









508. 出现次数最多的子树元素和
给你一个二叉树的根结点 root ,请返回出现次数最多的子树元素和。如果有多个元素出现的次数相同,返回所有出现次数最多的子树元素和(不限顺序)。
一个结点的 「子树元素和」 定义为以该结点为根的二叉树上所有结点的元素之和(包括结点本身)。
示例 1:

输入: root = [5,2,-3]
输出: [2,-3,4]
示例 2:
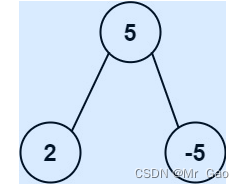
输入: root = [5,2,-5]
输出: [2]
提示:
节点数在 [1, 104] 范围内
-105 <= Node.val <= 105
通过次数39,710
提交次数52,660
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int max;
#define sized 100
void dfs1(struct TreeNode* root,int *size){
if(root){
(*size)++;
dfs1(root->left,size);
dfs1(root->right,size);
}
}
int dfs2(struct TreeNode* root,int *size,int *arr){
if(root){
int l=dfs2(root->left,size ,arr );
int r=dfs2(root->right,size ,arr );
arr[*size]=l+r+root->val;
(*size)++;
return l+r+root->val;
}
else{
return 0;
}
}
void quick(int *a,int low,int high){
if(low<high){
int l=low,h=high,p=a[low];
while(low<high){
while(low<high&&a[high]>=p){
high--;
}
a[low]=a[high];
while(low<high&&a[low]<=p){
low++;
}
a[high]=a[low];
}
a[low]=p;
quick(a,l,low-1);
quick(a,low+1,h);
}
}
struct hash{
int val;
int count;
struct hash *next;
};
bool find_hash( struct hash *h,int val){
struct hash *p=h->next;
while(p){
if(p->val==val){
p->count++;
if(p->count>max){
max=p->count;
}
return true;
}
p=p->next;
}
return false;
}
int* findFrequentTreeSum(struct TreeNode* root, int* returnSize){
int *size=(int *)malloc(sizeof(int));
*size=0;
dfs1(root,size);
*returnSize=*size;
int *arr=(int *)malloc(sizeof(int)*(*size));
*size=0;
int re=dfs2(root,size,arr);
int i;
struct hash *h=(struct hash *)malloc(sizeof(struct hash )*sized);
for(i=0;i<sized;i++){
(h+i)->next=NULL;
}
max=1;
for(i=0;i<*returnSize;i++){
if(find_hash(h+abs(arr[i])%sized,arr[i])){
continue;
}
else{
struct hash *p=( struct hash *)malloc(sizeof( struct hash ));
p->val=arr[i];
p->count=1;
p->next=(h+abs(arr[i])%sized)->next;
(h+abs(arr[i])%sized)->next=p;
}
}
int res=0;
for(i=0;i<sized;i++){
struct hash *p=(h+i)->next;
while(p){
if(p->count==max){
arr[res++]=p->val;
}
p=p->next;
}
}
*returnSize=res;
return arr;
}















 5205
5205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









