









2021年华中杯数学建模
B题 技术问答社区重复问题识别
原题再现:
技术社区问答平台作为用户互相分享交流的社区平台,近年来逐步成为用户寻找技术类疑难解答的首要渠道。 各分类技术性问题的文本数据量不断攀升,给问答平台的日常运营维护带来了挑战。随着新用户的不断加入以及用户数量的增加,新用户提出的疑问可能已经在平台上被其他用户提出并解答过,但由于技术性问题的复杂性,各个用户提问的切入角度不同,用问题标题关键词匹配的搜索系统无法指引新用户至现有的问题。于是,新用户会提出重复的问题,而这些问题会进一步增加平台上的文本量,导致用户重复响应相同的问题。对于这种现象,通常的做法是及时找到新增的重复问题并打上标签,然后在搜索结果中隐藏该类重复问题,保证对应已解决问题出现的优先度。所以,建立一个基于自然语言处理技术的自动标重系统会对问答平台的日常维护起到极大帮助。
目前,问答平台上的问题标重主要依靠用户人工辨别。平台用户会对疑似重复的问题进行投票标记,然后平台内的管理员和资深用户(平台等级高的用户)对该问题是否被重复提问进行核实,若确认重复则打上重复标签。该过程较为繁琐,依赖用户主观判断,存在时间跨度大、工作量大、效率低等问题,增加了用户的工作量且延长了新用户寻求答案所需的时间。因而,如能建立一个检测问题重复度的模型,通过配对新提出问题与文本库中现存问题,找出重复的问题组合,就能提高重复问题标记效率,提高平台问题的文本质量,减少问题冗余。同时,平台用户也能及时地根据重复标签提示找到相关问题并查看已有的回复。
附件给出了问答平台上问题的文本内容记录,以及比较两个问题之间是否重复的数据集。请根据附件给出的问题文本数据及问题配对信息,建立一个能判断问题是否重复的分类模型,并解决:
1)输出样本问题组为重复问题的概率;


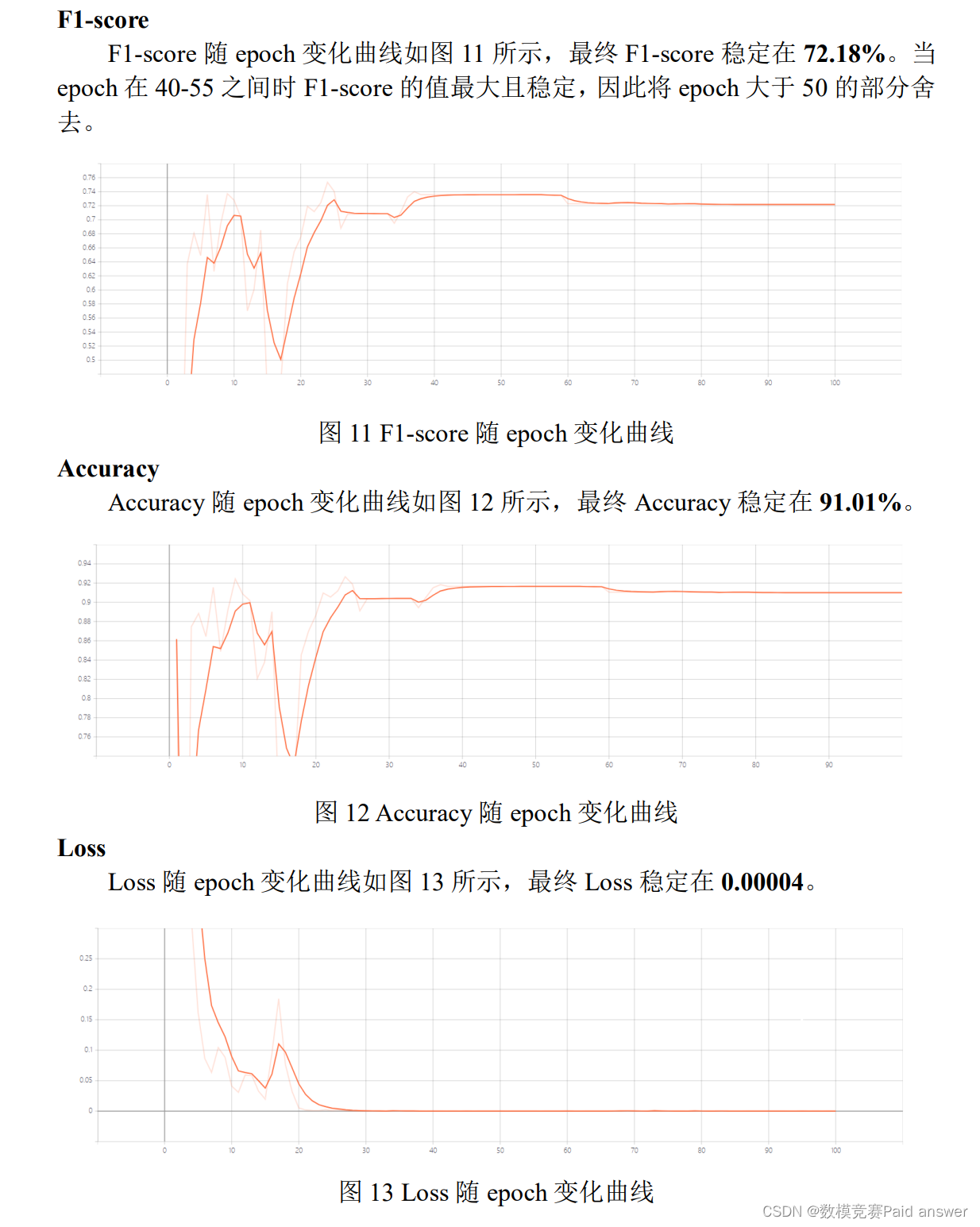
整体求解过程概述(摘要)
建立一个基于自然语言处理技术的自动标重系统会对技术问答平台的日常维护起到极大作用。本文探究的是如何使用 NLP 技术建立一个判断问题是否重复的分类模型。数据处理和模型构建使用 Python3.8,MacBERT 模型构建使用PyTorch 深度学习框架,并使用 GPU 进行训练加速。
针对问题一(中文文本分类问题),本文采用基于 MacBERT 的文本相似度预测模型,将问题一的文本相似度概率预测问题抽象为是否为重复问题的二分类问题,并在实际数据进行预测。首先使用 CPM 中文分词模型(CPM-tokenizer)对问题文本进行分词处理并嵌入向量化,然后将需要预测的两个问题的嵌入向量输入到 MacBERT 中,得到了相似性特征向量,然后将特征向量输入到全连接层中,得到最后的分类结果。由于原始数据存在正负样本数量极不平衡问题,我们将所有的正样本的 70%分为训练集,并将相同数量的负样本也分入训练集,将剩下的全部正样本和负样本都作为测试集。最终结果为 F1-score 为 72.18%,准确度为 91.01%,Loss 为 0.00004。
针对问题二(推荐问题),将问题一中的深度神经网络全连接层进行改进,使其输出为重复问题的概率,针对每一个问题在所有的问题数据中随机采样 100个问题作为候选对象,并依据概率的大小进行排序,得到推荐列表,以完成问题二的相似问题推荐任务。最终结果为 R 值为 0.2460。
关键词:重复问题识别;MacBERT 模型;文本相似性;self-attention;Transformer
问题分析:
对于问题一,属于文本分类问题。传统的机器学习分类方法将整个文本分类问题就拆分成了特征工程和分类器两部分。特征工程分为文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力。传统做法主要问题的文本表示是高纬度高稀疏的,特征表达能力很弱,而且神经网络很不擅长对此类数据的处理;此外需要人工进行特征工程,成本很高。应用深度学习解决大规模文本分类问题最重要的是解决文本表示,再利用CNN/RNN/BERT 等网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端的解决问题。本文首先采用 CPM 中文分词模型(CPM-tokenizer)对问题文本进行分词处理并嵌入向量化,然后将需要预测的两个问题的嵌入向量输入到MacBERT 中,得到了相似性特征向量,然后将特征向量输入到全连接层中,得到最后的分类结果。
对于问题二,属于推荐问题。推荐系统是根据用户需求、兴趣等,通过推荐算法从海量数据中挖掘出用户感兴趣的项目(如信息、服务、物品等),并将结果以个性化列表的形式推荐给用户。推荐系统的核心是推荐算法,它利用用户与项目之间的二元关系,基于用户历史行为记录或相似性关系帮助发现用户可能感兴趣的项目。传统的推荐算法主要分为以下四种方式:关联规则推荐、协同过滤推荐( collaborative filtering recommendation )、 基 于 内 容 的 推 荐 ( content-based recommendation)、混合推荐(hybrid recommendation)。经典的协同过滤方法采用浅层模型无法学习到用户和项目的深层次特征;基于内容的推荐方法利用用户已选择的项目来寻找其它类似属性的项目进行推荐,但是这种方法需要有效的特征提取,传统的浅层模型依赖于人工设计特征(先验知识),其有效性及可扩展性非常有限,制约了基于内容的推荐方法的性能。因此本文采用的是基于深度学习的推荐系统。基于深度学习的推荐系统通常将各类用户和项目相关的数据作为输入,利用深度学习模型学习到用户和项目的隐表示,并基于这种隐表示为用户产生项目推荐。一个基本的架构如图 1 所示,包含输入层、模型层和输出层.输入层的数据主要包括:根据 CPM 生成的嵌入向量。在模型层,使用的深度学习模型比较广泛,包括自编码器、受限玻尔兹曼机、卷积神经网络、循环神经网络等,本文才好用的是 BERT 模型。在输出层,通过利用学习到的句式隐表示,通过内积、Softmax、相似度计算等方法产生项目的推荐列表。
模型的建立与求解:
Chinese Pre-trained Language Model(CPM)是最大的中文预训练语言模型,它可以促进后续的中文自然语言处理任务,如会话、文章生成、完形填空和语言理解。通过对各种中文自然语言处理任务的实验表明,CPM 算法在少数镜头(甚至是零镜头)的情况下对许多自然语言处理任务都有很好的处理效果。随着参数的增加,CPM 在大多数数据集上表现得更好,这表明较大的模型在语言生成和语言理解方面更为熟练。CPM 是一个从左到右的转换器解码器,类似于 GPT 的模型架构(Radford等人,2019)。我们预先训练了三个不同尺寸的模型。为了使 CPM 适应汉语语料库,我们建立了一个新的子词表,并调整了训练批量。表 1 是模型尺寸。

表 1:模型尺寸。nparam 是参数的数量。nlayers 增加层数。dmodels 是隐藏状态的维度,在每一层中都是一致的。nheads 是每层中的关注头数量。dhead 是每个注意头的尺寸。
词汇构建:以往关于汉语预训练模型的研究通常采用 BERT-Chinese 的子词词汇(Devlin et al.,2019),将输入文本分割成一个新的文本字符级序列。然而,汉语词汇通常包含多个字符,在字符级序列中会丢失一些重要的语义。为了解决这个问题,我们构造了一个新的子词词汇,包含单词和字符。例如,一些常用词会被添加到词汇表中。
训练策略:由于中文词分布的稀疏性比英文词分布的稀疏性更严重,我们采用了大批量的方法使模型训练更加稳定。与 GPT-3 2.7B(Brown 等人,2020)中使用的批量大小(100 万代币)相比,我们的批量大小(300 万代币)要大两倍。对于训练过程中不能存储在单个 GPU 中的最大模型,我们将模型沿宽度维度跨GPU 进行划分,以便于大规模训练,减少节点间的数据传输。
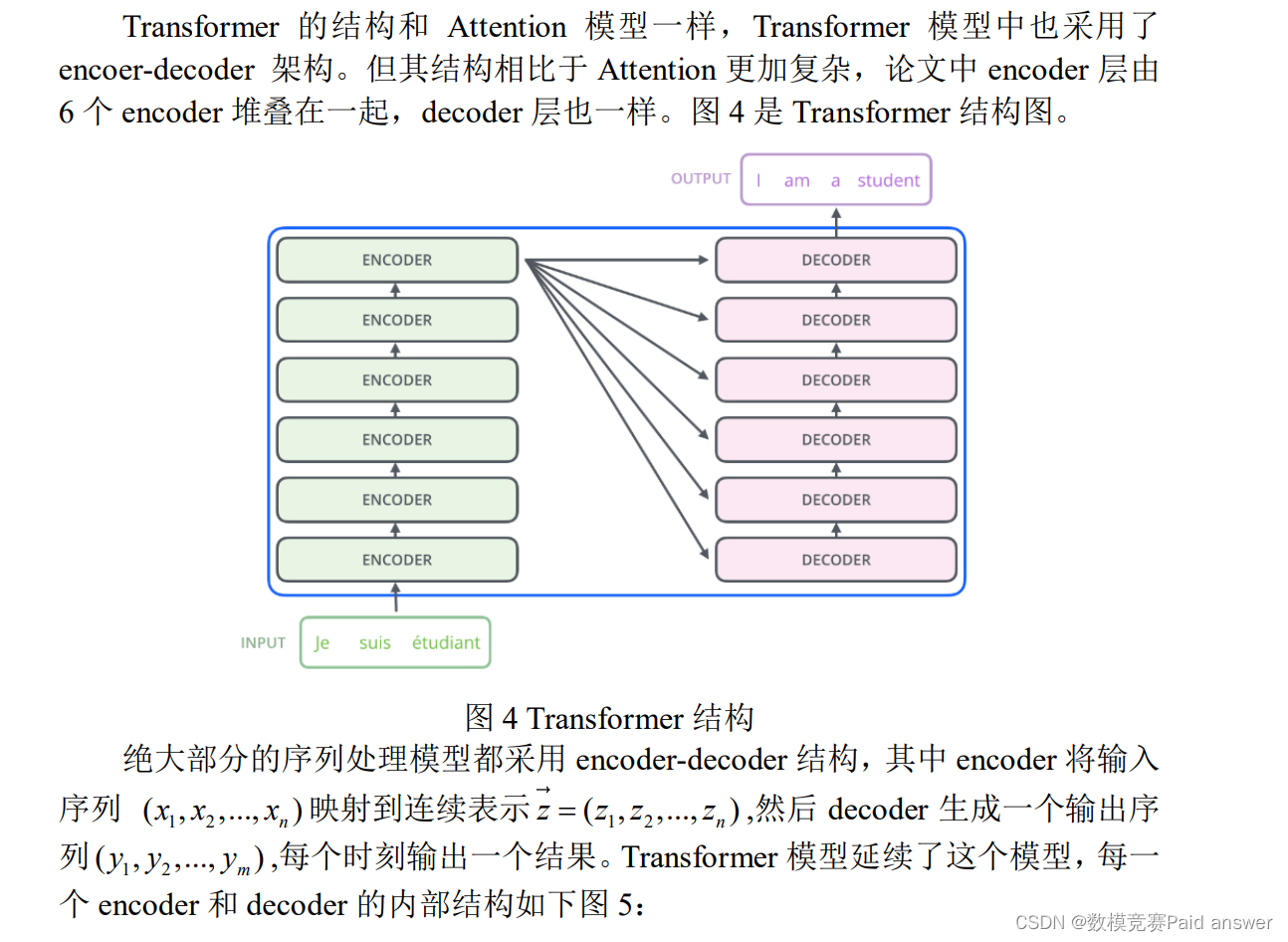
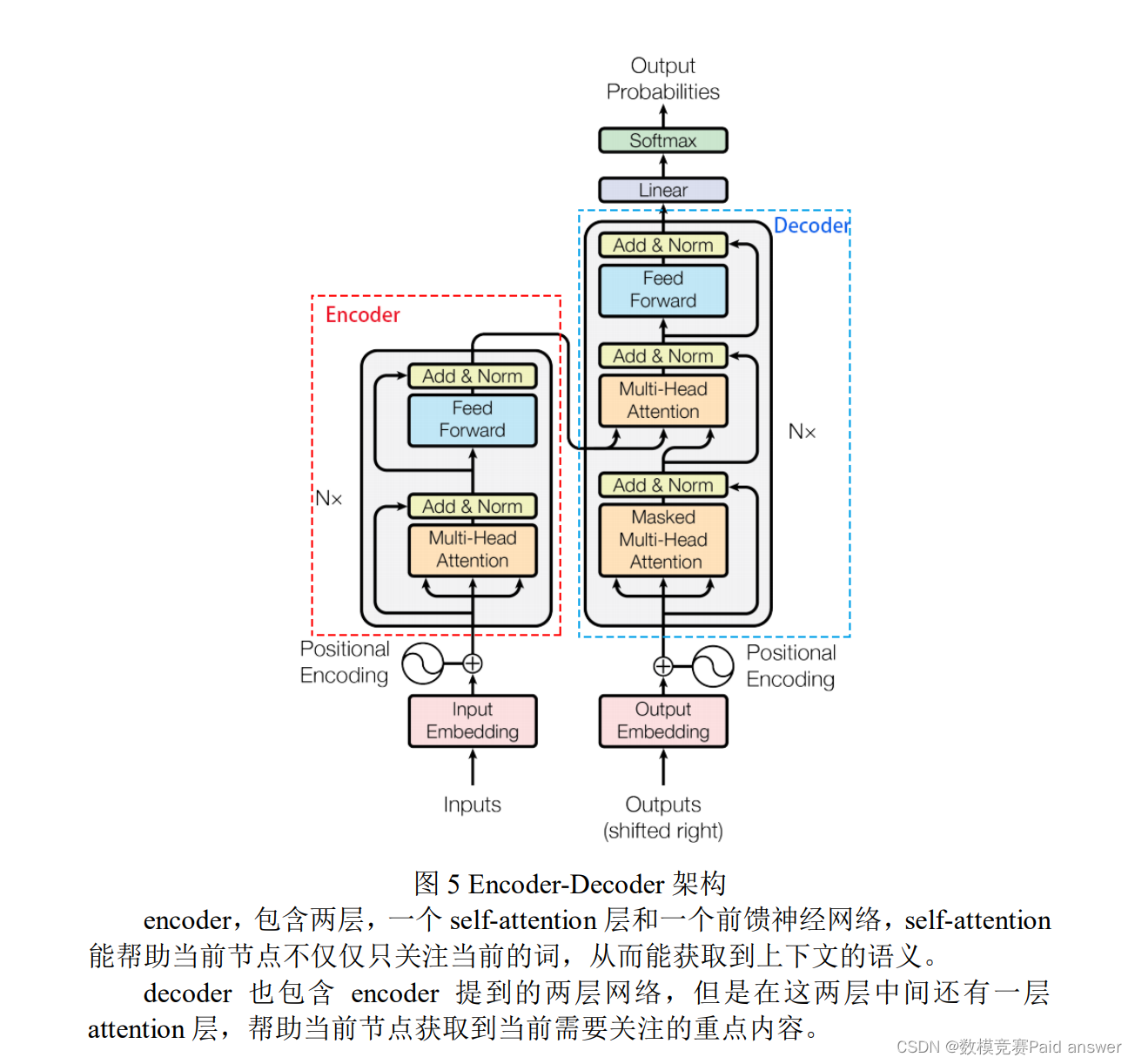
预训练
第一步预训练的目标就是做语言模型,从上文模型结构中看到了这个模型的不同,即 bidirectional。这里作者用了一个加 mask 的 trick。在训练过程中作者随机 mask 15%的 token,而不是把像 cbow 一样把每个词都预测一遍。最终的损失函数只计算被 mask 掉那个 token。Mask 如何做也是有技巧的,如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,所以随机 mask 的时候 10%的单词会被替代成其他单词,10%的单词不替换,剩下 80%才被替换为[MASK]。要注意的是 Masked LM 预训练阶段模型是不知道真正被 mask 的是哪个词,所以模型每个词都要关注。因为序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的 10%步数训练 512 长度的输入。第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子 A 和 B,B 有一半的几率是 A 的下一句,输入这两个句子,模型预测 B 是不是 A 的下一句。预训练的时候可以达到 97-98%的准确度。
在本文中,我们利用了以前的 BERT 模型,并提出了一个简单的修改,导致微调任务的显著改进,我们称这个模型为 MacBERT(MLM 为修正 BERT)。MacBERT 与 BERT 共享相同的预训练任务,但有一些修改。对于 MLM 任务,我们执行以下修改。
1) 我们使用全词掩蔽和 Ngram 掩蔽策略来选择候选标记进行掩蔽,单词级单图到 4-gram 的百分比分别为 40%、30%、20%、10%。
2) 我们建议使用类似的词语进行掩蔽,而不是使用[MASK]标记进行掩蔽,该标记从未出现在微调阶段。使用同义词工具箱(Wang 和 Hu,2017)获得相似的单词,该工具箱基于 word2vec(Mikolov et al.,2013)相似性计算。如果选择一个 N-gram 来屏蔽,我们将分别找到相似的单词。在极少数情况下,当没有相似词时,我们会降级使用随机词替换。
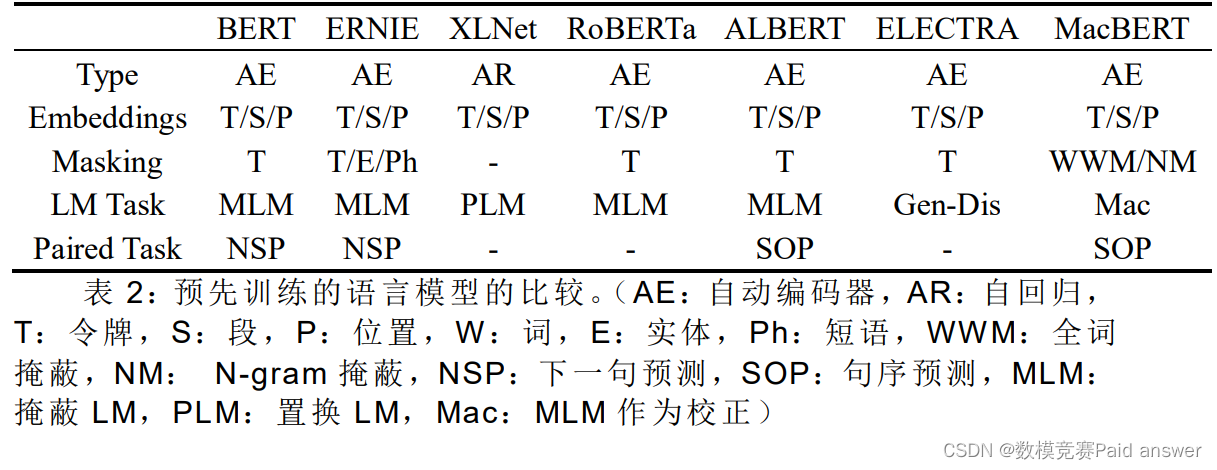
3) 我们使用 15%的输入词进行掩蔽,其中 80%将替换为相似词,10%替换为随机词,其余 10%保留为原始词。对于类似 NSP 的任务,我们执行句子顺序 ALBERT(Lan 等人,2019)提出的预测(SOP)任务,通过切换两个连续句子的原始顺序来创建负样本。我们调查了 最近自然语言处理领域中有代表性的预训练语言模型的技术。表 2 描述了这些模型以及所提出的 MacBERT 模型的总体比较。
求解结果:
问题二采用的是问题一训练出的模型,其 R 值为 0.2460。
论文缩略图:

程序代码:
#该段代码功能:数据预处理
from numpy.core.defchararray import replace
# import pkuseg
from transformers import BertTokenizer, BertModel
import torch
from torch.utils.data import Dataset
import pandas as pd
import numpy as np
# 超参数
TEST_RATIO = 0.7
num_random = 10
# tokenizer = BertTokenizer.from_pretrained("weight")
# model =
BertModel.from_pretrained("weight/chinese_macbert_base.zip")
# 读生数据
# 将句子存入内存:所有句子有id且不连续,所以维持dataframe的存在
rawCsv = pd.read_csv('src/data/attachment1.csv')
# print(rawCsv.head())
# 建立text id和dataFrame id的索引,HashMap
idIndex = {}
for i in range(rawCsv.shape[0]):
index = rawCsv.iloc[i, 0]
idIndex[index] = i
# 读取标记数据
# 先验知识:
# 句子tokenize后词向量数量最大2038,最小11,直接设定max length = 2048, 即
词向量个数
# 有些行dpulicate中存在多个句子id,通过循环处理
# 三列的数据类型:np.int64, str, np.int64
# 第二列在eval后变成列表
rawPairDataCsv = pd.read_csv('src/data/attachment2.csv')
processedData = []
# print(rawPairDataCsv.head())
# print(type(rawPairDataCsv.iloc[0, 0]))
# print(type(eval(rawPairDataCsv.iloc[0, 1])))
# print(type(rawPairDataCsv.iloc[0, 2]))
for i in range(rawPairDataCsv.shape[0]):
label = rawPairDataCsv.iloc[i, 2]
if int(label) == 0:
pairQuestionId = np.random.choice(list(idIndex.keys()),
size=1)
processedData.append({'id1': rawPairDataCsv.iloc[i, 0],
'id2': pairQuestionId[0], 'label': label})
continue
questionId = rawPairDataCsv.iloc[i, 0]
pairQuestionIdList = eval(rawPairDataCsv.iloc[i, 1])
if not len(pairQuestionIdList) == 1:
for pairID in pairQuestionIdList:
pairID = int(pairID)
processedData.append({'id1': questionId, 'id2': pairID,
'label': label})
else:
processedData.append({'id1': questionId, 'id2':
int(pairQuestionIdList[0]), 'label': label})
dataIndex = list(range(len(processedData)))
trainIndex = np.random.choice(dataIndex,
size=int(len(processedData) * TEST_RATIO), replace=False)
testIndex = list(set(dataIndex) - set(trainIndex))
# idx1 = processedData[0]['id1']
# idx2 = processedData[0]['id2']
# text1 = rawCsv.iloc[idIndex[idx1], 2]
# text2 = rawCsv.iloc[idIndex[idx2], 2]
# tensor_dict = tokenizer(text1, text2, padding=True,
max_length=2048, return_tensors='pt')
# 构建数据集
class TrainSet(Dataset):
def __init__(self, trainIndex) -> None:
super().__init__()
self.textIndex = [processedData[i] for i in trainIndex]
self.length = len(trainIndex)
def __getitem__(self, ids):
id1 = self.textIndex[ids]['id1']
id2 = self.textIndex[ids]['id2']
label = self.textIndex[ids]['label']
text1 = rawCsv.iloc[idIndex[id1], 2]
text2 = rawCsv.iloc[idIndex[id2], 2]
return text1, text2, label
def __len__(self):
return self.length
class TestSet(Dataset):
def __init__(self, testIndex) -> None:
super().__init__()
self.textIndex = [processedData[i] for i in testIndex]
self.length = len(testIndex)
def __getitem__(self, ids):
id1 = self.textIndex[ids]['id1']
id2 = self.textIndex[ids]['id2']
label = self.textIndex[ids]['label']
text1 = rawCsv.iloc[idIndex[id1], 2]
text2 = rawCsv.iloc[idIndex[id2], 2]
return text1, text2, label
def __len__(self):
return self.length
groundtruth_raw = {}
for i in range(rawPairDataCsv.shape[0]):
id1 = int(rawPairDataCsv.iloc[i, 0])
label = rawPairDataCsv.iloc[i, 2]
if int(label) == 0:
continue
id2list = eval(rawPairDataCsv.iloc[i, 1])
if id1 not in groundtruth_raw.keys():
groundtruth_raw[id1] = []
for j in id2list:
groundtruth_raw[id1].append(int(j))
if int(j) not in groundtruth_raw.keys():
groundtruth_raw[int(j)] = []
groundtruth_raw[int(j)].append(id1)
# 根据attachment2.csv构建数据集
# for i in range(rawCsv.shape[0]):
# print('\r', "{}/{}".format(i, rawCsv.shape[0]), end='')
# index = rawCsv.iloc[i, 0]
# # englishText = rawCsv.iloc[i, 1]
# chineseText = rawCsv.iloc[i, 2]
# # chineseTextCutted = seg.cut(chineseText)
# # text2Tokenize = ['[CLS]'] + chineseTextCutted + ['[SEP]']
# tokenizedText = tokenizer(chineseText, padding=True,
truncation=True, max_length=2048)
# pass
# print('\n {} {}'.format(np.array(length).min(),
np.array(length).max()))
# print(type(rawCsv.iloc[0, 2])) 输出为str
# print(type(rawCsv.iloc[0, 0])) 输出为numpy.int64
# print(rawCsv.shape)
list(idIndex.keys())
select_dataset = []
for i in range(rawCsv.shape[0]):
id1 = rawCsv.iloc[i, 0]
random_select_id = np.random.choice(list(idIndex.keys()),
size=num_random, replace=False)
for id2 in random_select_id:
select_dataset.append({'id1': id1, 'id2':id2})
if id1 in groundtruth_raw.keys():
for id2 in groundtruth_raw[id1]:
select_dataset.append({'id1':id1, 'id2':id2})
class DatasetIndex:
def __init__(self) -> None:
self.trainIndex = trainIndex
self.testIndex = testIndex
self.select_dataset = select_dataset
self.groundtruth = groundtruth_raw
class Random_Select_Dataset(Dataset):
def __init__(self, select_dataset):
self.data = select_dataset
self.length = len(self.data)
def __len__(self):
return len(self.data)
def __getitem__(self, ids):
id1 = self.data[ids]['id1']
id2 = self.data[ids]['id2']
# label = self.data[ids]['label']
text1 = rawCsv.iloc[idIndex[id1], 2]
text2 = rawCsv.iloc[idIndex[id2], 2]
return text1, text2, id1, id2

















 6145
6145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









