









1. 数据分析
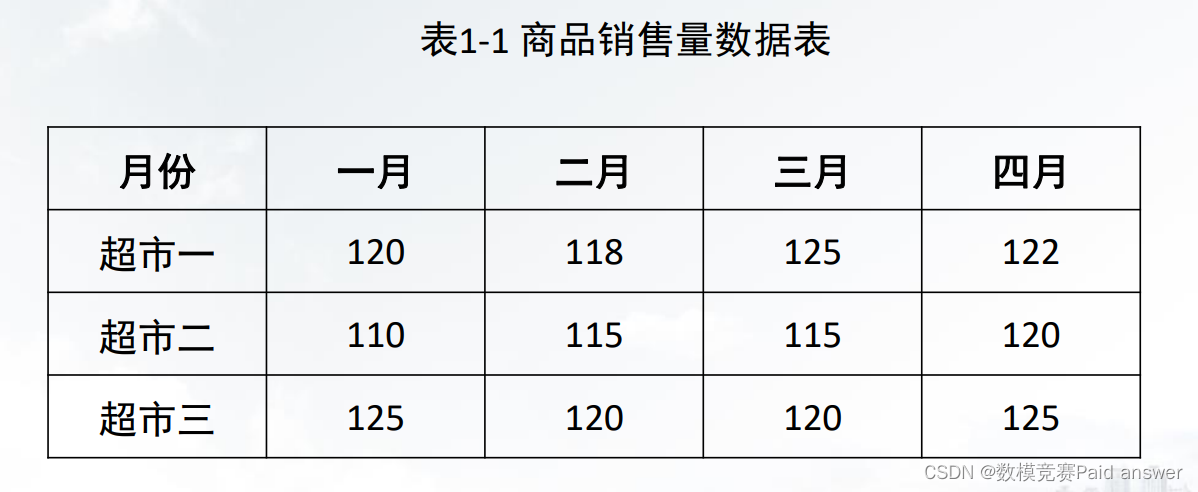
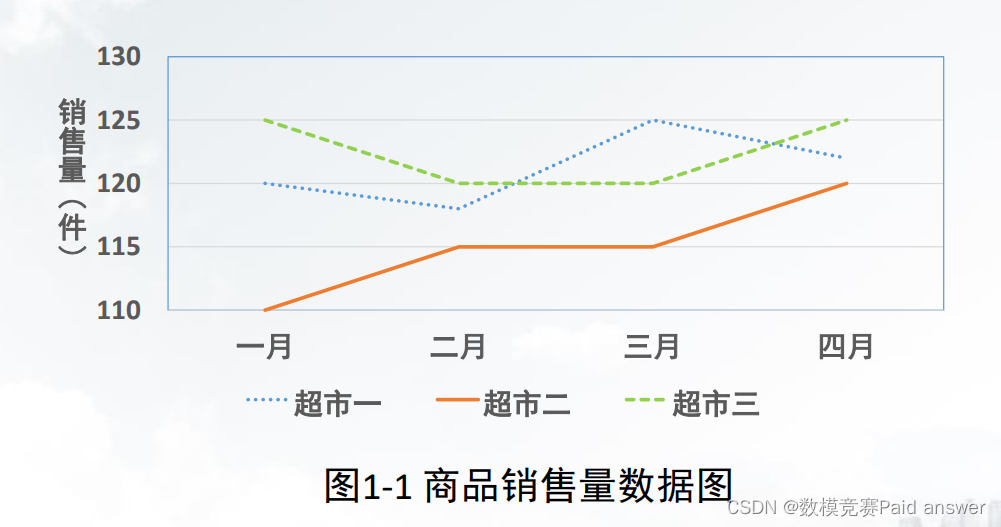
数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当地描述,提取出有用的信息的过程。
2. 数据挖掘
数据挖掘(Data Mining,DM)是指从海量的数据中通过相关的算法来发现隐藏在数据中的规律和知识的过程。
数据的爆炸式增长: 从TB到PB
– 丰富数据的主要来源
• 商业: Web, 电子商务, 交易, 股票, …
• 科学: 遥感, 生物信息学, 科学仿真, …
• 社会与个人: 新闻, 数码相机, YouTube
– 数据采集与数据可用性
• 自动数据收集工具, 数据库系统, Web,
计算机化的社会
数据是丰富的,急需发现知识!
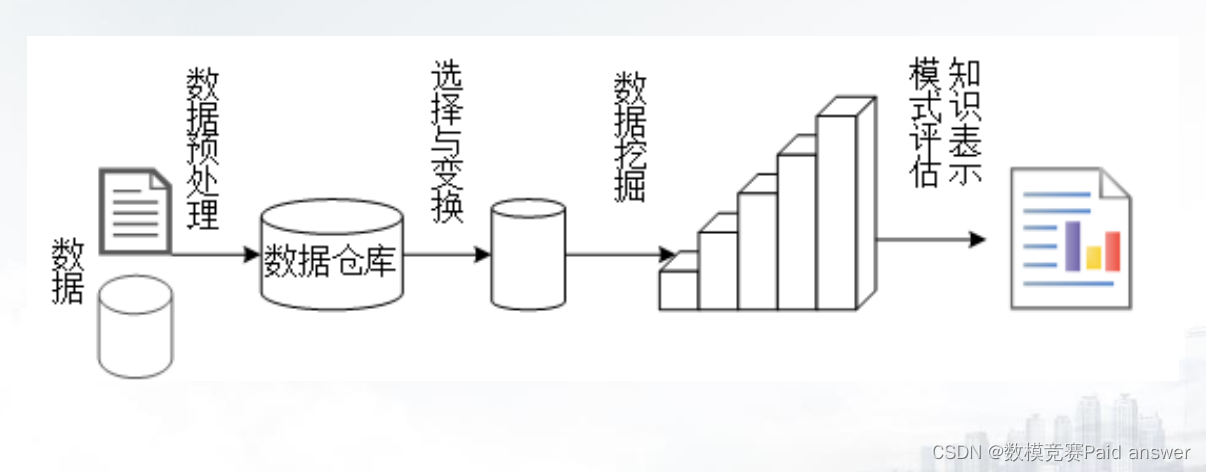
通常将数据挖掘视为数据中“知识发现”的同义词,也可以认为数据挖掘是知识发现中的一个步骤。
3. 知识发现(KDD)的过程
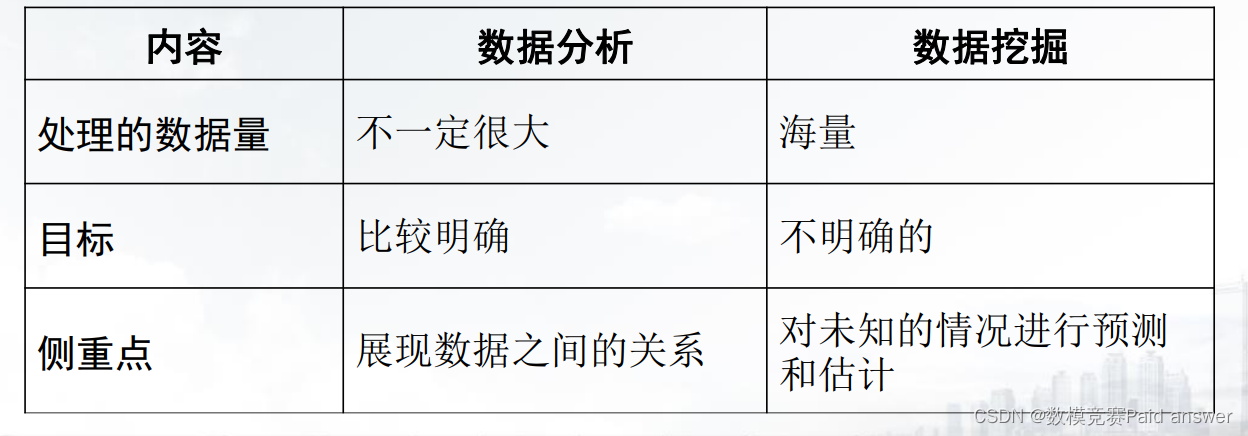
4. 数据分析与数据挖掘的区别
5. 数据分析与数据挖掘的联系
➢ 数据分析的结果往往需要进一步的挖掘才能得到更加清晰的结果,而数据挖掘发现知识的过程也需要对先验约束进行一定的调整而再次进行数据分析。
➢ 数据分析可以将数据变成信息,而数据挖掘将信息变成知识,如果需要从数据中发现知识,往往需要数据分析和数据挖掘相互配合,共同完成任务。
分析与挖掘的数据类型
➢ 数据库数据
➢ 数据仓库数据
➢ 事务数据
➢ 数据矩阵
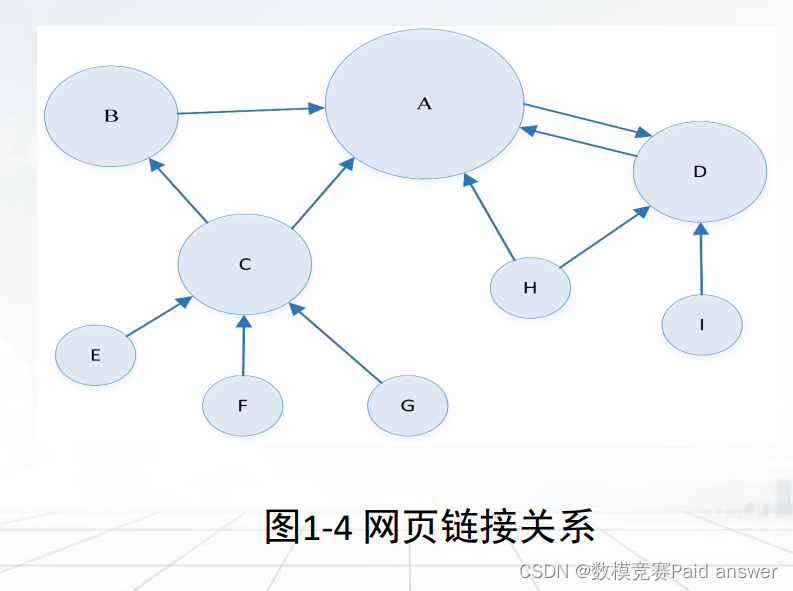
➢ 图和网状数据
➢ 其他类型的数据
➢ 数据库系统(DataBase System,DBS)由一组内部相关的数据(称作数据库)和用于管理这些数据的程序组成,通过软件程序对数据进行高效的存储和管理。
数据库数据
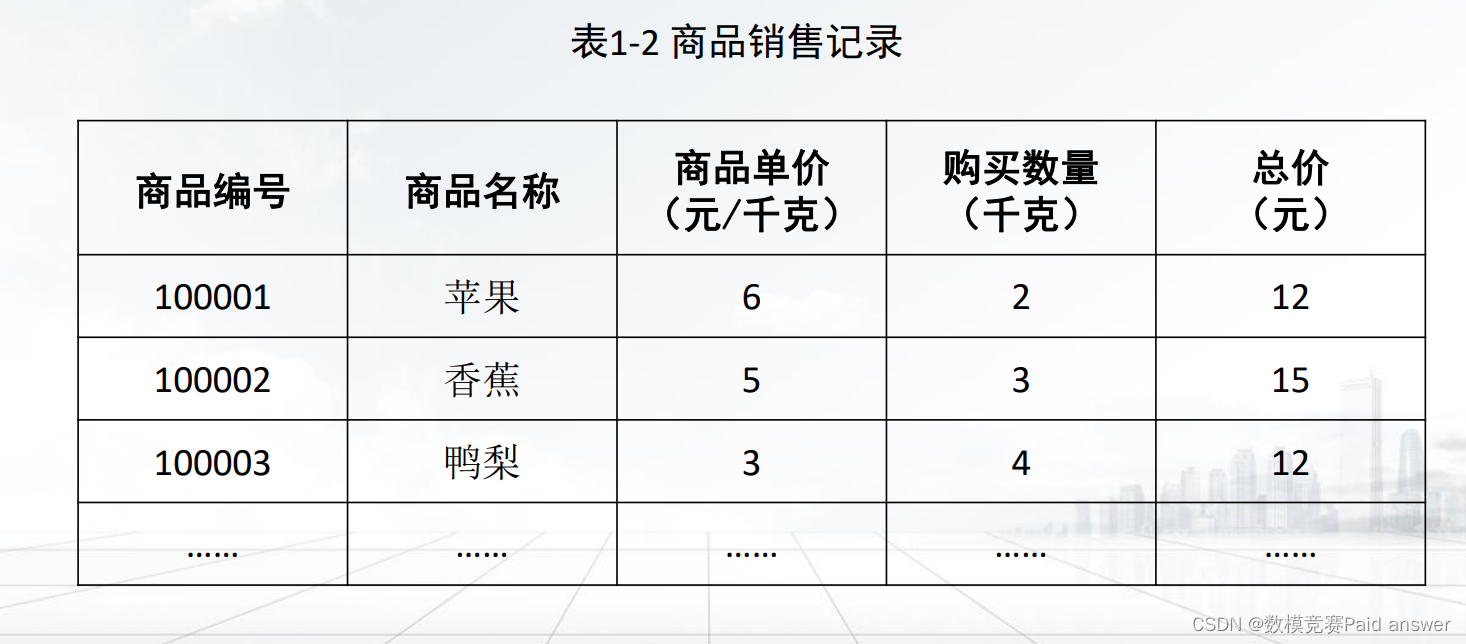
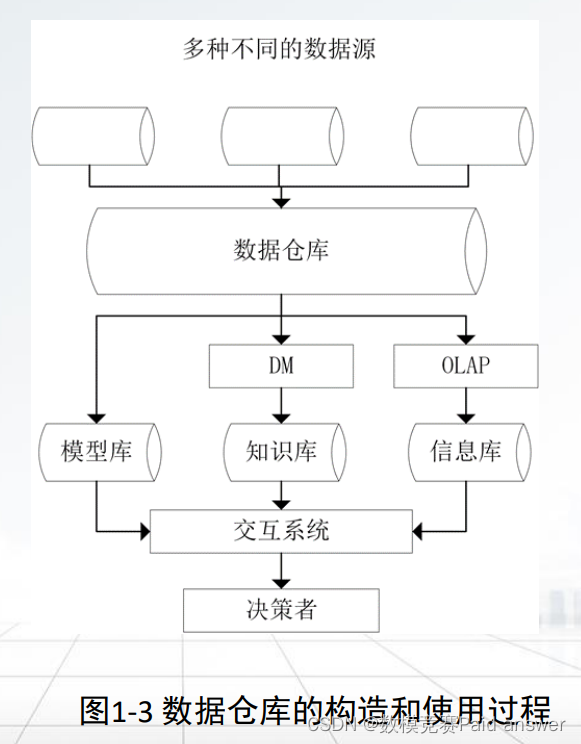
➢ 数据仓库(Data Warehouse,DW)是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者决策过程。
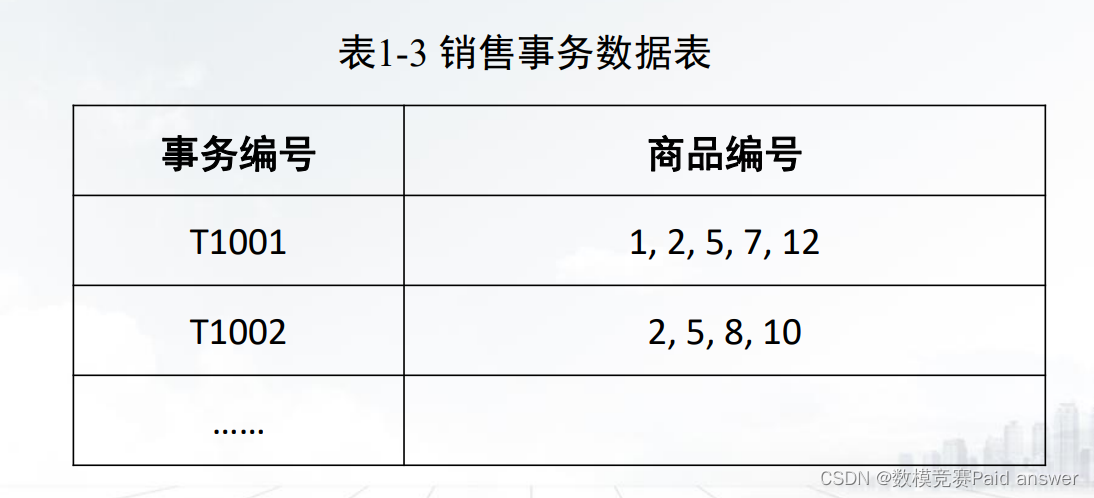
➢ 事务数据库的每个记录代表一个事务,比如一个车次的订票、顾客的一个订单等等。
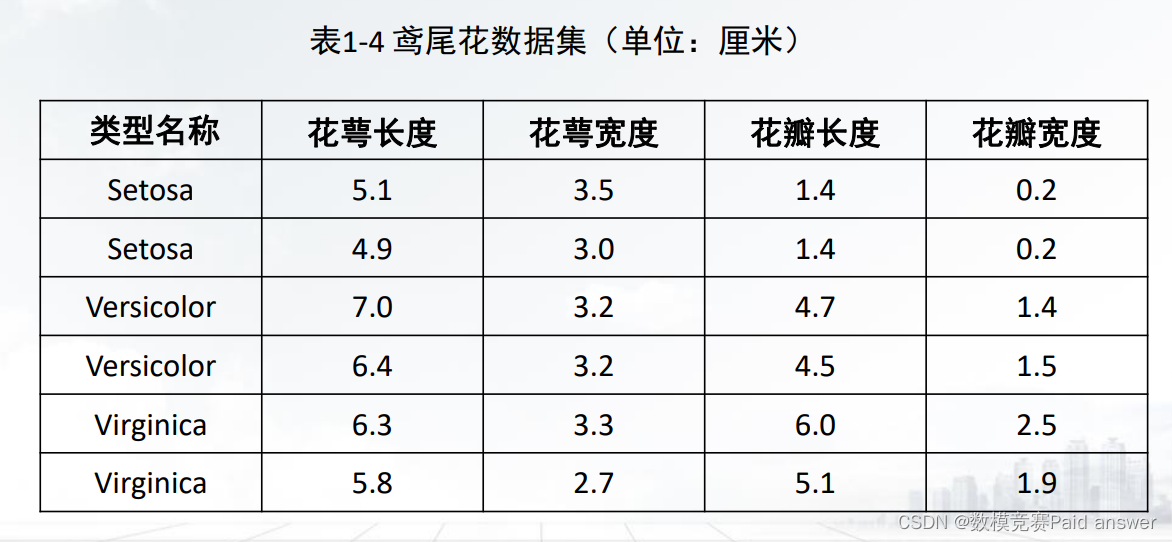
➢ 数据矩阵中的数据对象的所有属性都是具有相同性质的数值型数据。
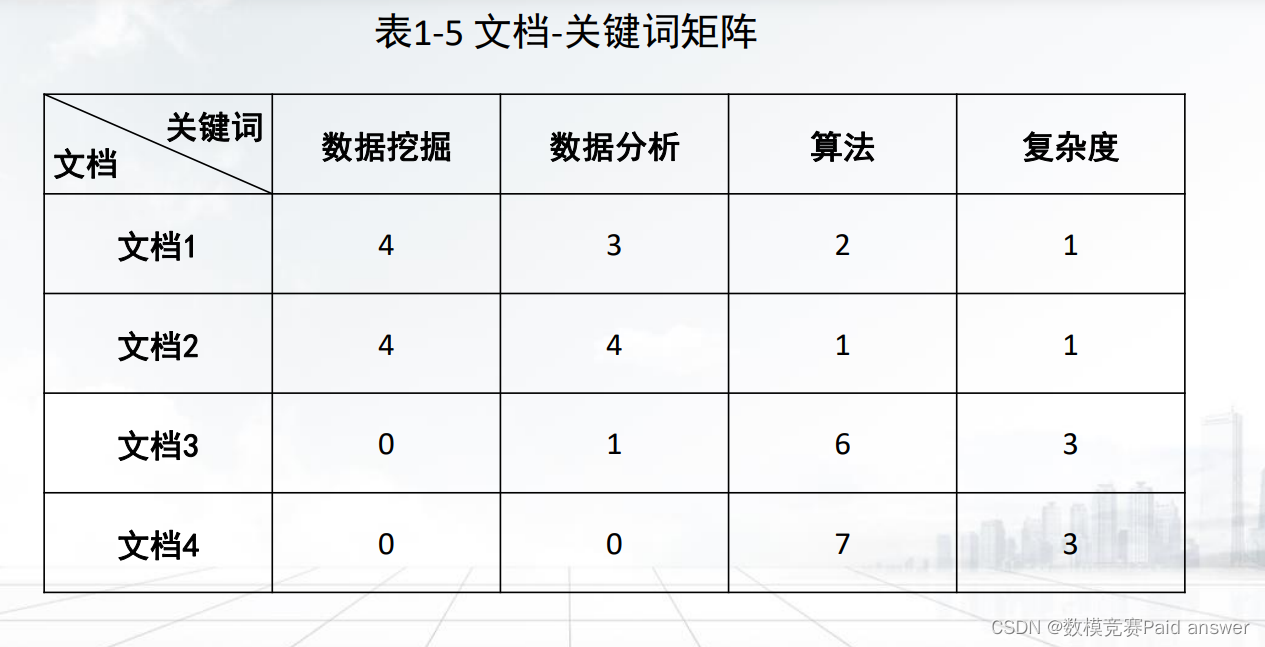
➢ 图和网状结构通常用来表达不同结点之间的联系,比如人际关系网、网站之间的相互链接关系等。
其他类型的数据
➢ 与时间相关的序列数据:不同时刻的气温、股票市场的历史交易数据
➢ 数据流数据:监控中的视频数据
➢ 多媒体数据:视频、音频、文本和图像数据
6.数据分析与数据挖掘的方法
(1)频繁模式
➢ 频繁模式:数据中频繁出现的模式
➢ 频繁项集:频繁在事务数据集中一起出现的商品集合
例如:在超市的销售中哪些商品会频繁地一起被购买?
➢ 关联与相关性
例如:典型的关联规则
尿不湿 → 啤酒
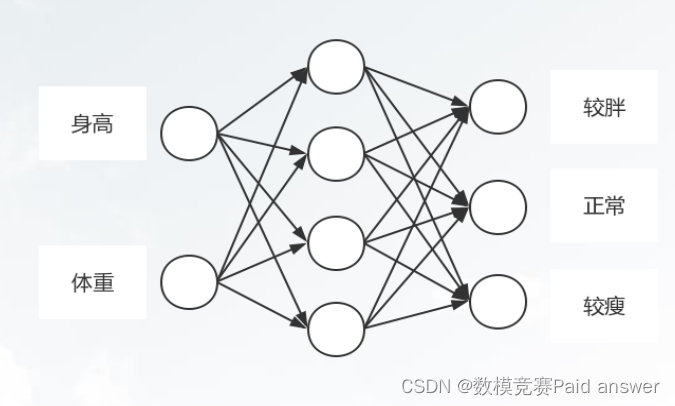
(2)分类与回归
➢ 分类与标签预测是找出描述和区分数据类或概念的模型或函数,以便能够使用模型预测类标号未知的对象的类标号
➢ 分类预测类别(离散的、无序的)标号,回归建立连续值函数模型,也就是用来预测缺失的或难以获得的数值数据值。
➢ 典型方法:决策树, 朴素贝叶斯分类,支持向量机,神经网络, 规则分类器, 基于模式的分类,逻辑回归 …
(3)聚类分析
➢ 聚类就是把一些对象划分为多个组或者“聚簇”,从而使得同组内对象间比较相似而不同组对象间差异较大。例如:通信公司根据“工作时间通话时长”、“其他时间通话时长”、“本地通话时长”等属性对用户进行聚类分析,可以将用户划分为“商务用户”、“普通用户”以及“较少使用用户”。
(4)离群点分析
➢ 离群点是指全局或局部范围内偏离一般水平的观测对象。例如:当发现某个人的信用卡在不经常消费的地区短时间内消费了大量的金额,则可以认定这张卡的使用情况异常,可以作为离群点数据。
7.数据分析与数据挖掘使用的技术
(1)统计学方法
➢ 统计学是通过对数据进行收集、整理、分析和描述,来达到对研究对象本质的理解和表示。
➢ 在实际生活中,通常有一些过程无法通过理论分析直接获得模型,但可以通过直接或间接测量的方法获得描述目标对象的相关变量的具体数据,用来刻画这些变量之间关系的数学函数称为统计模型。
(2)机器学习
➢ 机器学习主要研究计算机如何像人类学习知识那样自主地分析和处理数据,并作出智能的判断,并通过获得的新的知识对自身进行发展和完善。

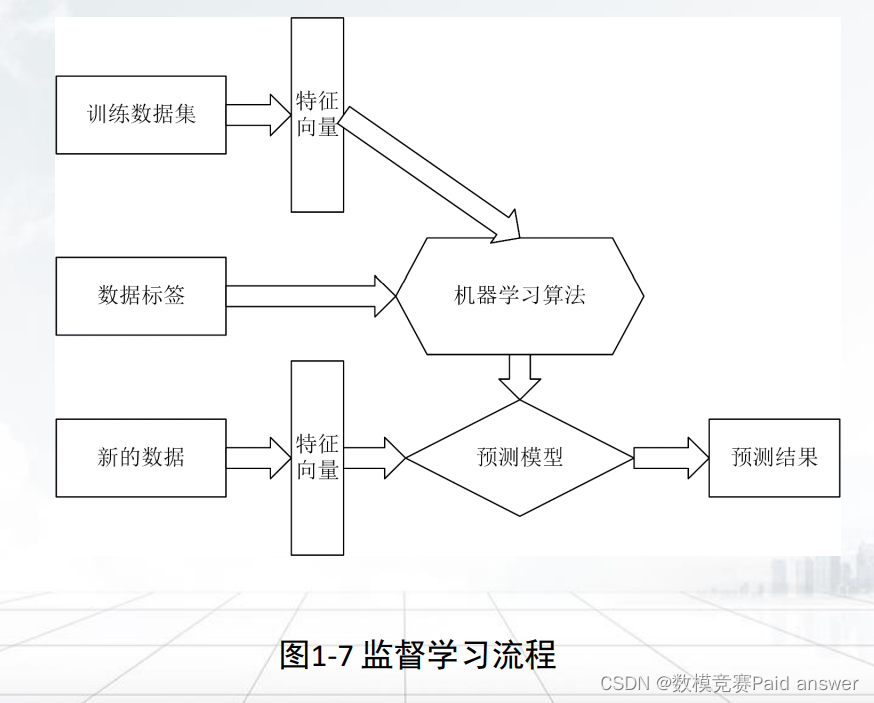
➢ 机器学习方法:包括监督学习、无监督学习、半监督学习等。
➢ 监督学习需要在有标记的数据集上进行。
➢ 无监督学习:可以在没有标记的数据集上进行学习,实质上无监督学习是一个聚类的过程。
➢ 半监督学习:半监督学习主要考虑如何利用少量有标记的数据和大量未标记的数据来进行学习,其中标记的数据用来学习模型,而未标记的数据用来进一步改进类的边界。

(3)数据库与数据仓库
➢ 数据库系统是为了解决数据处理方面的问题而建立起来的数据处理系统,注重于为用户创建、维护和使用数据库。
➢ 数据仓库汇集了来自多个不同数据源的数据,通过数据仓库,可以在不同的维度合并数据,形成数据立方体,便于从不同的角度对数据进行分析和挖掘。
(4)模式识别
➢ 模式识别的本质就是抽象出不同事物中的模式,并根据这些模式对事物进行分类或聚类的过程。
➢ 研究内容:文字识别、语音识别、图像识别、医学诊断以及指纹识别等。
(5)高性能计算
➢ 高性能计算是指突破单个计算机资源不足的限制,使用多个处理器或多台计算机共同完成同一项任务的计算环境。
8.应用场景及存在的问题
应用场景
➢ 商务智能:通过数据挖掘等技术可以获得隐藏在各种数据中的有利信息,从而帮助商家进一步调整营销策略。
➢ 信息识别:信息识别是指信息接受者从一定的目的出发,运用已有的知识和经验,对信息的真伪性、有用性进行辨识和甄别。
➢ 搜索引擎:根据用户提供的关键词,在互联网上搜索用户最需要的内容。
➢ 辅助医疗:对大量历史诊断数据进行分析和挖掘,有助于医生对病人的病情进行有效的判断。
存在的问题
➢ 数据类型的多样性
➢ 高维度数据
➢ 噪声数据
➢ 分析与挖掘结果的可视化
➢ 隐私数据的保护














 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









