







引论
计算机语言分类
- 机器语言与汇编语言
更接近计算机硬件指令系统的工作 - 高级语言
更接近求解问题的表示方法 - 命令语言
控制系统的工作——以功能封装为特征
翻译程序解释程序编译程序区别
翻译程序是将某一种语言描述的程序(源程序)翻译成等价的另一种语言描述的程序描述的程序(目标程序)
解释程序是边解释边执行的,不产生目标程序,速度要慢。
编译程序则是将高级语言程序翻译成汇编/机器语言程序,计算机直接执行翻译后的程序,速度要快。
编译系统的总体结构
词法分析器-> 语法分析器->语义分析和中间代码生成器->代码优化->目标代码生成器
全过程均有表格管理和出错处理。
词法分析的功能是什么?
词法分析由词法分析器完成,它从左到右扫描源程序——发现一个字符串,则将该字符串转化成单词(token)串;同时查词法错误,进行标识符登记——符号表管理。期间需要删去空格字符和注解等
输入:字符串
输出:token(种别码,属性值)序列
语法分析的功能是什么?
实现组词成句,识别词组成的各类语法成分,指出语法错误,制导翻译。
输入:token序列
输出:语法成分
语义分析的功能是什么?
分析由语法分析器识别出的语法单位的语义
获取标识符的属性:类型、作用域等。
语义检查:运算的合法性、取值范围等。
子程序的静态绑定:代码的相对地址
变量的静态绑定:数据的相对地址
中间代码的特点?
简单规范、与机器无关、易于优化与转换
代码优化
对中间代码的优化处理:对代码进行等价变换以求提高效率——提高运行速度和节省存储空间(机器有关和机器无关,详见计算机体系结构)。
目标代码生成
将中间代码转换成目标机上的机器指令代码或汇编代码
表格管理是什么
管理各种符号表(常数、标号、变量、过程、结构……),查、填(登记、查找)源程序中出现的符号和编译程序生成的符号,为编译的各个阶段提供信息。
错误处理包含哪些内容
进行各种错误的检查、报告、纠正,以及相应的续编译处理(如:错误的定位与局部化)
词法:标识符命名是否符合规范等等
语法:语句结构、表达式结构是否符合
语义:类型是否匹配
简单介绍编译的前端和后端
**前端:**与源语言有关、与目标机无关的部分词法分析、语法分析、语义分析与中间代码生成、与机器无关的代码优化。
**后端:**与目标机有关的部分、与机器有关的代码优化、目标代码生成。
编译程序生成可以采用哪些技术
- 编译程序的自展技术
- 利用编译程序自动生成器
词法分析
单词符号有哪些分类
- 关键字
- 标识符
- 常数
- 运算符
- 界限符 , ; ( ) : =等
已经可以得知单词在机内表示的方式为一个二元式(单词种别码,单词自身值),那种别码和自身值确定规规则是什么样的?
种别码
关键字:一种一码
标识符:一种码
常数:一类型一码
界限符:一符一码
单词值
并不是所有的单词都有,关键字、界限符、运算符就没有自身值,常数和标识符的自身值为本身或者符号表入口地址。
词法分析的过程中,会碰到各种问题,有什么问题以及解决方法是什么?
- 词法分析的过程中会有双字符运算符,像是>=,<=,==等,如果仅仅扫描一个字符的时候扫描到>的时候并不能直接判断其为>运算符,需要结合后面一个字符来看,因此需要用到超前扫描下一个字符来判断,解决该问题。
- 预处理问题。扫描过程中,剔除源程序里面的无用符号、空格、换行、注释等。
- 源程序难免发生错误。首先需要进行一个定位,进行行列计数,再来可以采用恐慌模式,忽略或者替换插入字符继续进行分析等等。
编译过程中,会维持一张符号表,符号表在编译过程中的作用是什么?
它用于存储程序编译或运行过程中所使用的变量(标识符)和常量(数字常数、字符常数)等信息。
在词法分析阶段:该阶段主要建立符号表,将不重复的标识符,数字常数和字符常数的性质填入符号表中,并且将变量(常数)在符号表中的入口地址写到自身的token字中。
在语法分析阶段:主要使用符号表。在分析过程中,需要用到某个标识符(或常数)时,就从符号表的指定入口查找出改符号。
在语义分析及中间代码生成阶段:主要是查填符号表。在生成四元式时,通常不是使用变量的名字而是使用它们在符号表的入口地址。另外,在翻译说明语句时,要向符号表中填入变量的类型信息。
数据存储分配:将变量(或常数)所使用的数据区映像地址写入符号表中的地址(ADDR)栏。若数据区是动态数据,则在符号表中存储过程层号和位移量等信息,待运行时再计算具体地址。
代码优化阶段:使用符号表。一方面遇到变量时,要到符号表中查找它的具体信息,另一方面,在优化过程中,也有可能使用符号表。
目标代码生成阶段:查找符号表。为最终生成目标代码提供必要的信息。
符号表内容有什么
符号表中包括名字(NAME)、类型(TYPE)、种属(KIND)、数值(VAL)、作用域和地址(ADDR)等栏,还带有一个字符串表。
语法分析
自顶向下分析面临的问题有什么?
- 存在回溯
文法中每个非终结符的产生式右部称为该符号的候选式,如果有多个候选式左端第一个符号相同,则语法分析程序无法根据当前输入符号选择产生式,只能试探。可以通过提取左公因子改写文法来解决。 - 左递归问题
无法根据左递归文法进行自顶向下的分析。不过可以消除左递归。 - 二义性
可以通过重写文法来消除二义性,引入新的语法变量。 - CFG的使用限制
没有一种方法能够有效地分析所有上下文无关文法,存在无法处理的CFG,且每种方法都有适用范围。
消除左递归例题
- 直接左递归
E -> E+T | T
T -> T*F | F
F -> (E) | id
消除后
E -> T E’
E’ -> +T E’| ε
T -> F T’
T’ -> *F T’ | ε
F -> (E) | id - 间接左递归
S→Ac|c
A→Bb|b
B→Sa|a
将B的定义代入A的产生式
A -> Sab|ab|b
将A的定义代入S中
S -> Sabc | abc| bc | c
消除直接左递归:
S -> abcS’ | bcS’ | cS’
S’ -> abcS’|ε
删除多余的产生式A ->Sab|ab|b和B->Sa|a
结果为 S-> abcS’|bcS’|cS’,S’->abcS’|ε。
自顶向下的分析方法的基本思想和过程
基本思想:
寻找输入符号串的最左推导
试图根据当前输入单词判断使用哪个产生式
基本过程:
从根开始,按与最左推导相对应的顺序,构造输入符号串分析树。

候选式无回溯的条件
设A→α1|α2|…|αn是所有的A产生式
如果各个αi能推导出的首终结符各不相同,则可以构造无回溯的分析。自顶向下希望文法满足无回溯。
LL(1)分析法
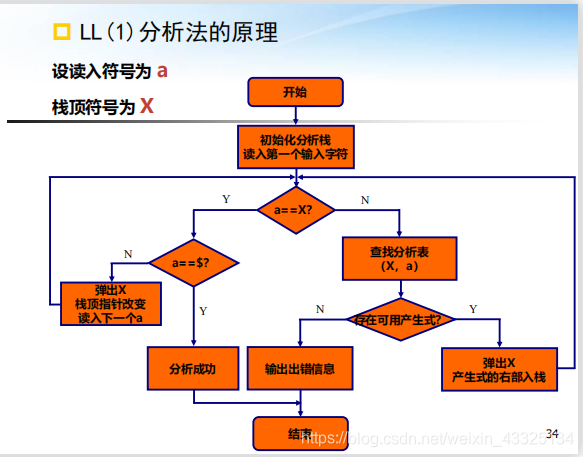
分析表构造
- 对于每一个产生式执行(2)和(3);
- 对于FIRST(α)中的每一终结符a,将A -> α填入M[A,a];
- 如果ε属于FIRST(α),则对FOLLOW(A)中每一个终结符b,将A-> α填入M[A,b],同时,若$在Follow(A)中,则将A->α,填入M[A,$];
- 将所有无定义的M[A,a]标上错误标志。
题目 构造给定文法的预测分析表
S -> AB
A -> Ba | ε
B -> Db | D
D -> d | ε
求出first和follow
first(D) = {d,ε}
first(B) = {b,d,ε}
first(A) = {a,b,d,ε}
first(S) = {a,b,d,ε}
follow(S) = {$}
follow(B) = {a,$}
follow(D) = {a,b,$}
follow(A) = {d,b,$}
| a | b | d | $ | |
|---|---|---|---|---|
| S | S->AB | S->AB | S->AB | S->AB |
| A | A->Ba | A->Ba/A->ε | A->Ba/A->ε | A->ε |
| B | B->D | B->Db | B->Db/B->D | B->D |
| D | D->ε | D->ε | D->d | D->ε |
由此可见,这个表格是用冲突的,这个文法其实并不是LL(1)文法。
考题-文法计算题
去年文法计算题
判断是否为LL(1)文法,分三步走:
- 有左递归不是LL(1)文法(无法对左递归的文法进行自顶向下的分析)
- 若A -> α 1 ∣ . . . ∣ α i ∣ . . . ∣ α n \alpha_1|...|\alpha_i|...|\alpha_n α1∣...∣αi∣...∣αn,则First( α i \alpha_i αi) ∩First( α j \alpha_j αj)=∅ ( i!=j )
- 若 α i \alpha_i αi-*->ε(i只能有一个),则对First( α j \alpha_j αj) ∩Follow(A)=∅(i!=j)
该文法为LL(1)文法。
- 首先,文法无左递归
- 求First集和Follow集合
First(S) = {long int}, First(A) = {long int}, First(B) = {id}, First(C ) = {, ε}
Follow(S) = {$}, Follow(A) = {id}, Follow(B)={$}, Follow(C ) = {$}
产生式左部为S: ε不包含于First(S),且产生式只有一个,无二义性。
产生式左部为A: ε不包含于First(A), First(int)∩First(long) = ∅,无二义性。
产生式左部为B: ε不包含于First(B), 且产生式只有一个无二义性。
产生式左部为C: ε包含于First(C ),但First(,idC) ∩ Follow(C ) = ∅,并且First(,idC )∩First(ε )=∅。
所以该文法为LL(1)文法。
LL分析表如下:
| int | long | id | , | $ | |
|---|---|---|---|---|---|
| S | ->AB | ->AB | 不应为id | 不应为, | 无效句子 |
| A | ->int | ->long | 不应为id | 不应为, | 无效句子 |
| B | 不应为int | 不应为long | ->idC | 不应为, | 无效句子 |
| C | 不应为int | 不应为long | 不应为id | ->,idC | ->ε |
如果再加一个让分析 int a,b 分析过程中中分析栈中元素变化如下。
首先栈中元素为:$ S next:int,按照分析表弹出S移入AB
栈中元素为:$ B A next:int,按照分析表弹出A移入int
栈中元素为:$ B int next:int,此时栈顶元素 = int,弹栈移入下一个符号.
栈中元素为:$ B next:id,按照分析表弹出B,移入idC
栈中元素为:$ C id next:id,栈顶元素 = id,弹栈移入下一个符号.
栈中元素为:$ C next:,,按照分析表弹出C,移入,idC
栈中元素为:$ C id , next:,,栈顶元素=,,弹栈移入下一个符号
栈中元素为:$ C id next:id,栈顶元素=id,弹栈移入下一个符号
栈中元素为:$ C next:$,按照分析表弹出C,移入ε,相当于没移入。
栈中元素为:$ next:$,栈顶元素=$,分析成功结束。
所以推导过程如下
S -> AB -> int B -> int id C -> int id , id C -> int id,id
介绍自底向上的语法分析技术
从输入串出发,反复利用产生式进行归约,如果最后能得到文法的开始符号,则输入串是句子,否则输入串有语法错误。核心是寻找句柄。
最左推导和最右推导
最左推导:每次推导都施加在句型的最左边的语法变量上。
最右推导:每次推导都施加在句型的最右边的语法变量上。
介绍一下句柄
最右句型(规范规约)中某个产生式体匹配的子串,它的归约代表了该最右句型的最右推导的最后一步;正式定义:如果S=>*αAw =>*αβw;那么紧跟α之后的A→β是最右句型αβw的一个句柄;
在一个最右句型中,句柄右边只有终结符号
如果文法是无二义性的,那么每个句型都有且只有一个句柄。
移入-规约分析法确定句柄的方法
- 优先法
- 状态法
LR
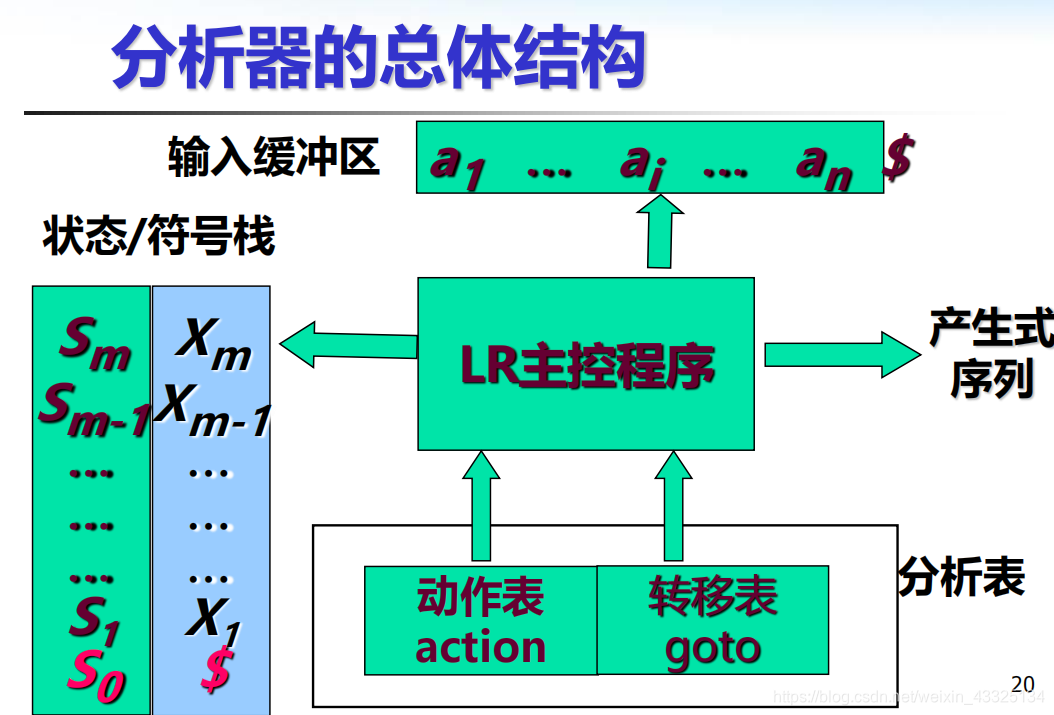
LR语法分析器的格局
LR语法分析器的格局包含栈中内容和余下的输入
项目集 I 的相容及LR(0)判定
如果 I 中至少含两个归约项目,则称 I 有归约—归约冲突
如果 I 中既含归约项目,又含移入项目,则称 I 有移入—归约冲突
若既没有归约-归约冲突也没有移入规约冲突,则称它为相容的,为LR(0)文法。
SLR的不足
SLR只孤立地考察输入符号是否属于归约项目A→α.相关联的集合FOLLOW(A),而没有考察符号串α所在规范句型的“上下文”。
考题-文法计算题
第四个文法计算题
参考博客传送门


该题目程序gitee地址:https://gitee.com/loxs/compiler/tree/master/compileEXE1
语法制导翻译
语法制导
上下文无关文法和属性的结合
属性与文法符号相关联,动作和产生式相关联。
根据需要将文法符号和某些属性相关联,并通过语义规则来描述如何计算属性的值。
语法制导翻译
在产生式体中加入语义动作,并在合适的实际执行这些动作。
继承属性和综合属性
综合属性:分析树节点N上的非终结符号A的属性值由N的产生式所关联的语义规则来定义。这个产生式的头一定是A。
必然通过N的子节点或者N本省来定义。
继承属性:分析树节点N属性值由N的父节点所关联的语义规则来定义。这个产生式的体中必定包含B。
依赖于N的父节点,N本身,N的兄弟节点的属性值。
S属性的SDD
每个属性都是综合属性
都是根据子构造的属性来计算整个构造的属性
在依赖图中总是以子节点的属性值来计算父节点的属性值。可以和自顶向下、自底向上的语法分析过程一起计算。
自底向上:在构造分析树的子节点同时计算相关的属性。
自顶向下:在递归子程序法中,在过程A()的最后计算A的属性。
L属性的SDD
每个属性要么是综合属性,要么是继承属性且产生式A -> X1X2…Xn中计算Xi.a的规则只能使用
A的继承属性
Xi左边的文法符号Xj的继承属性或综合属性
Xn自身的继承属性和综合属性,且这些属性依赖关系不形成环
具有受控副作用的语义规则
有副作用原因:属性文法没有副作用,但是会增加描述的复杂度。
比如语法分析的时如果没有副作用,符号表就必须作为属性传递。可以把符号表作为全局变量,然后通过副作用函数来添加新标识符。
受控的副作用:一般属性值计算(基于属性值或常量进行的)之外的功能,不会对属性求值造成约束,即可以按照任何拓扑结构求值,不会影响最终的结果。添加了部分简单约束。
语法制导的翻译方案
是在产生式体中嵌入程序片段的上下文无关文法
后缀翻译方案
文法可以自底向上分析且SDD是S属性的。
可以构造SDT,且所有动作都放在产生式的最后;分析过程中按照这个产生式规约时执行这个动作。计算得到的属性值都放在栈中。
所有动作都在产生式最右端的SDT称为后缀翻译方案。
产生式内部带有语义动作的SDT
一个动作左部的所有符号(所有符号)处理完成后,就立即执行这个动作。
B -> X{a}Y
自底向上分析时,a在X出现在栈顶时执行。
自顶向下分析时,在试图展开Y或者在输入中检测到Y时执行。
后缀SDT以及实现L属性的SDT可以在分析时完成。
L属性的自底向上实现
首先构造出L属性SDD的SDT,即在非中介符号前计算其继承属性
若产生式A->α {a} β,则对每个语义动作a,引入标记非终结符号M,且M->ε。
定义M->ε{a’},其中a’的构造方法如下:
将a中需要A或者其他属性作为M的继承属性进行拷贝。
按照a中的规则计算各个属性,作为M的综合属性。
例子:A->{B.i = f(A.i);}BC
引入标记非终结符号M后
A->MBC
M->ε {M.i = A.i;M.s = f(M.i);}
A.i为A的继承属性,a的继承属性分析栈BC下方。
考题-文法翻译题
三地址代码(偷个懒按照从1开始做了)
1:if x<3 goto 3
2:goto 11
3:if y<2 goto 5
4:goto 15
5:if c<1 goto 7
6:goto 15
7:t1=x-1
8:y=t1
9:goto 3
10:goto 15
11:if x>1 goto 13
12:goto 15
13:t2=x-2
14:x=t2
15:
(2) 11
(3) 4 6 10 12
该题目程序gitee地址:https://gitee.com/loxs/compiler/tree/master/compileEXE2
运行时刻环境
概述
运行时刻环境
确定访问变量时使用的机制
过程之间的连接
参数传递
和操作系统、输入输出设备相关的其他接口
编译程序除了要关心目标代码生成的问题之外,还必须考虑程序运行时使用的数据区域管理的问题。
为什么要使用数据区
程序运行时各种数据都必须放在内存里,便于访问和使用。
另外涉及数据区的管理:
内存永远不能满足要求
必须找到存储的数据
按照程序单位分配和管理数据区
数据区存储内容
变量和常数:用户自己定义
临时单元:源程序没有,编译程序在生成中间代码时建立和使用
形式单元:存放过程或函数间传递的参数
返回地址:返回主调程序的入口
保护区:保护主调程序寄存器内容,恢复现场
数据访问控制信息
存储管理:栈分配、堆管理、垃圾回收
存储
目标程序代码放在代码区
静态区、堆区、栈区分别放不同类型生命期的数据值,即数据区。
静态和动态存储分配
静态分配
编译器在编译时刻就可以做出存储分配决定,不需要运行时刻的情景。
要求:
不存在可变长的数组,可变长的字符串、指针。
不存在函数的递归与嵌套。
全局变量
会在符号表中按照对象属性顺序分配数据区,从而建立一个数据映像,运行时按照此映像分配实际的内存数据区。
动态分配
栈式存储
在过程的调用/返回同步进行分配和回收,值的生命期和过程生命期相同。
有可变数组,有过程和函数的递归嵌套。
活动树
过程调用在时间上总是嵌套的:后调用的先返回
因此可以用栈式分配来处理过程活动所需的内存空间。
程序运行的所有过程可以用 一个树来表示。
- 每个节点对应一个过程活动
- 根节点对应main函数的活动
- 过程p的某次过程活动对应的子节点对于此次活动调用的各个过程活动。
过程调用和返回由控制栈进行管理
每个活跃的活动对于栈中的一个活动记录
活动记录按照活动的开始时间,从栈底到栈顶排列。
运行栈:把控制栈中的信息拓广到包括过程活动所需的所有局部信息
栈中的变长数据:如果数据对象的生命期局限于过程活动的生命期,就可以分配在运行时刻栈中。
top指向实际栈顶
top_sp用于寻找顶层记录的定长字段
访问链
被用于访问非局部的数据
如果过程p在声明时嵌套在过程q的声明中,那么p的活动记录中访问链指向最上层的q的活动记录
从栈顶活动记录开始,访问链形成了一个链路嵌套深度逐一递减。
如果深度为np的过程p访问变量x,而变量x在深度为nq的过程中声明,那么
从当前活动记录出发,沿访问链前进np-nq次找到的活动记录中的x就是要找的变量位置。
x相对于活动记录的偏移量和np-nq在编译时刻已知
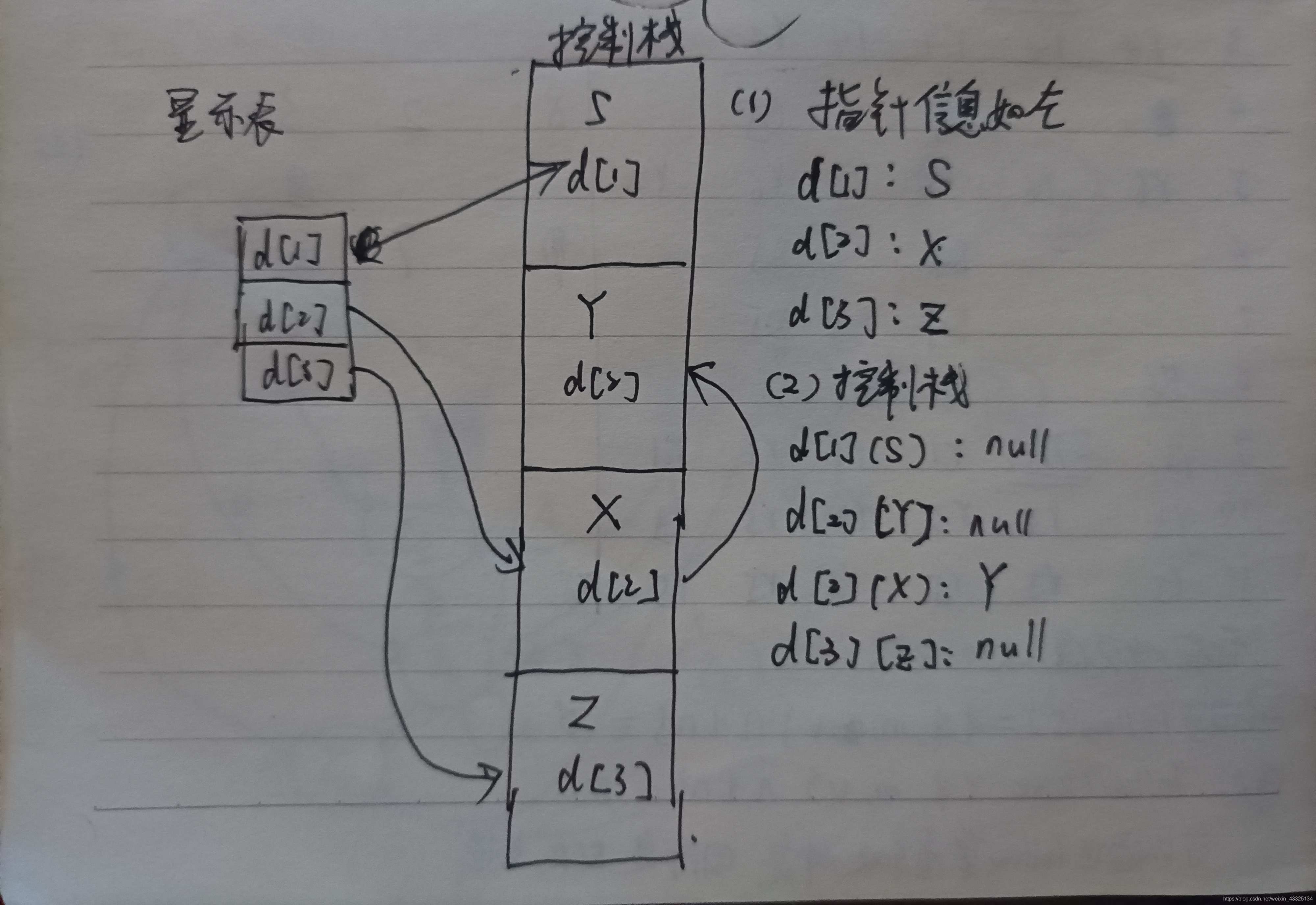
显示表
背景:用访问链访问数据时,如果嵌套深度大,则访问效率差。
使用数组d为每个嵌套深度保留一个指针,指针d[i]指向最高的深度为i的活动记录。
如果程序p中访问深度为i的过程q的变量x,那么d[i]直接指向相应的q的活动记录。
维护:
- 调用过程p时,在p的活动记录中保留d[np]的值,并将d[np]设置为当前活动记录。
- 从p返回时,恢复d[np]的值
考题
堆存储
在编译是无法确定数据区的大小,在过程的入口处也确定不了数据区的大小,因此无法使用静态或栈式分配方法。
条件:有static类型,指针类型和表单等变量。
存储分配器
为每个内存请求分配一段连续的适当大小的堆空间。首先从空闲的堆空间分配;如果不行则从操作系统中获取内存、增加堆空间。
回收:把回收的空间返回空闲空间缓冲池,以满足其他的分配。
评价特性:空间效率(需要的堆空间最小,减小碎片)程序效率(充分使用内存系统的层次,提高效率)、低开销(使分配/收回内存的操作尽可能高效)
堆空间的分配及管理
固定长分块法:将堆空间分成带下相同的块,使用链表连接各个单元;适用于类型单一或长度一致的数据类型。
可变长分块法:将堆空间分成长度不同的块。
外部碎片和内部碎片问题
堆空间不可以随便释放,释放方法:参照计数法、无用单元收集。
代码生成
主要问题
正确性
易于实现、测试和维护
输入IR的选择
四元式、三元式、字节代码、堆栈机代码、后缀表示、抽象语法树、DAG图
输出
RISC、CISC
可重定向代码、汇编语言
目标机模型
使用三地址机器的模型
指令
- 加载 2. 保存 3. 计算 4. 无条件跳转 5. 条件跳转
寻址模式
和汇编中的差不多
目标代码中的地址
如何将IR中的名字转换成目标代码中的地址?
不同区域中的名字采用不同寻址方式。
活动记录静态分配
每个过程静态分配一个数据区域,开始位置用staticArea表示
- call callee的实现
- callee 中的return
活动记录栈式分配
寄存器SP指向栈顶
第一个过程(main)初始化栈区
过程调用指令序列
ADD SP,SP,#caller.recordSize //增加栈指针
ST 0(SP),#here + 16// 保护返回地址
BR callee.codeArea// 转移到被调用者
返回指令序列
BR *0(SP)// 被调用者执行,返回调用者
SUP SP,SP,#caller.recordSize//调用者减低栈指针
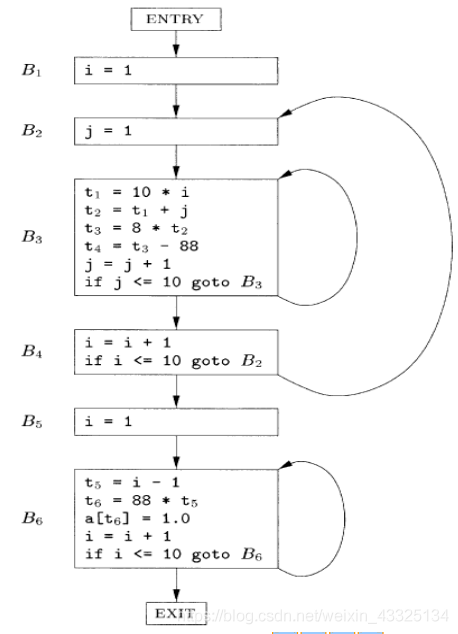
基本块和流图
中间代码的流图表示法
中间代码划分成基本块,控制流只能第一个指令进入,除了基本块最后一个ie指令,控制流不会跳转停机
流图的节点是基本块。流图的边指明了哪些基本块可以跟在一个基本块之后运行。
流图可以作为优化的基础
它指出了基本块之间的控制流
可以根据流图了解到一个值是否会被使用等信息
划分基本块
确定首指令(基本块的第一个指令)满足下列三条之一即可:
中间代码的第一个三地址指令
任意一个条件或无条件转移指令的目标指令
紧跟在一个条件/无条件转移指令之后的指令
确定基本块
每个首指令对应于一个基本块:从首指令(包含)开始到下一个首指令(不含)
一个简单的代码生成器
重要子函数:getReg(I)
为三地址指令I选择寄存器;
根据寄存器描述符和地址描述符、以及数据流信息来分配最佳的寄存器;
得到的机器指令的质量依赖于getReg函数选取寄存器的算法
代码生成时必须更新寄存器描述符和地址描述符。
彩蛋
试验的翻译方案:选用不同的M可能会避免一些潜在的冲突,但是,也有一些另外的作用,if和if else得选一样的M。
全局变量
static int instr=0; // 指令序号从0开始
int offset; // 偏移量 - 声明语句对于
queue<Gen> gens;//指令缓冲队列 便于回填
声明语句
P -> M1 D S{}
D -> L id ; N1 D{}
L -> int
{
L.type=1;
L.width=4;
}
L -> float
{
L.type=2;
L.width=8;
}
M1 -> ε
{
offset = 0;
}
N1 -> ε
{
table.put(id.lexeme,L.Type,L.width);
offset = offset+L.width;
}
赋值和运算语句
/*
mergeType 类型转换&&类型检查 funType(int,float)=float 这种的
checkType 检查类型是否匹配
调用一次gen,instr++,并且每个指令都有自己的instr编号便于回填
*/
S -> id = E ;
{
checkType(id.Type,E.type);
gens.push(gen(table[id.lexeme]=E.addr));
}
E -> E1 + T
{
E.addr = newTemp();
E.type=mergeType(E1.type,T.type);
gens.push(gen(E.addr=E1.addr+T.addr));
}
E -> E1 - T
{
E.addr = newTemp();
E.type=mergeType(E1.type,T.type);
gens.push(gen(E.addr=E1.addr-T.addr));
}
E -> T
{
E.addr=T.addr;
E.type=T.type;
}
T -> F
{
T.addr=F.addr;
T.type=F.type;
}
T -> T1 * F
{
T.addr = newTemp();
T.type=mergeType(T1.type,F.type);
gens.push(gen(T.addr=T1.addr*F.addr));
}
T -> T1 / F
{
T.addr = newTemp();
T.type=mergeType(T1.type,F.type);
gens.push(gen(T.addr=T1.addr/F.addr));
}
F -> ( E )
{
F.addr=E.addr;
F.type=E.type;
}
F -> id
{
F.addr=table[id.lexeme];
F.type=id.type;
}
F -> digits
{
F.addr=table[digits.lexeme];
F.type=digits.type;
}
布尔表达式
C -> E1 > E2
{
C.trueList=makelist(instr);
C.falseList=makelist(instr+1);
gens.push(gen(if E1>E2 goto _));
gens.push(gen(goto _));
}
C -> E1 < E2
{
C.trueList=makelist(instr);
C.falseList=makelist(instr+1);
gens.push(gen(if E1<E2 goto _));
gens.push(gen(goto _));
}
C -> E1 == E2
{
C.trueList=makelist(instr);
C.falseList=makelist(instr+1);
gens.push(gen(if E1==E2 goto _));
gens.push(gen(goto _));
}
C -> C1 || M7 C2
{
backpatch(C.falselist,M1.instr);
C.truelist=merge(C1.truelist,C2.truelist);
C.falselist=C2.falselist;
}
C -> C1 && M7 C2
{
backpatch(C.truelist,M1.instr);
C.truelist=C2.truelist;
C.falselist=merge(C1.falselist,C2.falselist);
}
C -> ( C1 )
{
C.falselist=C.falselist;
C.truelist=C.truelist;
}
C -> true
{
C.truelist=makelist(instr);
gens.push(gen(goto _));
}
C -> false
{
C.falselist=makelist(instr);
gens.push(gen(goto _));
}
C -> ! C1
{
C.falselist=C.truelist;
C.truelist=C.falselist;
}
M7 -> ε
{
M1.instr=instr;
}
控制语句
S -> if ( C ) M2 S1
{
backpatch(C.truelist,M1.instr);
S.nextlist=merge(C.falselist,S1.nextlist);'
}
S -> if ( C ) M2 S1 N2 else M4 S2
{
backpatch(C.truelist,M1.instr);
backpatch(C.falselist,M2.instr);
S.nextlist=merge(S2.nextlist,merge(N2.nextlist,S1.nextlist));
}
S -> while M5 ( C ) M6 S1
{
backpatch(S1.nextlist,M1.instr);
backpatch(C.truelist,M2.instr);
S.nextlist=C.falselist;gens.push(gen(goto M1.instr));
}
S -> S1 M7 S2
{
S.nextlist=S2.nextlist;
backpatch(S1.nextlist,M1.instr);
}
M1_7 -> ε
{
M1.instr=instr;
}
N2 -> ε
{
N2.nextlist=makelist(instr);
gens.push(gen(goto _));
}
参考博客:https://blog.csdn.net/qq_39384184/article/details/86037568















 171
171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









