







pay more attention to attention:
improving the performance of convolutional neural networks via attention transfer
本论文由Sergey Zagoruyko, Nikos Komodakis等人2017年发表在ICLR上,作者提供了一部分代码,我做了注释,放在了github上。
作者代码
我的注释
本文借鉴于人类观看图像的第一感觉,会对图像的某个地方格外注意,即attenion,这种attention包含了该图片差别最大的地方,或者是最吸引人的地方。作者迁移的是这一部分的信息。
本文创新点总结:
- 提出了迁移attention机制,迁移的是attention information
- 提出了两种attention迁移方式:基于激活函数和基于梯度
- 实验表明,transfer attention 对于各种网络,各种任务,各个数据集都表现很好
- 基于激活函数的迁移还可以跟蒸馏结合起来
基于激活函数的attention map
本文指出,attention的本质就是一个空间映射,就是将那些对输出空间决策影响大的输入空间进行编码。那么,问题来了,这样的attention information能否被可视化呢?事实证明,古往今来,许多能人志士在这方面做了许多工作。想深入了解的,参考原文。attrntion的可视化如下图所示:
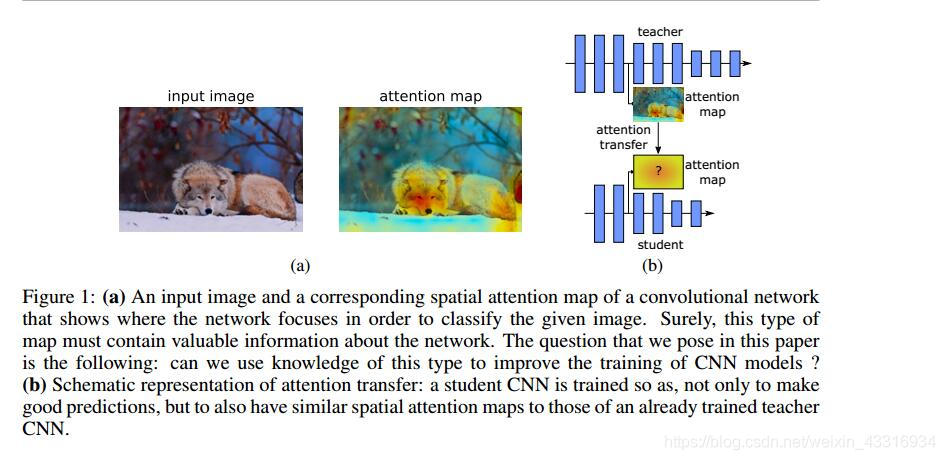 在定义attention map之前,我们做了一个跟实际情况相符的假设:如果一个隐藏神经元输出的激活函数值的绝对值越大,代表这个神经元越重要,越值得我们attention它。因此,我们定义attention map的作用就是,将激活函数输出的张量
A
∈
R
C
∗
H
∗
W
A\in\\R^{C*H*W}
A∈RC∗H∗W ,在filter个数的维度上压平。即:
在定义attention map之前,我们做了一个跟实际情况相符的假设:如果一个隐藏神经元输出的激活函数值的绝对值越大,代表这个神经元越重要,越值得我们attention它。因此,我们定义attention map的作用就是,将激活函数输出的张量
A
∈
R
C
∗
H
∗
W
A\in\\R^{C*H*W}
A∈RC∗H∗W ,在filter个数的维度上压平。即:
F
:
R
C
∗
H
∗
W
→
R
H
∗
W
F: R^{C*H*W}\to\\R^{H*W}
F:RC∗H∗W→RH∗W
现在,目标明确了,我们要构建一个attention映射,目的是得到tensor A中元素在filter通道维度C上的绝对值统计量。文章给了我们三种方案:
- F s u m ( A ) = ∑ i = 1 C ∣ A i ∣ F_{sum}(A)=\sum_{i=1}^C |A_i| Fsum(A)=∑i=1C∣Ai∣, F等于A在维度C上的绝对值之和
- F s u m p ( A ) = ∑ i = 1 C ∣ A i ∣ p F_{sum}^p(A)=\sum_{i=1}^C|A_i|^p Fsump(A)=∑i=1C∣Ai∣p,F等于A在维度C上的绝对值的P次方之和
-
F
m
a
x
p
(
A
)
=
m
a
x
i
=
1
:
C
∣
A
i
∣
p
F_{max}^p(A)=max_{i=1:C}|A_i|^p
Fmaxp(A)=maxi=1:C∣Ai∣p
实验表明:
(1)、我们计算得到的统计量不仅和图像中预测的物体具有空间相关性(网络精度越高,空间相关性越强),并且,强网络还会出现attention峰值,这也就验证了,attention在图像识别中举足轻重的地位。
(2)、我们观察到,在同一网络中,不同层的attention map关注的点不同。比如,低级的层关注低梯度点,中级的层关注高差异的区域,即激活函数输出大的区域,高级的层关注整个物体。
(3)、第二种attention map更关注差异最大的那部分,即激活函数输出值最大的区域;第三种attention map只会为一个差异最大的小区域分配权重。
那么,神经网络有那么多层,我们要在哪些激活函数后面插入注意迁移层呢?
本文提出,当教师网络和学生网络深度相同时,注意前一层放置在每个残差块结构的后面;当教师网络和学生网络层数不同时,transfer attention layer放置在每个残差块组(N个残差块)的后面。
完事具备,只差给出损失函数:
L A T = L ( W s , x ) + β 2 ∑ j ∈ I ∣ ∣ Q S j ∣ ∣ ∣ ∣ Q S j ∣ ∣ 2 − Q T j ∣ ∣ ∣ ∣ Q T j ∣ ∣ 2 ∣ ∣ p L_{AT}=L(W_s,x)+\frac{\beta}{2}\sum_{j\in I}||\frac{Q_S^j||}{||Q_S^j||_2}-\frac{Q_T^j||}{||Q_T^j||_2}||_p LAT=L(Ws,x)+2βj∈I∑∣∣∣∣QSj∣∣2QSj∣∣−∣∣QTj∣∣2QTj∣∣∣∣p
其中, L ( W s , x ) L(W_s,x) L(Ws,x)表示学生网络的标准交叉熵损失函数,保证了学生网络的预测精度,而后面一部分则是使得学生网络的attention map可以逼近教师网络的attrntion,实现attention的迁移。 Q S j Q_S^j QSj和 Q T j Q_T^j QTj就表示为之前上面三种attention map输出的向量化形式,i.e:
Q T j = v e c ( F ( A i j ) ) Q_T^j=vec(F(A_i^j)) QTj=vec(F(Aij)),F函数可以三选一,本论文用的是第二种,且p=2。
基于梯度的attention transfer
除了之前提出的基于激活函数的attention transfer,更关注激活函数输出的绝对值大的区域,即差别大的区域之外。作者还提出,我们还attention那些对输出影响大的区域。例如,只改动输入图像很小的一个像素块,就能使得输出发生巨大变化,我们就可以认为,这个像素块值得我们attention。
定义:
J
S
J_S
JS:损失函数对学生网络的输入的导数
J
S
=
∂
L
(
W
S
,
x
)
∂
x
J_S=\frac{\partial L(W_S,x)}{\partial x}
JS=∂x∂L(WS,x)
J
T
J_T
JT:损失函数对教师网络的输入的导数
J
=
∂
L
(
W
T
,
x
)
∂
x
J_=\frac{\partial L(W_T,x)}{\partial x}
J=∂x∂L(WT,x)
如上述分析,我们要做的就是使得
J
S
J_S
JS逼近于
J
T
J_T
JT,就迁移了对网络输出影响大的区域。因此,得出目标函数为:
L
A
T
(
W
S
,
x
)
=
L
(
W
S
,
x
)
+
β
2
∣
∣
J
S
−
J
T
∣
∣
2
L_{AT}(W_S,x)=L(W_S,x)+\frac{\beta}{2}||J_S-J_T||_2
LAT(WS,x)=L(WS,x)+2β∣∣JS−JT∣∣2此处用的是
l
2
l_2
l2距离,也可以尝试使用其他的距离公式。在目标函数中
W
T
W_T
WT是已知的,可是
W
S
W_S
WS是未知的。为了求解这个函数,作者引用了二次传播的方法。即先正向传播,再反传播,从而得到
J
T
J_T
JT,
J
S
J_S
JS,再利用如下推导:
∂
L
A
T
∂
W
S
=
∂
L
(
W
S
,
x
)
∂
W
S
+
β
(
J
S
,
J
T
)
∂
2
L
(
W
S
,
x
)
∂
W
S
∂
x
\frac{\partial L_{AT}}{\partial W_S}=\frac{\partial L({W_S,x)}}{\partial W_S}+\beta(J_S,J_T)\frac{\partial ^2L({W_S,x)}}{{\partial W_S}{\partial x}}
∂WS∂LAT=∂WS∂L(WS,x)+β(JS,JT)∂WS∂x∂2L(WS,x)就可对
W
S
W_S
WS进行更新。
代码部分
代码部分沿用了作者写的第一个实验,用基于激活函数的attention map,实现attention transfer以及knowledge distillation。注意,pytorch要更新到0.4.0以上的版本,不然,你可能会像我一样,看了两个小时,不知道错在哪儿。可能是我太笨了。
言归正传:
第一步:
运行python cifar.py --save logs/resnet_16_2_teacher --depth 16 --width 2,搭建并训练一个16_2的教师网络,损失函数就是用的标准交叉熵。
第二步:
运行python cifar.py --save logs/at_16_1_16_2 --teacher_id resnet_16_2_teacher --beta 1e+3,搭建并用atttention transfer算法训练一个16_1的学生网络
第三步:
运行python cifar.py --save logs/kd_16_1_16_2 --teacher_id resnet_16_2_teacher --alpha 0.9,搭建并用knowledge distillation 训练一个16_1的学生网络。
好了,至此,第一部分实验就结束了,是不是很easy。我的github上有完整的注释,当然,我也是小白水平,错误之处,欢迎联系我。请指正。
就酱~~~

















 6217
6217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









