







 本文档详细介绍了PL/0语言编译器的实现,包括词法分析、语法分析、中间代码生成和解释执行等功能,并对PL/0进行了功能扩展,如I/O、数组类型、for/break语句的支持。此外,还提供了IDE图形化界面设计的指导,以增强PL/0的使用体验。实验总结了编译器设计的挑战和经验,强调了实现过程中的困难和问题。
本文档详细介绍了PL/0语言编译器的实现,包括词法分析、语法分析、中间代码生成和解释执行等功能,并对PL/0进行了功能扩展,如I/O、数组类型、for/break语句的支持。此外,还提供了IDE图形化界面设计的指导,以增强PL/0的使用体验。实验总结了编译器设计的挑战和经验,强调了实现过程中的困难和问题。
编译原理大作业-PL0语言编译器
一、实验目的
根据所学的编译原理理论知识,在符合 PL/0 语言基本词法、语法规则的前提下,以原PL/0 编译程序C语言版本代码为基础,对 PL/0 语言的功能进行扩充。使理论与实践相结合,加深对编译原理的理解。
二、源码说明
源码一共有两个版本。

一个是融合了编译器与解释器的主体代码pl0.cpp,实现编译执行的功能。另一个则是将主体代码拆分为编译器、解释器两部分,分别执行编译、执行的功能,这些代码都用到同一个pl0.h文件。因为逻辑相同,这里主要以主体代码为例进行说明。
1、头文件pl0.h
该文件主要定义了程序中用到的各数据结构,说明了程序中出现的函数。
(1 词法分析主要数据结构(通过enum symbol类实现)
PL/0单词种类一共5类(含新增)
1、保留字(13+4个):
begin、end、if、then、while、do、var、const、odd、procedure、call、read、write、break、 for、step、until
2、运算符及界符(16+2个):
:= + - * / < <= = >= > # ( ) , ; . [ ]
3、标识符
4、无符号整数
5、字符串

(2 中间代码生成与解释执行数据结构
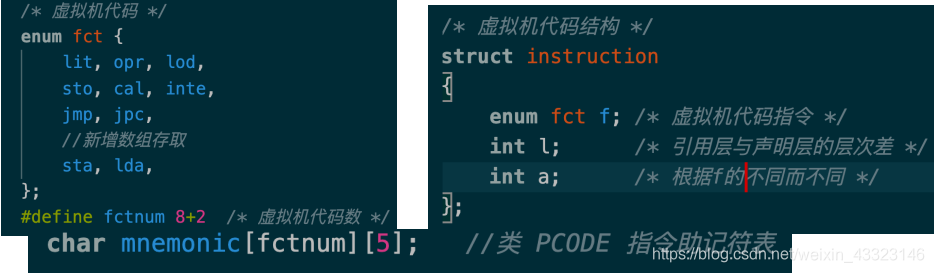
类Pcode由F L A三部分构成,实现结构为struct instruction
(3 符号表管理数据结构
类型通过object进行分类,所有符号管理为内存中的table数组

(4 错误处理数据结构

开始、后跟符号集用于错误恢复,错误数组用于存储、输出错误信息

预定义的替换字串使得语法分析在出错时能够直接停止
2、源文件pl0.cpp
源程序可以分为初始化、主程序、词法分析、语法(+语义)分析、中间代码生成、解释执行、集合运算、出错处理、符号表管理9个模块,接下来逐一进行说明。

(1 初始化init()
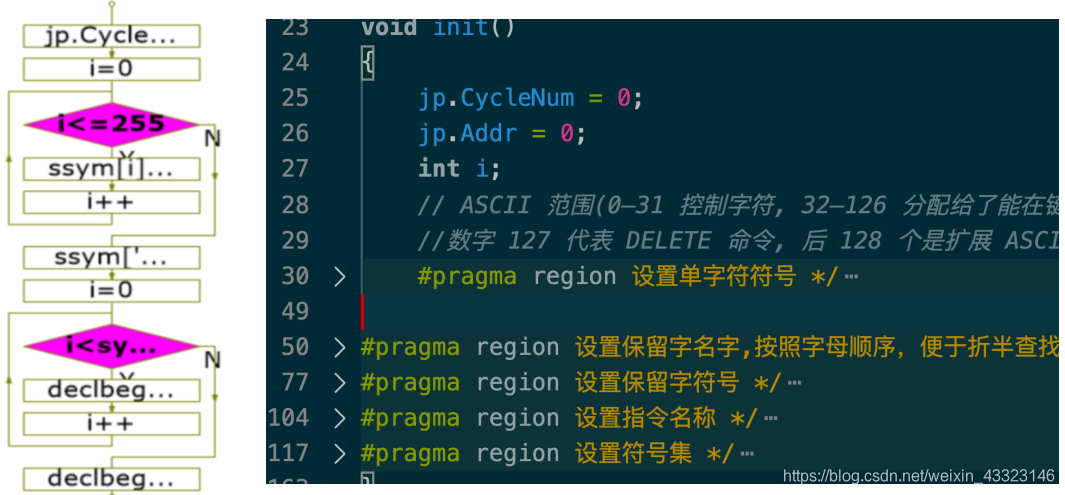
进行运行前初始化,对保留字表 (word)、保留字表中每一个保留字对应的 symbol 类型 ( wsym )、部分符号对应的 symbol 类型表 ( ssym )、类 PCODE 指令助记符表 ( mnemonic )、开始以及后跟符号集合 ( declbegsys、statbegsys等)以及一些全局变量的初始化
(2 main函数
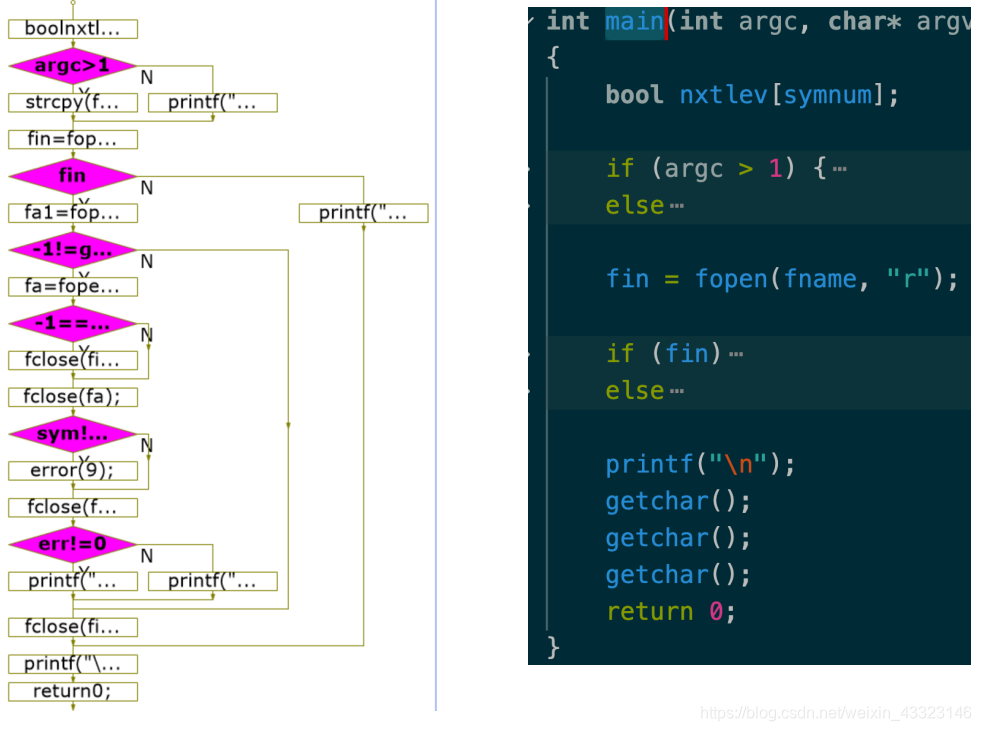
为了方便从EditPlus执行,设定为从命令行读取参数,没有则手动输入。函数在打开pl0源程序文件后,会条用block进行分析,生成fa1.tmp、out.tmp等文件,其中fa.pcode文件输出虚拟机代码,若无错误则会调用解释器进行解释。
(3 词法分析
getch()函数

主要功能为读取一个字符放在全局变量ch里面,同时输出源代码以及行号。该函数读取pl0文件中一行,存入line缓冲区,line被getsym取空后再读一行。每次从line缓冲区读出一个字符放在全局变量ch里面,被函数getsym调用。
getsym()函数
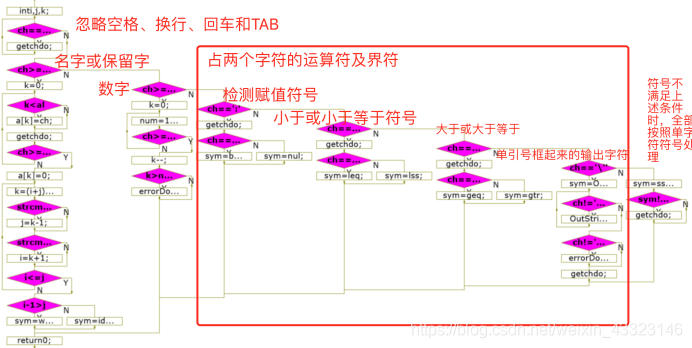

词法分析从源文件中读出若干有效字符,组成一个 token 串,识别它的类型为保留字、标识符、数字或是其它符号。如果是保留字,把 sym 置成相应的保留字类型,如果是标识符,把 sym 置成 ident 表示是标识符,于此同时,id 变量中存放的即为保留字字符串或标识符名字。如果是数字,把 sym 置为 number,同时 num 变量中存放该数字的值。如果是字符串,把 sym 置为 OutStr,同时OutString 变量中存放该字符串的值。如果是其它的操作符,则直接把 sym 置成相应类型。经过本函数后ch 变量中存放的是下一个即将被识别的字符
(4 语法分析+语义分析
语法分析主要根据PL/0的EBNF,使用递归子程序法对每个语法单位编写分析程序,实现语法分析。在语法分析的过程中,通过testdo、nxtlev符号集实现错误处理,通过gendo实现语义分析的中间代码生成
block()函数
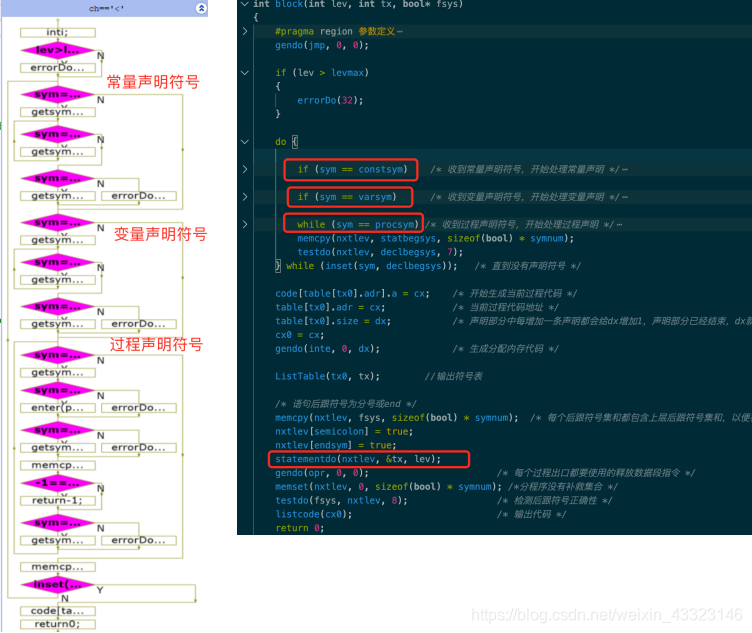
此函数为编译程序主模块,lev参数为当前分程序所在层,tx为符号表当前尾指针,fsys为当前模块后跟符号集。
statement ()函数

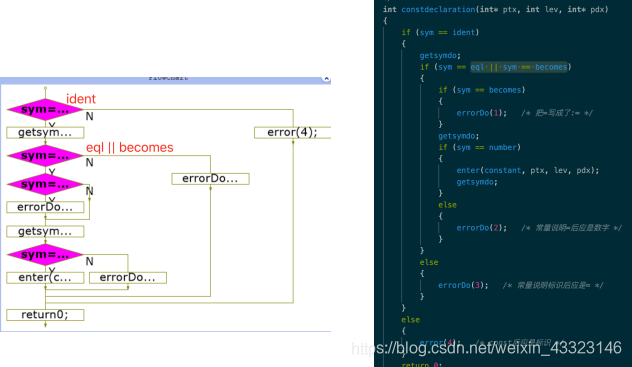
constdeclaration ()函数
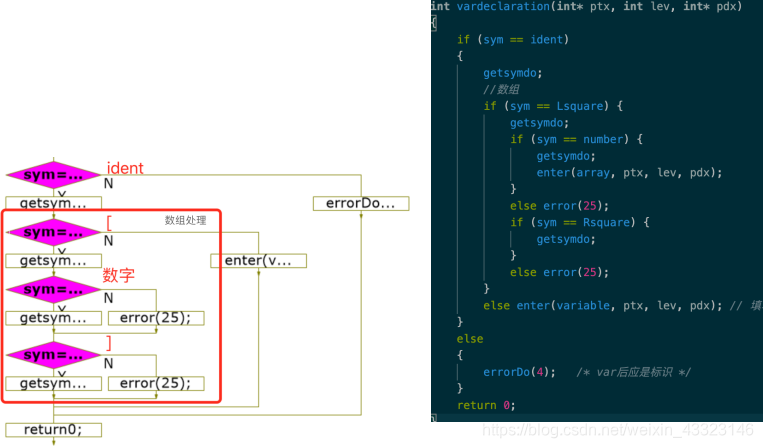
vardeclaration ()函数
expression ()函数

term ()函数
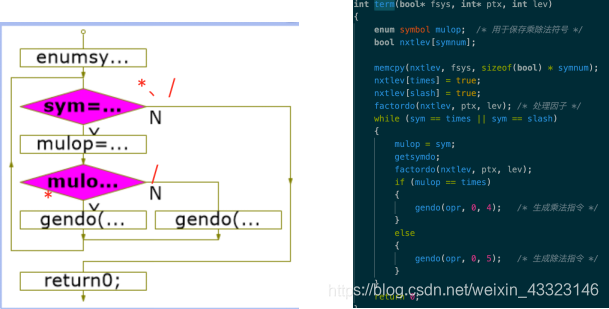
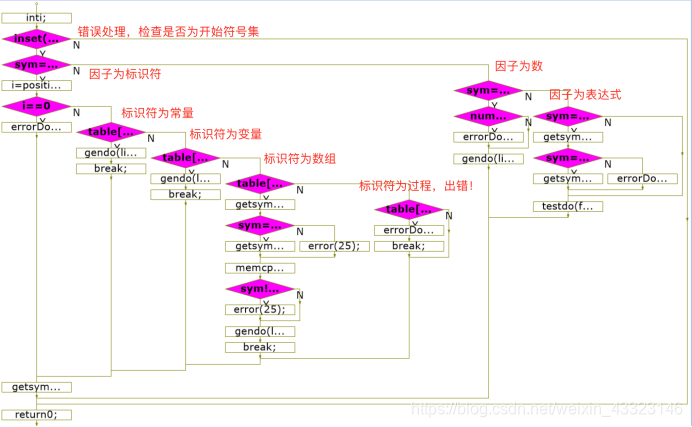
factor ()函数

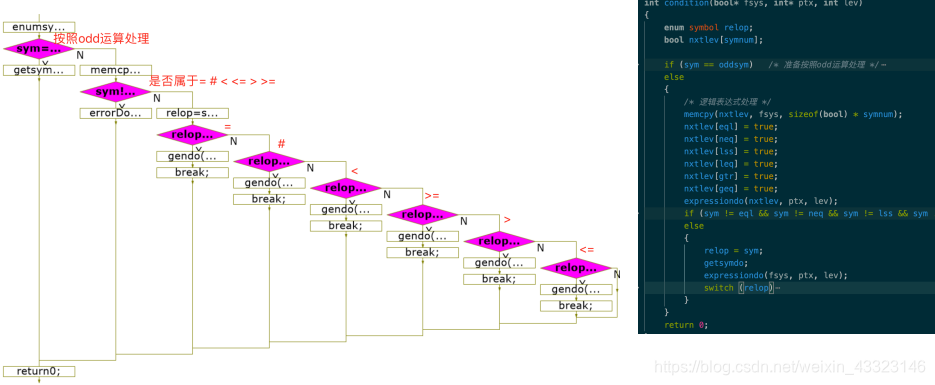
condition ()函数
(5 中间代码生成
gen ()函数
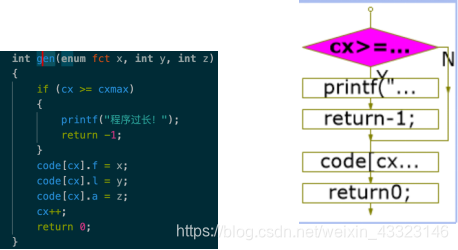
依据传入的参数,在code数组中生成一行新Pcode并增加其尾指针
listcode ()函数

依据传入的code数组指针,将code数组中存储的Pcode打印到控制台以及fa.pcode文件中
(6 解释执行
base ()函数

求出定义该过程的过程基址,l为层次差,b为上一过程(调用该过程的过程)基址,s为栈
interpret ()函数
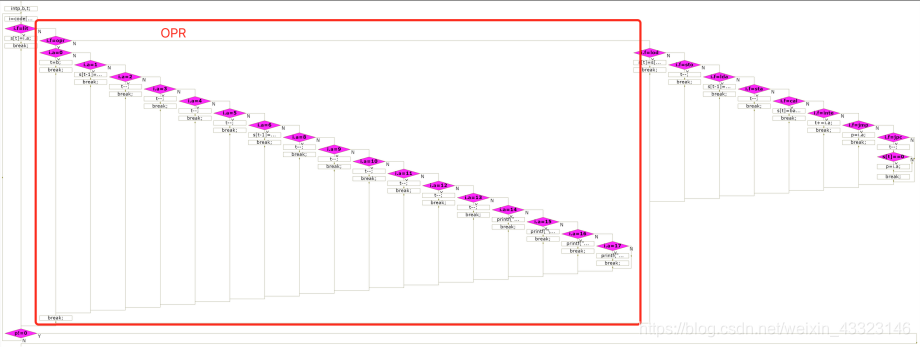

该函数根据code数组存储的指令一个个执行,直到遇到opr 0,0。其指令运行的逻辑结构为一个栈s与三个寄存器b,p,t,b为基地址,p为下一指令地址,t为栈顶指针
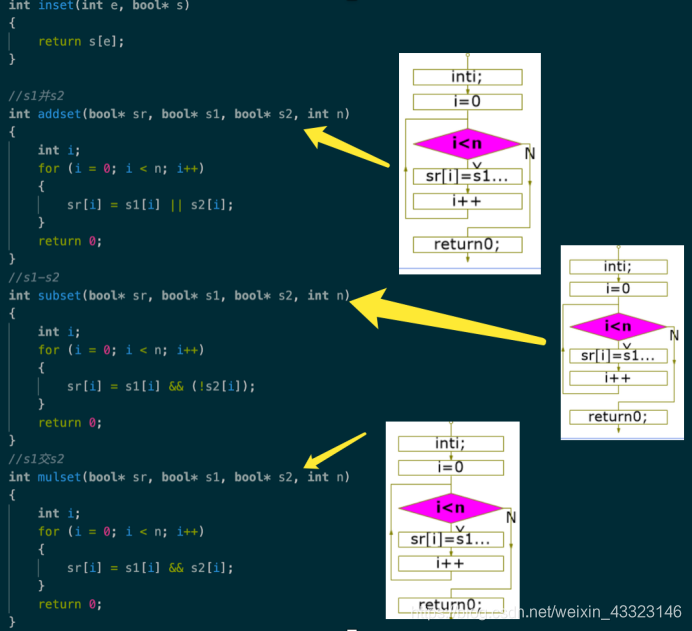
(7 集合运算
(8 出错处理

函数error()打印出错位置和错误编码
函数test ()采用短语层恢复思想测试当前符号是否合法
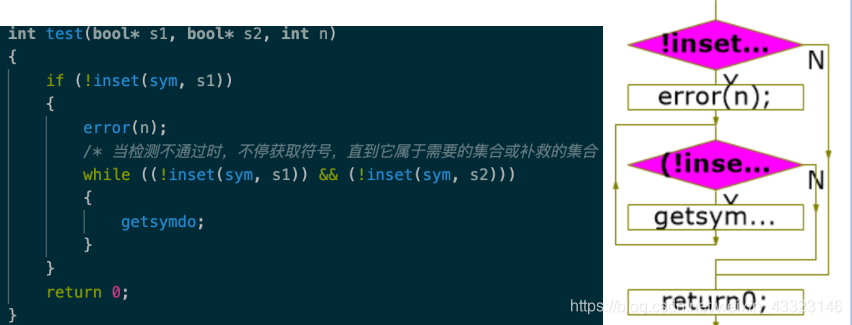
在某一部分(如一条语句,一个表达式)将要结束时,test负责检测下一个符号属于该部分的后跟符号集合和补救用的集合,检测不通过时报错错误号为n。
(9 符号表管理
函数enter ()
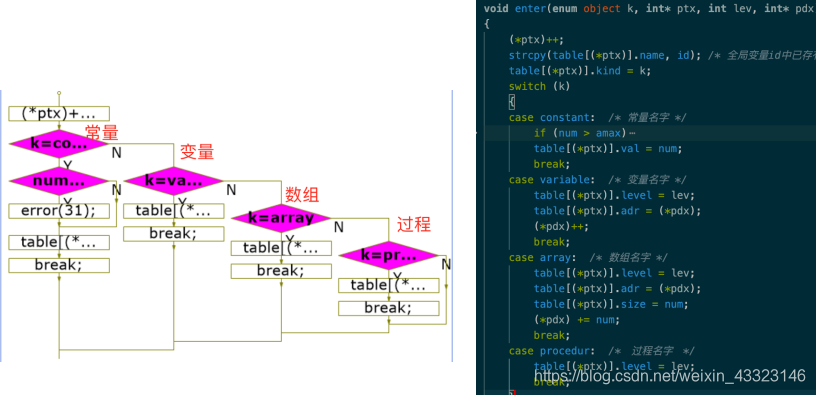 该函数依据传入的符号类型不同采取不同的填表策略。
该函数依据传入的符号类型不同采取不同的填表策略。
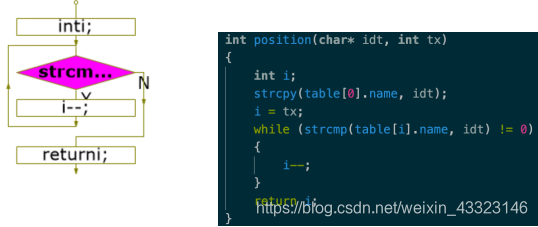
函数position ()查找符号的位置,从后往前,保证先看此过程局部变量再看其他的。找到则返回在名字表中的位置,否则返回0.
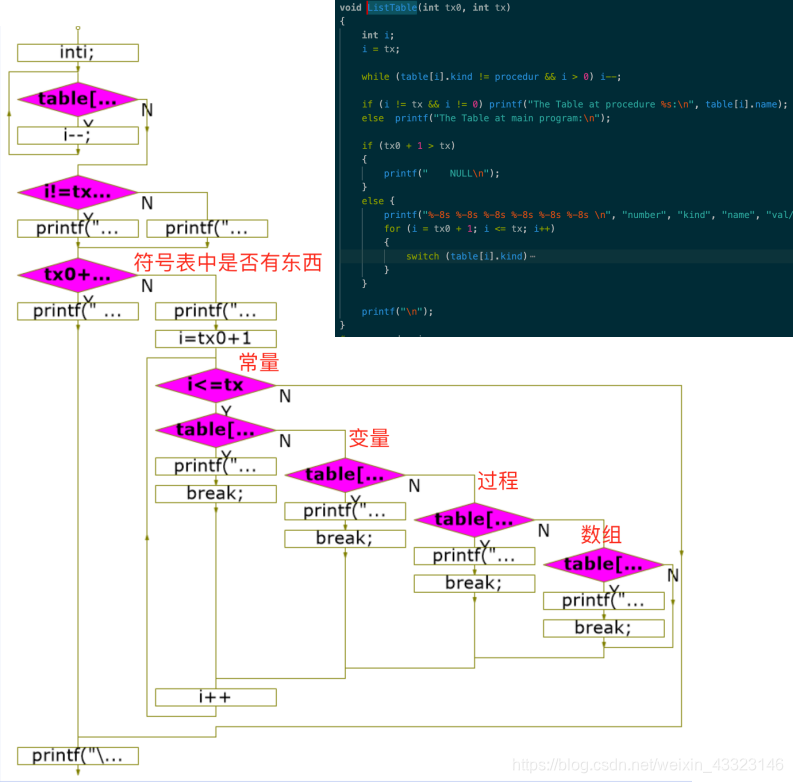
函数ListTable ()输出符号表
三、PL/0 编译器功能的扩展
(1)I/O 功能扩展
思路:增加“字符串”语法单位仿C++的输出格式,可输入数字,直接输出字符串以及数字,主要修改write()
原EBNF:
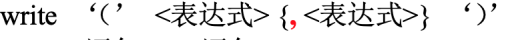
修改后:
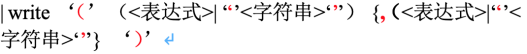
步骤:
1、增加数据结构
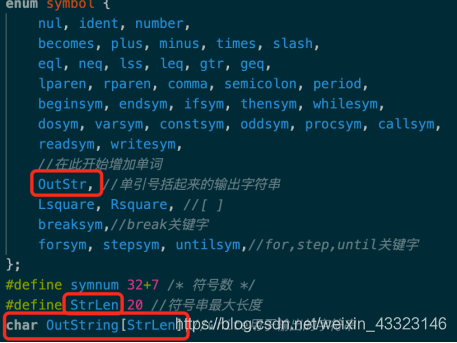
2、修改getsym()
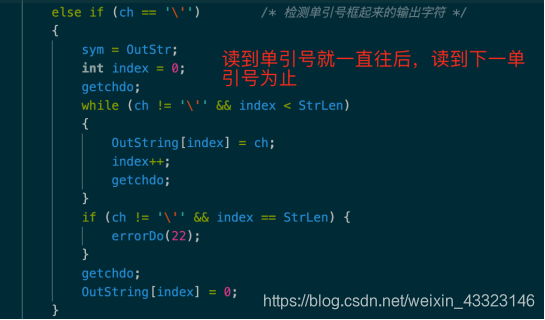
3、修改statement中对write的分析
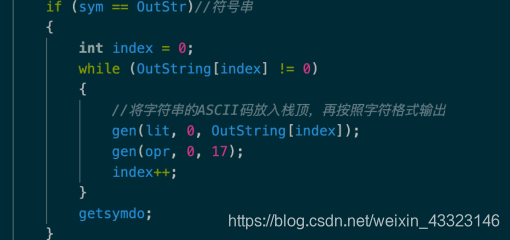
4、增加一条Pcode指令,修改解释器,使其能将栈顶ASCII码输出为字符
(2)增加数组类型(数据结构+计算功能上的支持)
思路:增加“[”、“]”语法单位,仿C、C++数组格式,可存储整数,顺序存放,以首地址+偏移量进行存取,数组索引可以是表达式以方便批量操作。
由于存取需要两个数,需修改类Pcode指令,新增数组存取指令sta,lda。
read、write语句需要对数组输入输出进行支持。
输入数字,直接输出字符串以及数字,主要修改write()
原EBNF

修改后:

步骤:
1、增加数据结构

2、修改初始化参数

3、修改vardeclare()
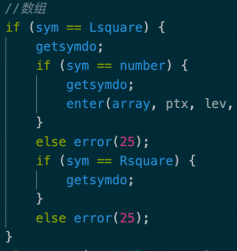
4、修改statement() 标识符、read语句的解析

5、修改factor()
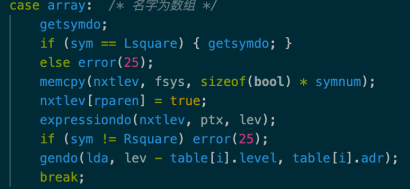
6、修改符号表填写enter(),将block函数尾部输出符号表的动作归纳,新增符号表输出ListTable 函数,在其中增加数组的输出。
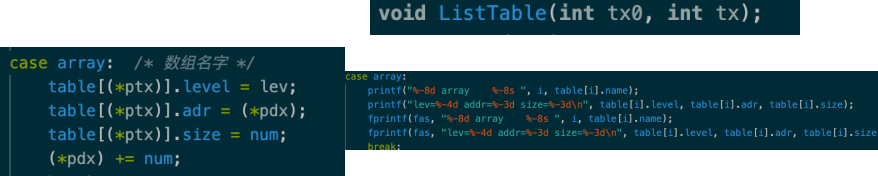
(3)增加for、break语句
思路:for语句实现类似于while语句,参照while语句的实现进行实现,与while语句对照如下:

因此只需要在while的基础上,添加两条i变量的赋值语句即可
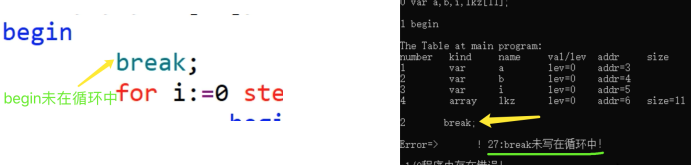
对于break,只需要生成跳出循环的类Pcode即可,但涉及到跳出哪个循环的问题。
EBNF新增
<语句> ::= break
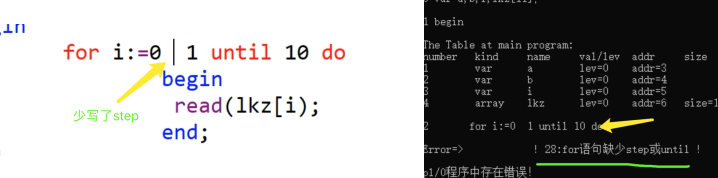
| for <语句> step <表达式> until <表达式> do <语句>
步骤
1、增加数据结构

2、增加初始化参数

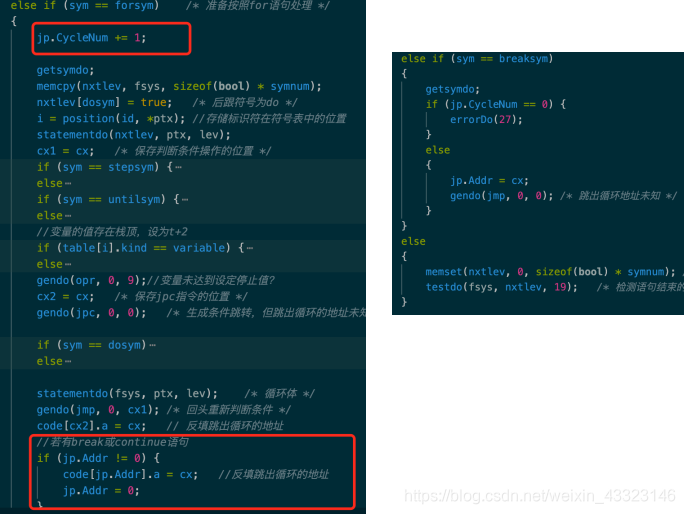
3、statement()函数增加for、break语句判断,其中用到全局变量jp来填写跳出循环地址,判断跳出的循环是哪一层
(4)新增功能的错误处理
思路:
PL/0 采用短语层恢复的思想。test函数能实现一个语法单位的合法性测试。如果该单位中出错,则有节制地跳读一部分代码。test的参数S1为合法符号集合,S2为停止符号集合,n为错误编码。调用test时,程序会不断跳读直到得到S1或S2中的符号。
同时,在pl0编译系统中有行号计数器,可以记录错误发生的位置,错误发生后,可以查看错误代码位置。因此,只需要将新增功能的First集与Follow集添加到原有的集合中,再增加新的错误提示代码即可。
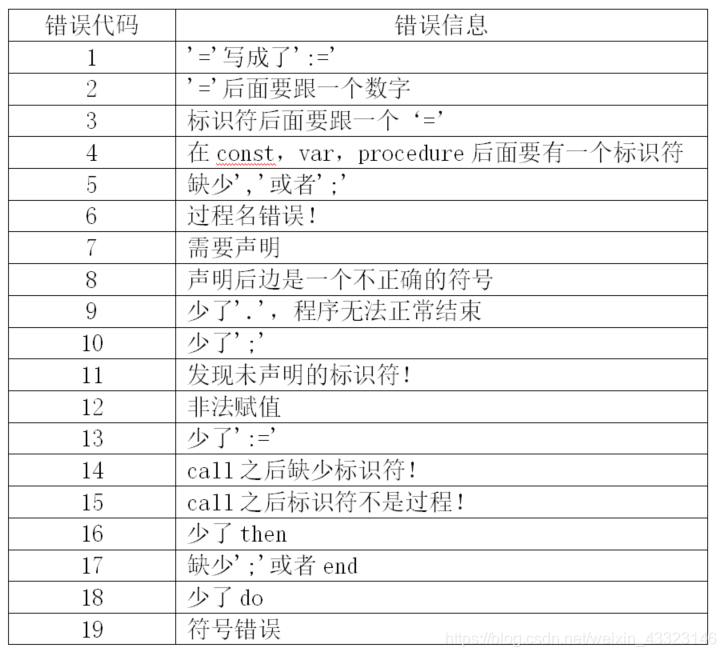
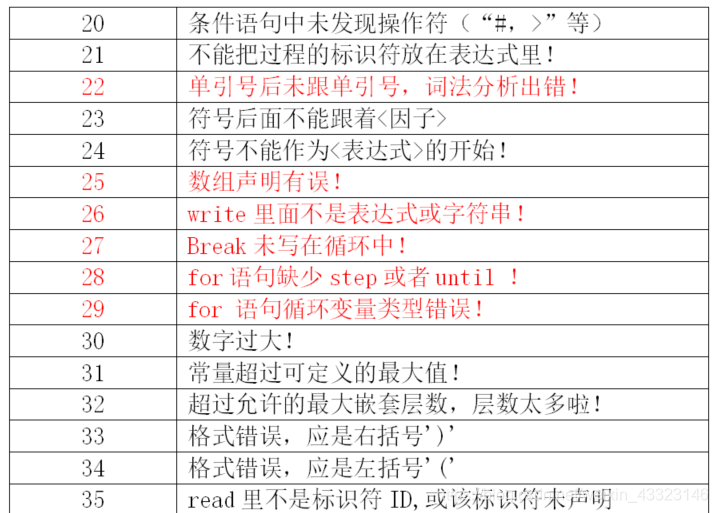
原PL/0程序只有错误编号,关于错误编号具体对应的错误,没有说明,也就是说,原PL0程序出错只能知道错误的位置而不能知道错误类型。因此还需重新整理编号错误类型,增加一个数组存储错误信息并输出。(这里整理的错误编号见附录。)
步骤
1、新增数据结构
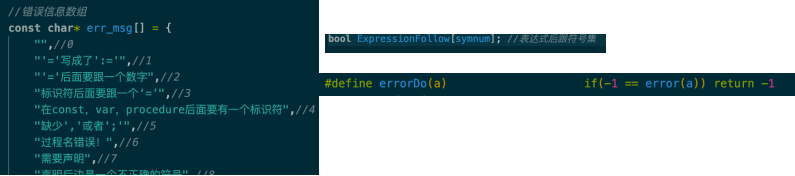
2、增加数据初始化
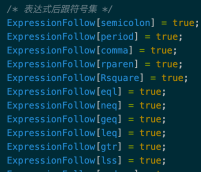
3、整理错误号,对所有错误信息汇总(见附录)
4、对新增功能增加错误判断(部分)

5、使error函数能够输出错误信息
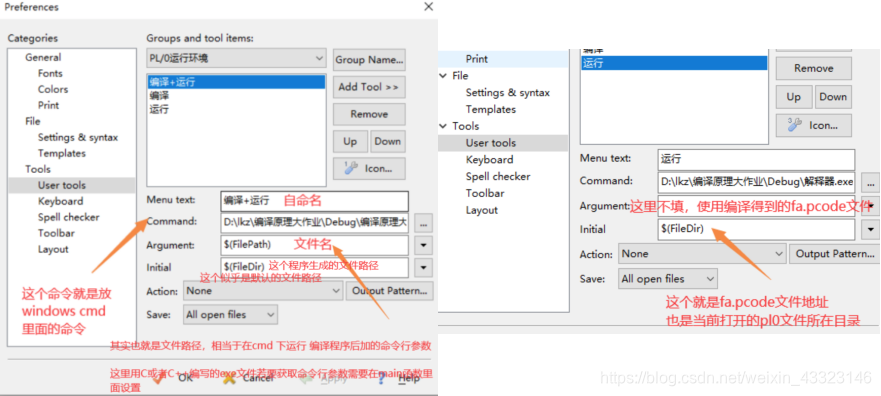
(5)IDE图形化界面设计(EditPlus可在官网下载,配置文件见压缩包)
思路:可以在已有的各文本编辑器里面添加插件或者配置文件,以使其支持PL/0语言。由于VScode、Sublime配置过于复杂,不考虑。而UltraEdit等又过于臃肿,相比之下,小巧轻便的EditPlus可以很方便的配置PL/0语言编译环境
1、配置代码高亮(.stx文件)
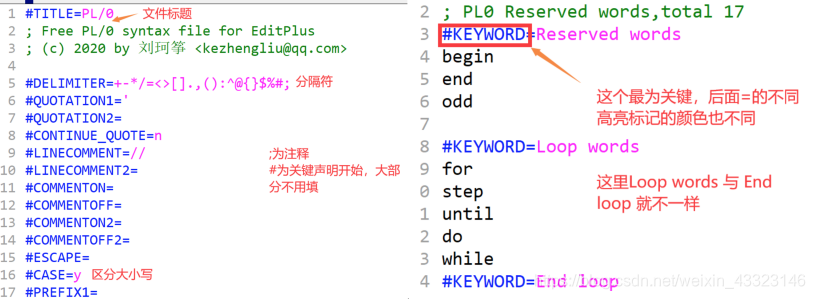
编辑好后按.stx文件保存即可
2、配置自动补全(.acp文件)
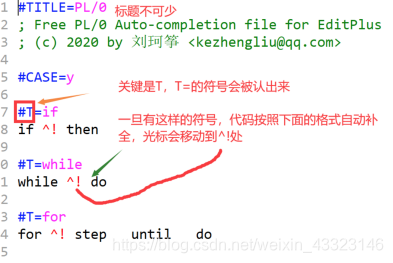
3、将acp、stx文件放入EditPlus中
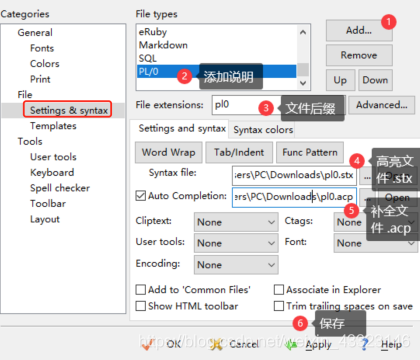
4、配置运行文件,使得EditPlus能够对PL/0源程序进行编译、执行
注意这些exe文件需要有对命令行输入的处理,也就是在main函数中有arg等参数。
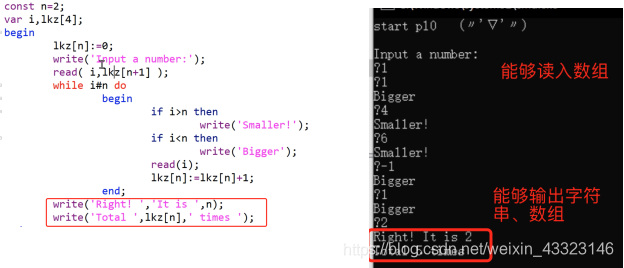
四、成果展示
(1)输入输出(猜大小,值为2)
(具体代码见T1格式化输入输出.pl0文件)
(2)数组结构的运算
(具体代码见 T2数组结构运算.pl0文件)
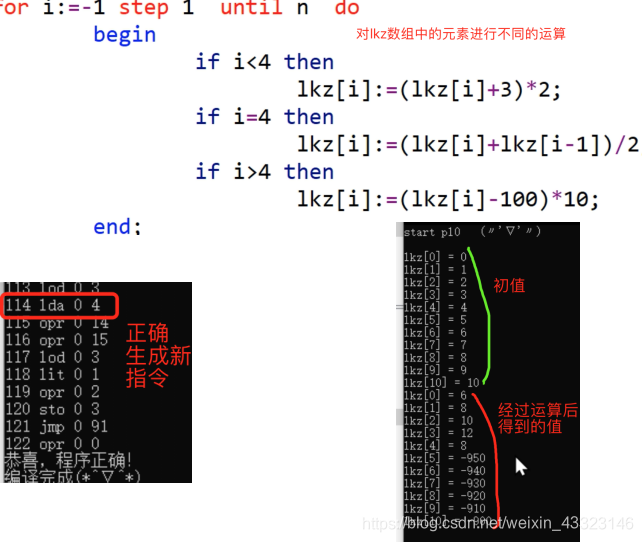
经过运算比较,得出结果正确
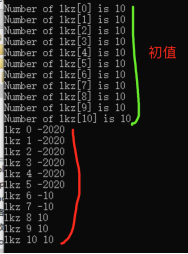
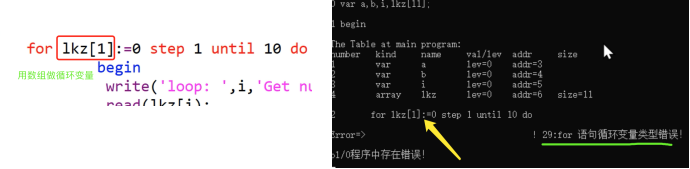
(3)for循环,break语句
(具体代码见 T3for与break.pl0文件)
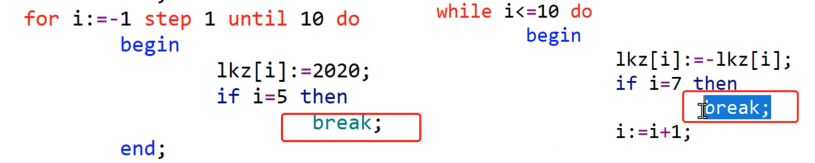
在for循环中把lkz[i]数组前0-4项赋值为2020,在while循环中把lkz数组前0-6项取相反数。
可以看到break使循环停止
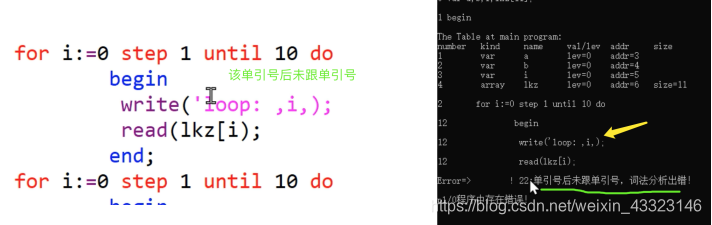
(4)错误处理
(错误检测的验证代码见 E22-E29.pl0文件)
新加入功能:若错误超过一定值则不往下生成Pcode,自动停止
E22:
E25:

E27:
E28:
E29:
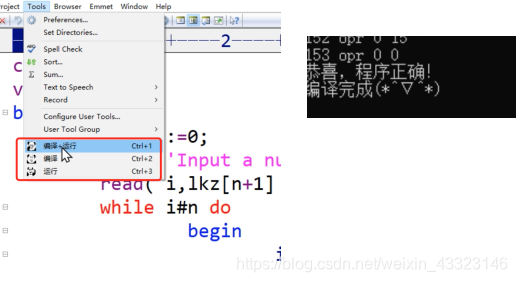
(5)IDE功能(自动补全、代码折叠、编译运行等)
打开.pl0文件,按下图所示快捷键即可编译、运行、编译运行。
敲出begin、if等关键字时,按下空格键自动补全:

代码高亮
代码折叠

五、总结
本次实验对PL/0语言的编译程序进行了功能上的扩充。在原理上,深刻理解了一个语言编译器的运作过程,对其逻辑上7大部分的模型体会更深。
值得一提的是,PL/0语言编译器因仅用于研究编译器原理,没有代码优化、目标代码生成部分其生成的中间代码直接通过C语言编译器生成的解释器程序运行在机器上,本质上是应用的C语言的跨平台性。
一个优秀的编译器并不是随随便便就能写出来的。即便是对一个简单的编译器做修改,本次实验仍在实现过程中遇到了相当多的问题。可想而知做一门强大、复杂语言的编译器是一个多复杂、困难的事情。
代码仍可能存在一些 bug,虽然在自己的测试代码下没遇到问题,但仍无法保证其对所有pl0代码都能正确编译执行。
六、参考
1、https://www.allhuo.com/2009/04/01/%E5%A6%82%E4%BD%95%E5%9C%A8-editplus-%E4%B8%AD%E5%88%9B%E5%BB%BA%E8%AF%AD%E6%B3%95%E6%96%87%E4%BB%B6%E8%87%AA%E5%AE%9A%E4%B9%89%E8%AF%AD%E6%B3%95%E9%AB%98%E4%BA%AE/
2、https://www.cnblogs.com/picaso/archive/2012/03/07/2383620.html
3、《编译原理》第3版 王生原 清华大学出版社
七、附录
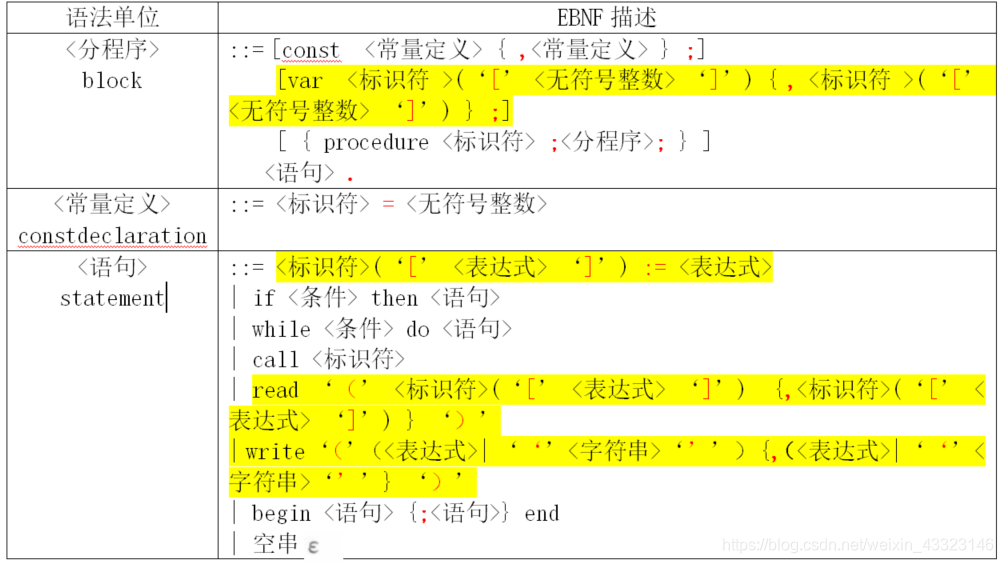
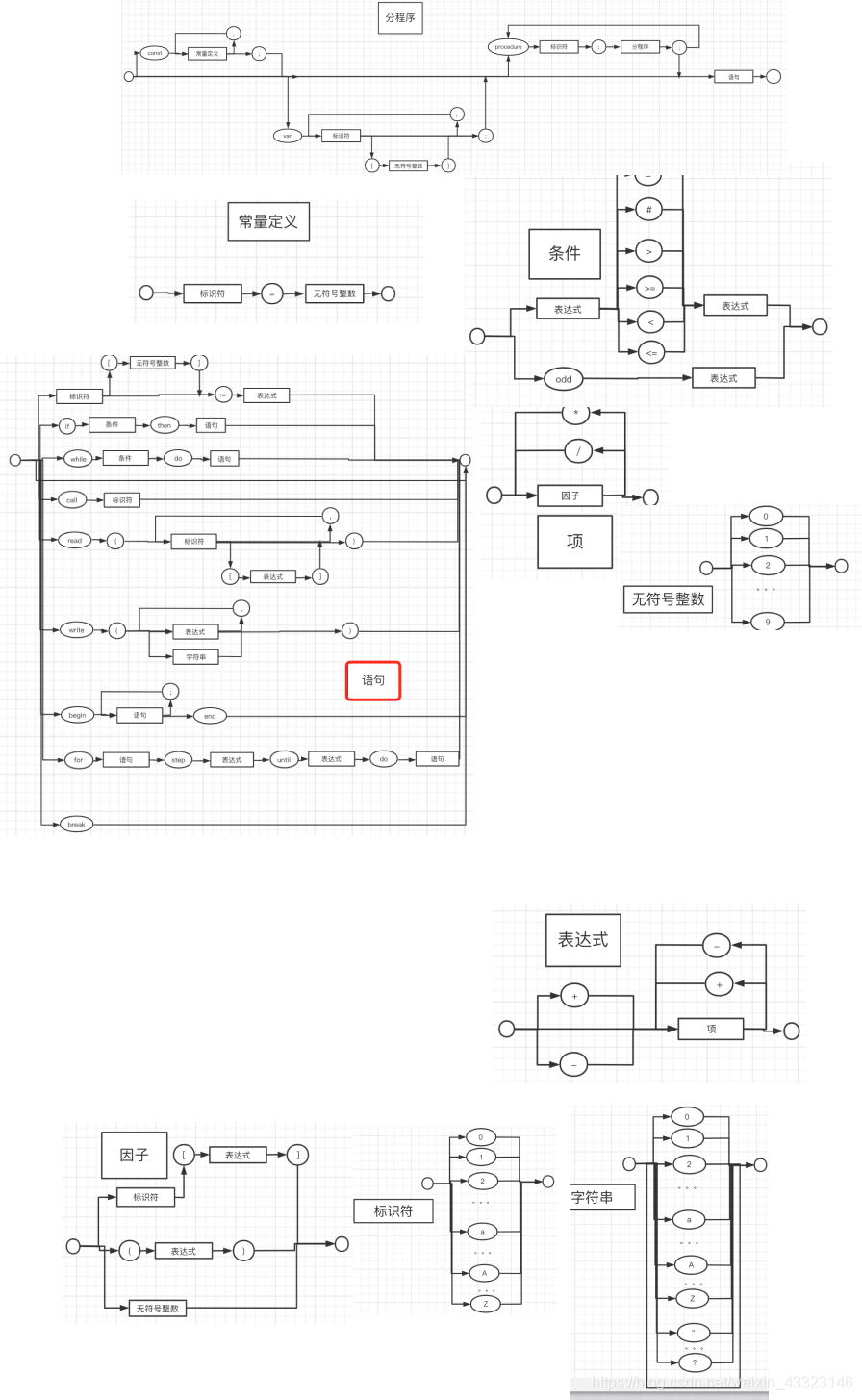
1、PL/0 EBNF描述(新增修改的EBNF已标黄)

2、PL/0 语法图
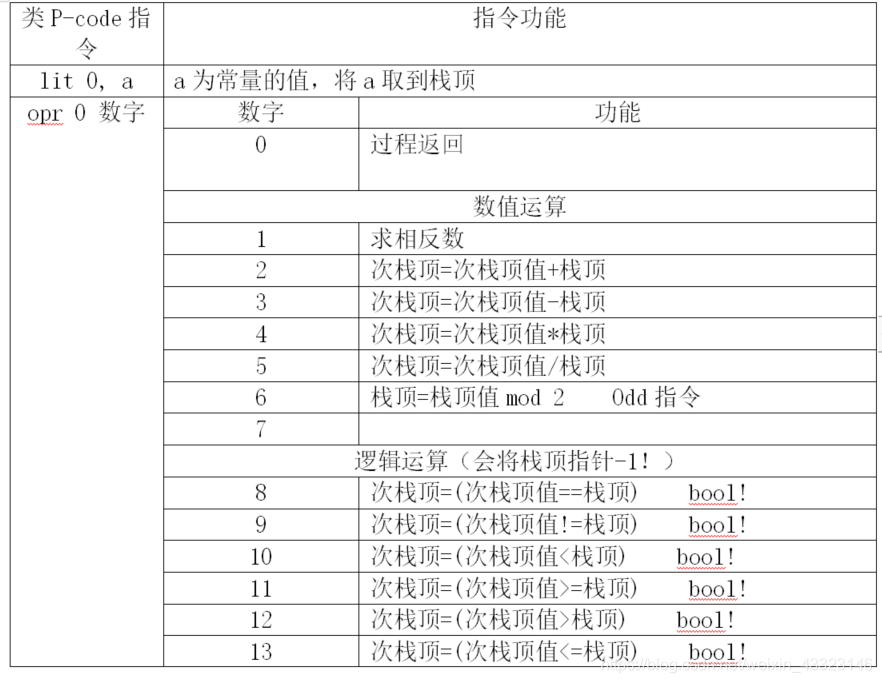
3、类P-code表(新增指令已标红)
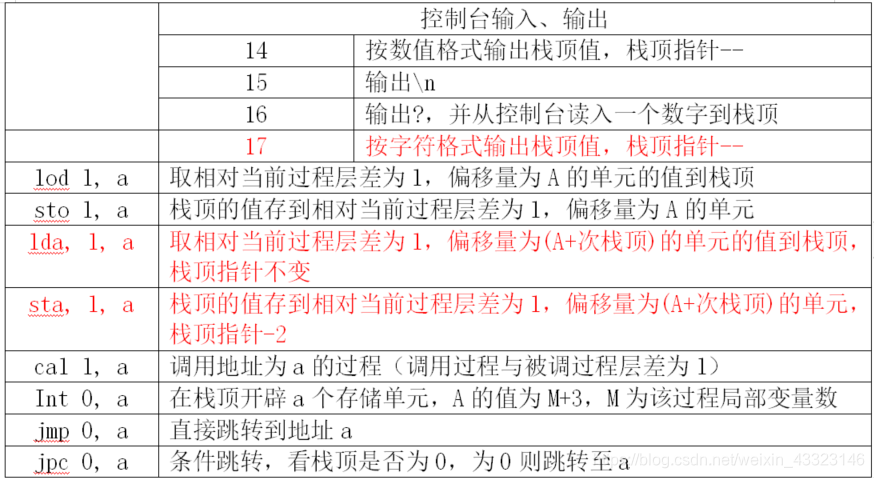
4、错误编号汇总(新增已标红)
5、代码
pl0.h
#pragma once
#include <stdio.h>
#define norw 13+4 /* 保留字个数 */
#define txmax 100 /* 名字表容量 */
#define nmax 14 /* 数字的最大位数 */
#define al 10 /* 标识符的最大长度 */
#define amax 2047 /* 常量最大值 */
#define levmax 3 /* 最大允许过程嵌套声明层数 [0, levmax]*/
#define cxmax 1000 /* 最多的虚拟机代码数 */
#define stacksize 500 /* 解释执行时使用的栈 */
//由16+2个运算符及界符,13+4个保留字还有数字、标识符+字符串构成
enum symbol {
nul, ident, number,
becomes, plus, minus, times, slash,
eql, neq, lss, leq, gtr, geq,
lparen, rparen, comma, semicolon, period,
beginsym, endsym, ifsym, thensym, whilesym,
dosym, varsym, constsym, oddsym, procsym, callsym,
readsym, writesym,
//在此开始增加单词
OutStr, //单引号括起来的输出字符串
Lsquare, Rsquare, //[ ]
breaksym,//break关键字
forsym, stepsym, untilsym,//for,step,until关键字
};
#define symnum 32+7 /* 符号数 */
#define StrLen 20 //符号串最大长度
char OutString[StrLen];//write用于输出的字符串
/* 虚拟机代码 */
enum fct {
lit, opr, lod,
sto, cal, inte,
jmp, jpc,
//新增数组存取
sta, lda,
};
#define fctnum 8+2 /* 虚拟机代码数 */
/* 虚拟机代码结构 */
struct instruction
{
enum fct f; /* 虚拟机代码指令 */
int l; /* 引用层与声明层的层次差 */
int a; /* 根据f的不同而不同 */
};
FILE* fas; /* 输出名字表 */
FILE* fa; /* 输出虚拟机代码 */
FILE* fa1; /* 输出源文件及其各行对应的首地址 */
FILE* fa2; /* 输出结果 */
char ch; //用于词法分析器,存放最近一次从文件中读出的字符,getch使用
enum symbol sym; // 词法分析器输出结果之用,存放最近一次识别出来的 符号token 的类型
char id[al + 1]; // 词法分析器输出结果之用,当前ident, 多出的一个字节用于存放0
int num; // 词法分析器输出结果之用,当前number
int cc, ll; // getch使用的计数器,cc表示当前字符(ch)的位置,即行缓冲区的列指针,ll为行缓冲区长度
int cx; // 虚拟机代码指针, 取值范围[0, cxmax-1],代码生成模块总在 cx 所指位置生成新的代码
char line[81]; //行缓冲区,用于从文件读出一行,供词法分析获取单词时之用
char a[al + 1]; /* 词法分析器中用于临时存放正在分析的词, 多出的一个字节用于存放0 */
struct instruction code[cxmax]; /* 存放编译得到的类 PCODE虚拟机代码的数组 */
char word[norw][al]; /* 保留字 */
enum symbol wsym[norw]; /* 保留字对应的符号值 */
enum symbol ssym[256]; /* 单字符的符号值 */
char mnemonic[fctnum][5]; //类 PCODE 指令助记符表
bool declbegsys[symnum]; /* 表示声明开始的符号集合 */
bool statbegsys[symnum]; /* 表示语句开始的符号集合 */
bool facbegsys[symnum]; /* 表示因子开始的符号集合 */
bool ExpressionFollow[symnum]; //表达式后跟符号集
/* 符号表中的类型 */
enum object {
constant,
variable,
procedur,
array //lkz增加部分
};
/* 符号表结构 */
struct tablestruct
{
char name[al]; /* 名字 */
enum object kind; /* 类型:const, var, array or procedure */
int val; /* 数值,仅const使用 */
int level; /* 如果是变量名或过程名,存放层差、偏移地址和大小*/
int adr; /* 地址,仅const不使用 */
int size; /* 需要分配的数据区空间, 仅procedure,array使用 */
};
struct tablestruct table[txmax]; /* 符号表 */
FILE* fin;
FILE* fout;
char fname[al];
int err; //错误计数器
#pragma region 就是函数调用与错误处理放在一起
/* 当函数中会发生fatal error时,返回-1告知调用它的函数,最终退出程序 */
#define getsymdo if(-1 == getsym()) return -1
#define getchdo if(-1 == getch()) return -1
#define testdo(a, b, c) if(-1 == test(a, b, c)) return -1
#define gendo(a, b, c) if(-1 == gen(a, b, c)) return -1
#define expressiondo(a, b, c) if(-1 == expression(a, b, c)) return -1
#define factordo(a, b, c) if(-1 == factor(a, b, c)) return -1
#define termdo(a, b, c) if(-1 == term(a, b, c)) return -1
#define conditiondo(a, b, c) if(-1 == condition(a, b, c)) return -1
#define statementdo(a, b, c) if(-1 == statement(a, b, c)) return -1
#define constdeclarationdo(a, b, c) if(-1 == constdeclaration(a, b, c)) return -1
#define vardeclarationdo(a, b, c) if(-1 == vardeclaration(a, b, c)) return -1
#define errorDo(a) if(-1 == error(a)) return -1
#pragma endregion
#pragma region 各函数
int error(int n);
int getsym();
int getch();
void init();
int gen(enum fct x, int y, int z);
int test(bool* s1, bool* s2, int n);
int inset(int e, bool* s);
int addset(bool* sr, bool* s1, bool* s2, int n);
int subset(bool* sr, bool* s1, bool* s2, int n);
int mulset(bool* sr, bool* s1, bool* s2, int n);
int block(int lev, int tx, bool* fsys);
void interpret();
int factor(bool* fsys, int* ptx, int lev);
int term(bool* fsys, int* ptx, int lev);
int condition(bool* fsys, int* ptx, int lev);
int expression(bool* fsys, int* ptx, int lev);
int statement(bool* fsys, int* ptx, int lev);
void listcode(int cx0);
int vardeclaration(int* ptx, int lev, int* pdx);
int constdeclaration(int* ptx, int lev, int* pdx);
int position(char* idt, int tx);
void enter(enum object k, int* ptx, int lev, int* pdx);
int base(int l, int* s, int b);
void ListTable(int tx0, int tx);
#pragma endregion
//错误信息数组
const char* err_msg[] = {
"",//0
"'='写成了':='",//1
"'='后面要跟一个数字",//2
"标识符后面要跟一个‘=’",//3
"在const,var,procedure后面要有一个标识符",//4
"缺少','或者';'",//5
"过程名错误!",//6
"需要声明",//7
"声明后边是一个不正确的符号",//8
"少了'.',程序无法正常结束",//9
"少了';'",//10
"发现未声明的标识符!",//11
"非法赋值",//12
"少了':='",//13
"call之后缺少标识符!",//14
"call之后标识符不是过程!",//15
"少了then",//16
"缺少';'或者end",//17
"少了do",//18
"符号错误",//19
"条件语句中未发现操作符(“#,>”等)",//20
"不能把过程的标识符放在表达式里!",//21
"单引号后未跟单引号,词法分析出错!",//22
"符号后面不能跟着<因子>",//23
"符号不能作为<表达式>的开始!",//24
"数组声明有误",//25
"write里面不是表达式或字符串!",//26
"break未写在循环中!",//27
"for语句缺少step或until !",//28
"for 语句循环变量类型错误!",//29
"数字过大!",//30
"常量超过可定义的最大值!",//31
"超过允许的最大嵌套层数,层数太多啦!",//32
"格式错误,应是右括号')'",//33
"格式错误,应是左括号'('",//34
"read里不是标识符ID,或该标识符未声明",//35
};
/* 用于循环语句跳出的辅助表结构 */
struct JumpOut
{
int Addr; //生成的jmp虚拟机代码地址
int CycleNum; //外层循环数
};
struct JumpOut jp;//全局变量,用于循环语句跳出
pl0.cpp
#define _CRT_SECURE_NO_WARNINGS
/*
* PL/0 编译器
*
* 使用方法:
* 运行后输入PL/0源程序文件?
* 回答是否输出虚拟机代码
* 回答是否输出名字表
* fa.pcode输出虚拟机代码
* fa1.tmp输出源文件及其各行对应的首地址
* out.tmp输出运行结果
* fas.tmp输出名字表
*/
#include "pl0.h"
#include "string.h"
//运行前初始化,对保留字表 (word)、保留字表中每一个保留字对应的 symbol 类型 ( wsym )、
//部分符号对应的 symbol 类型表 ( ssym )、类 PCODE 指令助记符表 ( mnemonic )、
//声明开始集合 ( declbegsys )、表达式开始集合 ( statbegsys )、
//项开始符号集合 ( facbegsys ) 以及一些全局变量的初始化
void init()
{
jp.CycleNum = 0;
jp.Addr = 0;
int i;
// ASCII 范围(0–31 控制字符, 32–126 分配给了能在键盘上找到的字符
//数字 127 代表 DELETE 命令, 后 128 个是扩展 ASCII 打印字符) 因此共 256 个
/* 设置单字符符号 */
for (i = 0; i <= 255; i++)
{
ssym[i] = nul;
}
ssym['+'] = plus;
ssym['-'] = minus;
ssym['*'] = times;
ssym['/'] = slash;
ssym['('] = lparen;
ssym[')'] = rparen;
ssym['='] = eql;
ssym[','] = comma;
ssym['.'] = period;
ssym['#'] = neq;
ssym[';'] = semicolon;
ssym['['] = Lsquare;
ssym[']'] = Rsquare;
/* 设置保留字名字,按照字母顺序,便于折半查找 */
strcpy(&(word[0][0]), "begin");
strcpy(&(word[1][0]), "break");
strcpy(&(word[2][0]), "call");
strcpy(&(word[3][0]), "const");
strcpy(&(word[4][0]), "do");
strcpy(&(word[5][0]), "end");
strcpy(&(word[6][0]), "for");
strcpy(&(word[7][0]), "if");
strcpy(&(word[8][0]), "odd");
strcpy(&(word[9][0]), "procedure" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7177
7177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









