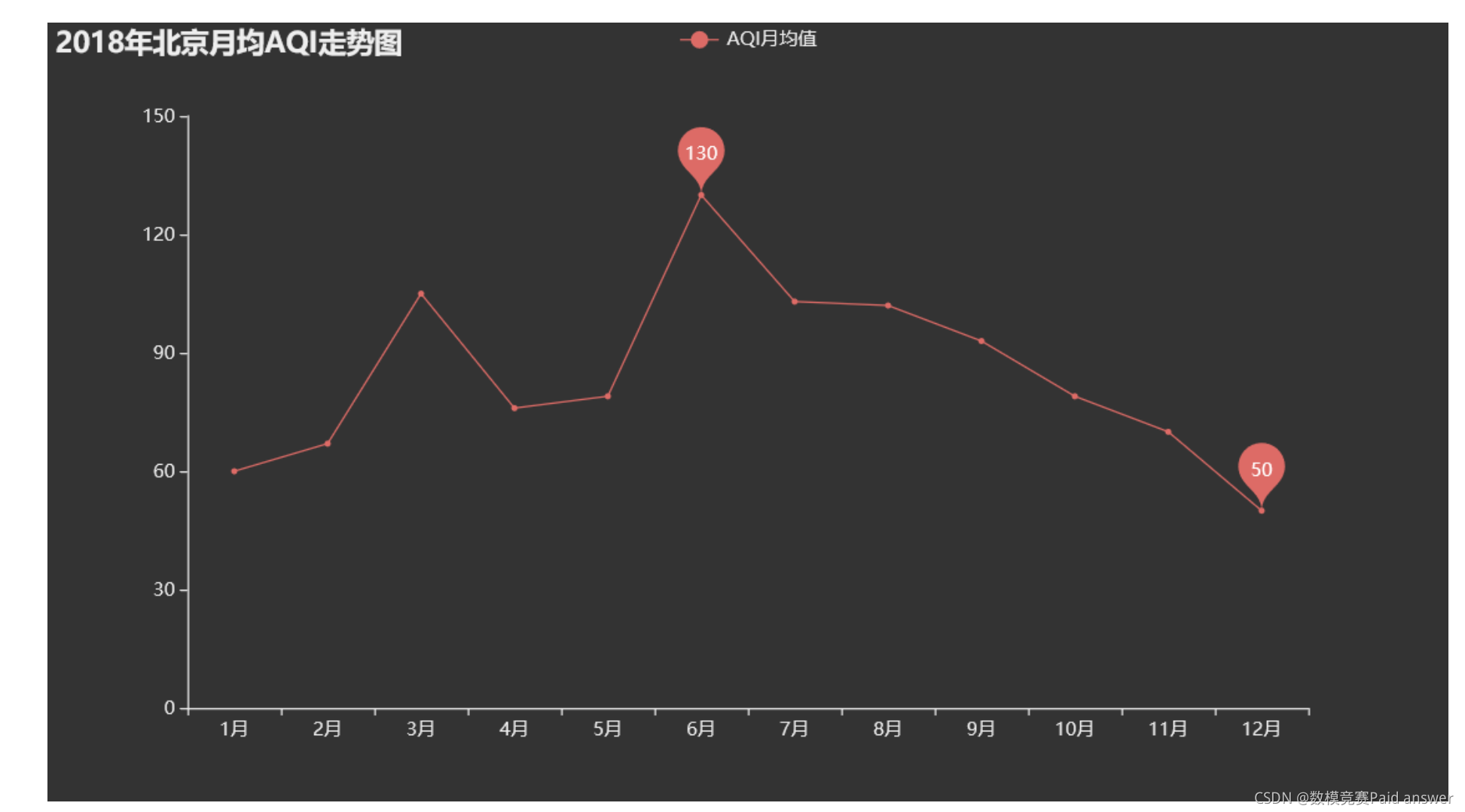

散点图程序
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
print df
years=df.index.values
counts=df['trans_count'].values
gpu_counts=df['gpu_counts'].values
cnt_log=np.log(counts)
plt.scatter(years,cnt_log,c=200*years,s=20+200*gpu_counts/gpu_counts.max(),alpha=0.5) #表示颜色,s表示标量或数组
plt.show()
直方图程序
from matplotlib import pyplot as plt
'''
count of Petal width
'''
file=open("../dataset/iris.txt", "r")
content = [x.rstrip("\n") for x in file]
file.close()
d_sl=[]
while '' in content:
content.remove('')
data_slength = [x.split(',')[3] for x in content[0:]]
while '' in data_slength:
data_slength.remove('')
for i in data_slength:
d_sl.append(float(i))
plt.hist(d_sl,10,alpha=0.5)
plt.xlabel("Petal width")
plt.ylabel("count")
plt.show()
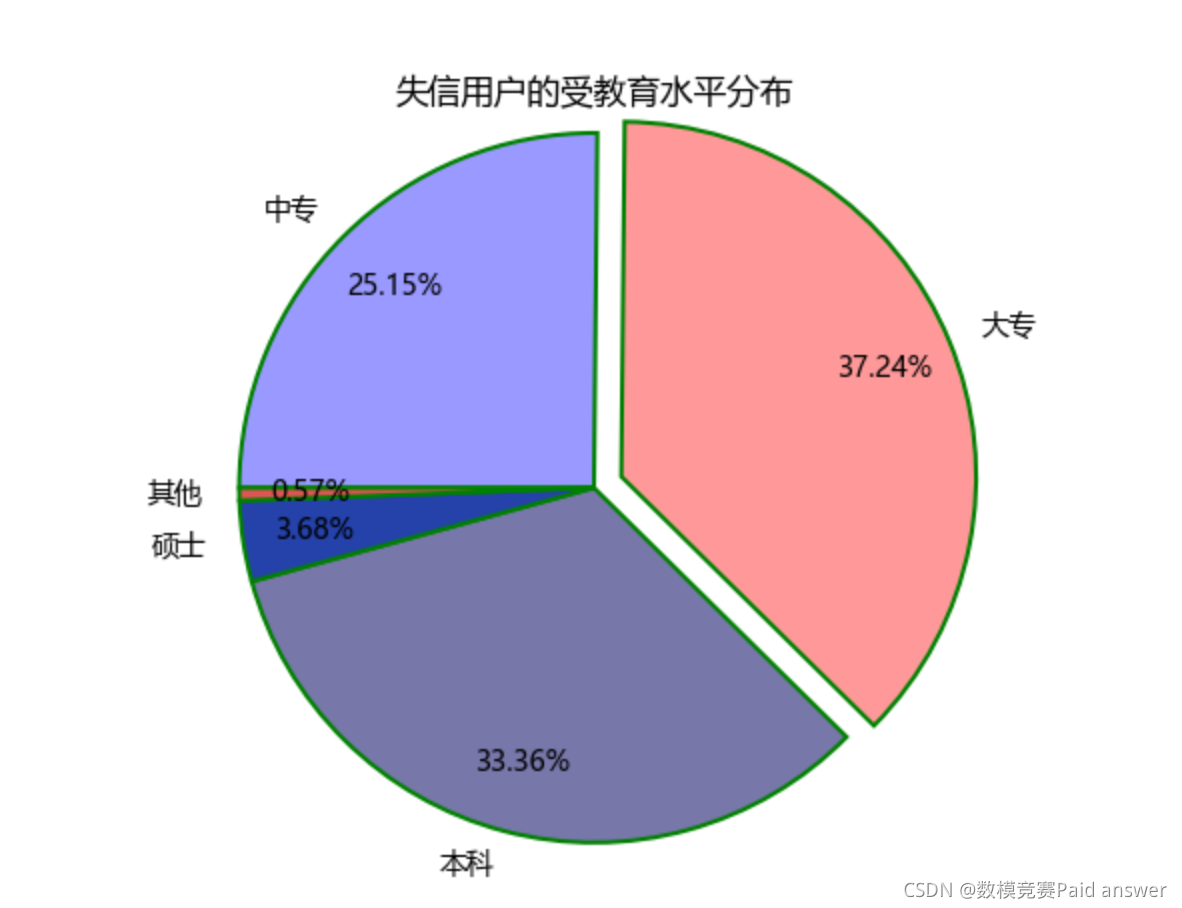
饼形图程序
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Microsoft YaHei'] #显示中文标签,处理中文乱码问题
plt.rcParams['axes.unicode_minus']=False #坐标轴负号的处理
plt.axes(aspect='equal') #将横、纵坐标轴标准化处理,确保饼图是一个正圆,否则为椭圆
#构造数据
edu = [0.2515, 0.3724, 0.3336, 0.0368, 0.0057]
labels = ['中专','大专','本科','硕士','其他']
explode = [0, 0.1, 0, 0, 0] #生成数据,用于凸显大专学历人群
colors = ['#9999ff', '#ff9999', '#7777aa', '#2442aa', '#dd5555'] #自定义颜色
plt.pie(x=edu, #绘图数据
explode=explode, #指定饼图某些部分的突出显示,即呈现爆炸式
labels=labels, #添加教育水平标签
colors=colors,
autopct='%.2f%%', #设置百分比的格式,这里保留两位小数
pctdistance=0.8, #设置百分比标签与圆心的距离
labeldistance=1.1, #设置教育水平标签与圆心的距离
startangle=180, #设置饼图的初始角度
radius=1.2, #设置饼图的半径
counterclock=False, #是否逆时针,这里设置为顺时针方向
wedgeprops={'linewidth':1.5, 'edgecolor':'green'}, #设置饼图内外边界的属性值
textprops={'fontsize':10, 'color':'black'}, #设置文本标签的属性值
)
#添加图标题
plt.title('失信用户的受教育水平分布')
#显示图形
plt.show()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









