






二维卷积层及其参数的视觉和数学解释
介绍
深度学习的库和平台(如Tensorflow,Keras,Pytorch,Caffe或Theano)在我们的日常生活中为我们提供了帮助,因此每天的新应用程序使我们感到"哇!"。 我们都有我们最喜欢的框架,但是它们的共同点是它们通过易于使用的功能(可以根据需要进行配置)使我们更轻松。 但是我们仍然需要了解可用的论据是什么,以便利用这些框架赋予我们的所有力量。
在这篇文章中,我将尝试列出所有这些参数。 如果您想了解它们对计算时间,可训练参数的数量以及卷积输出通道的大小的影响,则适合您。
> Input Shape : (3, 7, 7) — Output Shape : (2, 3, 3) — K : (3, 3) — P : (1, 1) — S : (2, 2) — D
所有GIF都是使用python制作的。 您将能够测试这些参数中的每一个,并通过在我的Github上推送的脚本(或制作您的GIF)亲自看到它们的影响。
这篇文章的各部分将根据以下参数进行划分。 这些参数可以在Conv2d模块的Pytorch文档中找到:
· in_channels(int)-输入图像中的通道数
· out_channels(int)-卷积产生的通道数
· kernel_size(整数或元组)—卷积内核的大小
· 跨度(int或tuple,可选)—卷积的跨度。 默认值:1
· padding(int或tuple,可选)—在输入的两侧都添加了零填充。 默认值:0
· dilation(整数或元组,可选)—内核元素之间的间距。 默认值:1
· 组(整数,可选)—从输入通道到输出通道的阻塞连接数。 默认值:1
最后,我们将拥有所有键,用于根据参数和输入通道的大小来计算输出通道的大小。
什么是内核?

> Convolution between an input image and a kernel
让我介绍一下什么是内核(或卷积矩阵)。 内核描述了将要传递给输入图像的过滤器。 为简单起见,内核将通过应用卷积积在整个图像上从左到右,从上到下移动。 该操作的输出称为过滤图像。

> Convolution product

> Input shape : (1, 9, 9) — Output Shape : (1, 7, 7) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D
举一个非常基本的例子,让我们想象一个3 x 3卷积核过滤9 x 9图像。 然后,该内核会在整个图像上移动,以在图像中捕获相同大小(3 x 3)的所有正方形。 卷积是元素级(或点级)乘法。 此结果的总和是输出(或滤波后的)图像上的结果像素。
如果您还不熟悉过滤器和卷积矩阵,那么我强烈建议您花一些时间来了解卷积内核。 它们是2D卷积层的核心。
可训练的参数和偏差
可训练参数(也简称为"参数")是在训练网络时将更新的所有参数。 在Conv2d中,可训练元素是组成内核的值。 因此,对于我们的3 x 3卷积内核,我们有3 * 3=9个可训练参数。

要更完整。 我们可以包括偏见与否。 偏差的作用将加到卷积积的总和上。 这个偏差也是一个可训练的参数,它使3 x 3内核的可训练参数数量增加到10。
输入输出通道数
> Input Shape: (1, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D
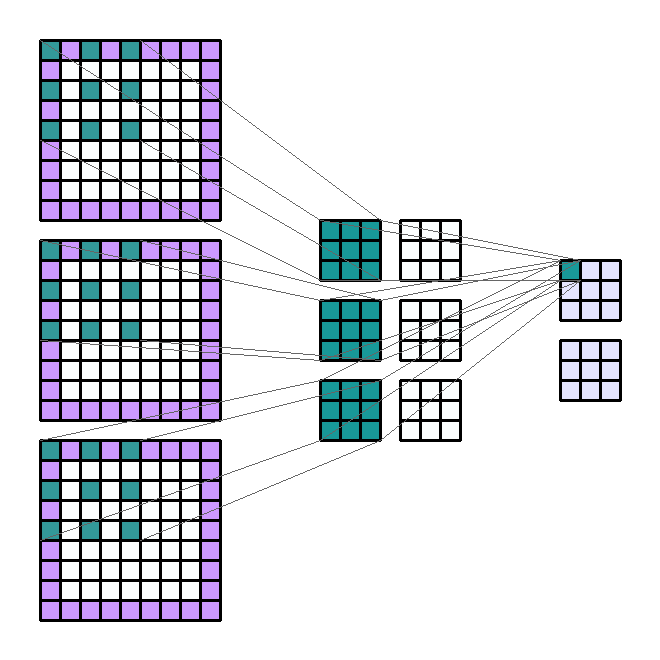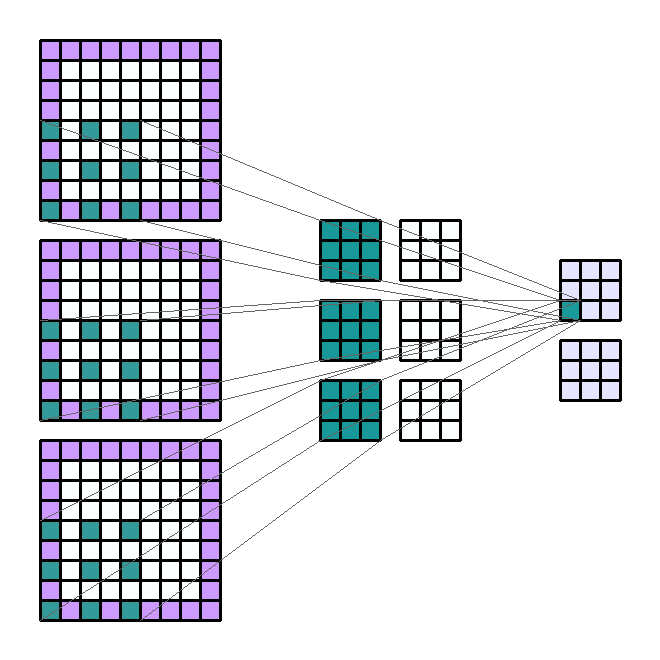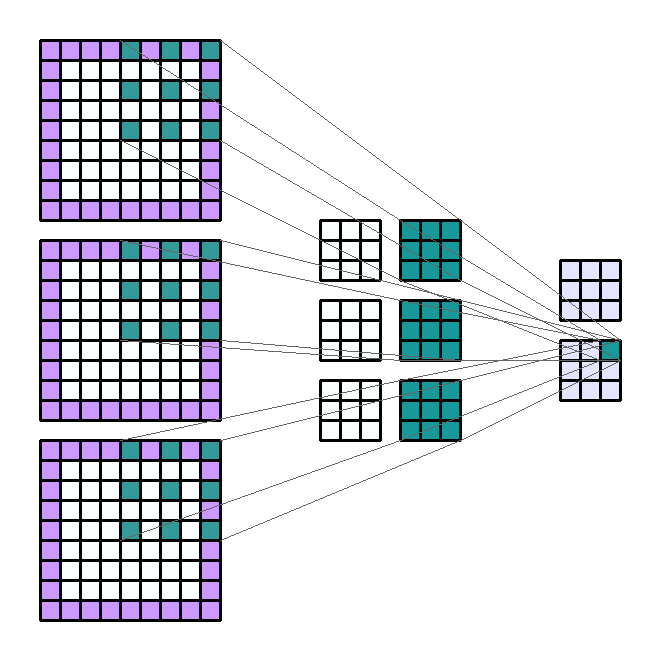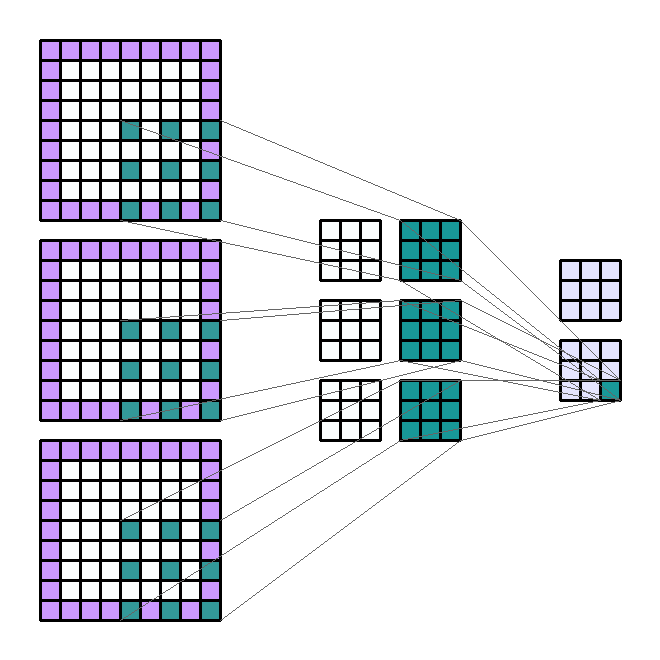
使用层的好处是能够同时执行类似的操作。 换句话说,如果我们要对一个输入通道应用4个大小相同的不同滤波器,那么我们将有4个输出通道。 这些通道是4个不同过滤器的结果。 因此来自4个不同的内核。

在上一节中,我们看到了可训练的参数是构成卷积核的要素。 因此参数的数量随卷积核的数量线性增加。 因此与所需输出通道的数量成线性关系。 还要注意,计算时间还与输入通道的大小成正比,并且与内核数成正比。

> Note that the curves in the Parameters graph are the same
相同的原理适用于输入通道的数量。 让我们考虑一下RGB编码图像的情况。 该图像具有3个通道:红色,蓝色和绿色。 我们可以决定在这三个通道的每个通道上使用大小相同的过滤器提取信息,以获得四个新通道。 因此,对于4个输出通道,该操作是相同的3倍。
> Input Shape: (3, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (0, 0) — S : (1, 1) — D
每个输出通道是过滤后的输入通道的总和。 对于4个输出通道和3个输入通道,每个输出通道是3个滤波后的输入通道的总和。 换句话说,卷积层由4 * 3=12个卷积内核组成。

提醒一下,参数的数量和计算时间与输出通道的数量成比例地变化。 这是因为每个输出通道都链接到与其他通道不同的内核。 输入通道数也是如此。 计算时间和参数数量成比例增长。

内核大小
到目前为止,所有示例都给出了3 x 3大小的内核。 实际上,其大小的选择完全取决于您。 可以创建核心大小为1 * 1或19 * 19的卷积层。
> Input Shape: (3, 7, 9) — Output Shape : (2, 3, 9) — K : (5, 2) — P : (0, 0) — S : (1, 1) — D
但是,也绝对可能没有方形内核。 有可能决定使用不同高度和宽度的内核。 在信号图像分析中通常是这种情况。 如果知道要扫描信号的图像或声音的图像,那么我们可能希望使用5 * 1大小的内核。
最后,您会注意到所有大小均由奇数定义。 定义均匀的内核大小也是可以接受的。 实际上,很少这样做。 通常,选择奇数大小的内核是因为在中心像素周围存在对称性。

由于卷积层的所有(经典)可训练参数都在内核中,因此参数的数量随内核大小线性增长。 计算时间也成比例地变化。
大步前进
默认情况下,内核从一个像素到另一个像素从左到右移动,从下到上移动。 但是这个动作也可以改变。 通常用于下采样输出通道。 例如,跨度为(1,3)时,滤波器水平方向从3移到3,垂直方向从1移到1。 这将产生水平向下采样3的输出通道。
> Input Shape: (3, 9, 9) — Output Shape : (2, 7, 3) — K : (3, 3) — P : (0, 0) — S : (1, 3) — D
步幅对参数的数量没有影响,但是计算时间在逻辑上随步幅线性减少。

> Note that the curves in the Parameters graph are the same
填充
填充定义在卷积滤波之前添加到输入通道侧面的像素数量。 通常,填充像素设置为零。 输入通道已扩展。

> Input Shape : (2, 7, 7) — Output Shape : (1, 7, 7) — K : (3, 3) — P : (1, 1) — S : (1, 1) — D
当您希望输出通道的大小等于输入通道的大小时,这非常有用。 消费社区为简单起见,当内核为3 * 3时,输出通道大小在每一侧均减小1。 为了克服这个问题,我们可以使用填充1。
因此,填充对参数的数量没有影响,但是会产生与填充的大小成比例的额外计算时间。 但是通常来说,与输入通道的大小相比,填充通常足够小,可以认为对计算时间没有影响。

> Note that the curves in the Parameters graph are the same
扩张
在某种程度上,膨胀是芯的宽度。 默认情况下等于1,它对应于卷积期间输入通道上内核的每个像素之间的偏移。
> Input Shape: (2, 7, 7) — Output Shape : (1, 1, 5) — K : (3, 3) — P : (1, 1) — S : (1, 1) — D
我在GIF上夸大了一点,但是如果我们以(4,2)的扩张为例,则输入通道上内核的接受场在垂直方向上会扩大4 (3 -1)=8,而在2 水平(3-1)=4(对于3乘3的内核)。
就像填充一样,膨胀对参数的数量没有影响,对计算时间的影响非常有限。

> Note that the curves in the Parameters graph are the same
组
在特定情况下,组可能非常有用。 例如,如果我们有几个串联的数据源。 当没有必要将它们彼此依赖时。 输入通道可以独立分组和处理。 最后,输出通道在最后串联。
如果有2个输入通道和4个带有2组的输出通道。 然后,这就像将输入通道分为两组(每组中有1个输入通道),然后使其经过卷积层,而卷积层的输出通道数是原来的一半。 然后连接输出通道。
> Input Shape : (2, 7, 7) — Output Shape : (4, 5, 5) — K : (3, 3) — P : (2, 2) — S : (2, 2) — D
重要的是要注意两件事。 首先,组数必须完美地划分输入通道数和输出通道数(共除数)。 其次,内核与每个组共享。
因此,参数的数量除以组的数量。 关于使用Pytorch的计算时间,该算法针对组进行了优化,因此应减少计算时间。 但是,还应考虑到必须合计用于组形成和连接输出通道的计算时间。

输出通道尺寸
在了解所有参数的情况下,可以根据输入通道的大小来计算输出通道的大小。















 4903
4903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









