







复现别人的实验,往往死在第一步,数据处理。同样一个数据集,你用json文件做输出,我调csv文件。大家的分法还不一样,那我怎么比较实验性能。没有困难,创造困难也要上,不然觉得自己没有成就感。
以下代码解决了,如何将给定的csv文件(包含两列,第一列是图片名称,第二列是对应的标签,如下图所示。)
 将这样的csv文件,转化为,包含三列:第一列是所有的类名称,第二列是图片的绝对路径,第三列是图片对应的标签,如下图所示:
将这样的csv文件,转化为,包含三列:第一列是所有的类名称,第二列是图片的绝对路径,第三列是图片对应的标签,如下图所示:
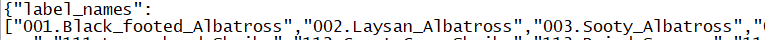

 这样的json文件。
这样的json文件。
主要完成的操作就是,csv文件的读取和json文件的写入,代码如下所示:
`# -*- coding:utf-8 -*-
import numpy as np
from os import listdir
from os.path import isfile, isdir, join
import os
import json
import random
import re
data_path = '/data2/quxue/cub/images/'
savedir = '/data2/quxue/cub/'
dataset_list = ['train','val','test']
label_names = [f for f in listdir(data_path) if isdir(join(data_path, f))]
label_names.sort()
for dataset in dataset_list:
image_names = []
image_labels = []
with open(savedir+dataset+'.csv','r',encoding='UTF-8') as f:
lines=f.readlines()
for i in range(len(lines)):
if i!=0:
l=lines[i].strip("\n").split(",")
image_names.append(data_path+l[1]+'/'+l[0])
image_labels.append(l[1][:3])
fo = open(savedir + dataset + '.json', 'w')
fo.write('{"label_names": [')
fo.writelines(['"%s",' % item for item in label_names])
fo.writelines(label_names)
fo.seek(0, os.SEEK_END)
fo.seek(fo.tell()-1, os.SEEK_SET)
fo.write('],')
fo.write('"image_names": [')
fo.writelines(['"%s",' % item for item in image_names])
fo.seek(0, os.SEEK_END)
fo.seek(fo.tell()-1, os.SEEK_SET)
fo.write('],')
fo.write('"image_labels": [')
fo.writelines(['%d,' % int(item) for item in image_labels])
fo.seek(0, os.SEEK_END)
fo.seek(fo.tell()-1, os.SEEK_SET)
fo.write(']}')
#print("%s -OK" %dataset)
如有错误,请指正。















 1540
1540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









