









#因为要抓取数据的原因。而PHP对这方面的效果并不是很好。所以我就学习一下python的爬虫。下面写一下我的辛酸历程。
注:有很多代码都是百度过来的,我只是说一下我在其中遇见的BUG
1.上官网下载好python3.6.5之后遇见的第一个问题就给我打脸了。
for i in range(1, 5):
for j in range(1, 5):
for k in range(1, 5):
if (i != k) and (i != j) and (j != k):
print i, j, k
报的还是语法错误。可是我是从菜鸟教程那里面学习过来的啊。不可能会出错啊0.0
经过漫长的百度。终于找到问题了。

对,没错。就是版本问题。所以新手老铁们开发的时候一定要注意。2.7的python和3.6的python中间会出现很多不知名的错误。如果你觉得自己的代码没有错误。那么就可以查一下版泵的问题了。大神请忽略
2.先把自己从网上的代码复制进来
##coding:utf-8
import requests
######
#爬虫v0.1 利用urlib 和 字符串内建函数
######
def getHtml(url):
# 获取网页内容
# page = urllib.urlopen(url)
# html = page.read()
# return html
data = requests.get(url)
return data.content.decode(‘utf-8’)
def content(html):
# 内容分割的标签
str = '<article class="article-content">'
content = html.partition(str)[2]
str1 = '<div class="article-social">'
content = content.partition(str1)[0]
return content # 得到网页的内容
def title(content, beg=0):
# 匹配title
# 思路是利用str.index()和序列的切片
try:
title_list = []
while True:
num1 = content.index('】', beg) + 3
num2 = content.index('</p>', num1)
title_list.append(content[num1:num2])
beg = num2
except ValueError:
return title_list
def get_img(content, beg=0):
# 匹配图片的url
# 思路是利用str.index()和序列的切片
try:
img_list = []
while True:
src1 = content.index('http', beg)
# src2 = content.index('/></p>', src1)
src2 = content.index('[/img]', src1)
img_list.append(content[src1:src2])
beg = src2
except ValueError:
return img_list
def many_img(data, beg=0):
# 用于匹配多图中的url
try:
many_img_str = ''
while True:
src1 = data.index('http', beg)
src2 = data.index(' /><br /> <img src=', src1)
many_img_str += data[src1:src2] + '|' # 多个图片的url用"|"隔开
beg = src2
except ValueError:
return many_img_str
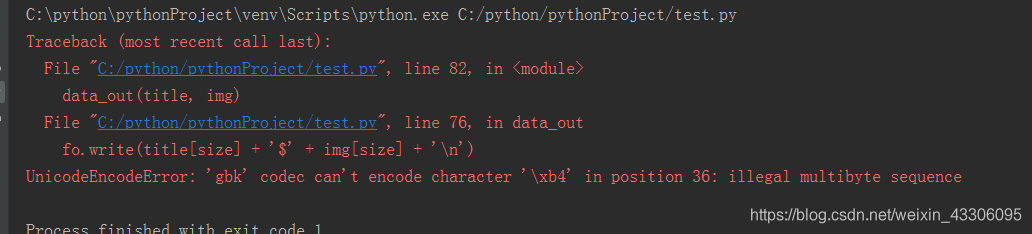
def data_out(title, img):
# 写入文本
with open("./data.txt", "a+", encoding='utf-8') as fo:
fo.write('\n')
for size in range(0, len(title)):
# 判断img[size]中存在的是不是一个url
if len(img[size]) > 70:
img[size] = many_img(img[size]) # 调用many_img()方法
fo.write(title[size] + '$' + img[size] + '\n')
content = content(getHtml("https://bh.sb/post/10475/"))
title = title(content)
img = get_img(content)
data_out(title, img)
实现了爬的单个页面的title和img的url并存入文本
##来源(回去找了一遍。并没有找到0.0)
其中有两个地方有过修改,
1.import requests 我引入的是这个方法
2.open函数后面追加了encoding=‘utf-8’,否则写入的时候会报错
好了,这也算是我开始写python爬虫的第一篇文章了。虽然代码大多数都是借鉴的。不过还是让我收获良多。暂时就写到这了。老大催着交其他项目了。














 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









