








python cookbook内容提炼
博主打算做一篇python cookbook内容提炼的文章,这篇博客会很实用。
第一章:数据结构和算法
第一章的内容很实用,博主做了一些内容上的提炼,把一些最重要的知识点写在了下面。
下面内容中,非加黑的内容实在开发中不常用的,其他的都是比较重要的内容,感兴趣,可以掌握一下。
1.1解压序列赋值给多个变量
1.2 解压可迭代对象赋值给多个变量
1.3 保留最后N个元素
1.4 查找最大或最小的N个元素
1.5 实现一个优先级队列
1.6 字典中的键映射多个值
1.7 字典排序
1.8 字典的运算
1.9 查找两字典的相同点
1.10 删除序列相同元素并保持顺序
1.12 序列中出现次数最多的元素
1.13 通过某个关键字排序一个字典列表
1.14 排序不支持原生比较的对象
1.15 通过某个字段将记录分组
1.16 过滤序列元素
1.17 从字典中提取子集
1.18 转换并同时计算数据
1.19 合并多个字典或映射
1.1解压序列赋值给多个变量
这是python一种赋值的快捷方式,来看一下示例:
data=['job',12,[12,360]]
a,b,c=data
print('a:',a)
print("b:",b)
print("c:",c)
运行结果:

1.2 解压可迭代对象赋值给多个变量
对于这个知识点,大家看代码自然就懂了,没有很难的地方,感兴趣还可以去看看内部源码。
示例代码:
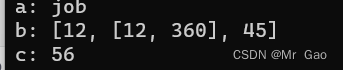
data=['job',12,[12,360],45,56]
a,*b,c=data
print('a:',a)
print("b:",b)
print("c:",c)
运行结果:
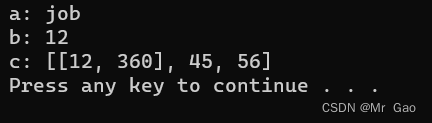
data=['job',12,[12,360],45,56]
a,b,*c=data
print('a:',a)
print("b:",b)
print("c:",c)
运行结果:
1.3 保留最后N个元素
保留最后n个元素,其实这个意思是,如果有m个对象符合条件,那么保留最后n个元素,舍去前面m-n个元素。
文中是通过collections库中的deque类实现的,其实就是用到了队列的性质,先进先出。
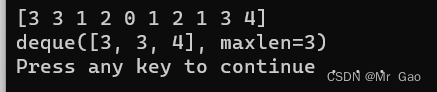
import numpy as np
from collections import deque
arrays=np.random.randint(0,5,size=10)
result=deque(maxlen=3)
for i in arrays:
if i>2:
result.append(i)
print(arrays)
print(result)
运行结果:
怎么说呢,这其实是一种巧用队列的方法。
1.4 查找最大或最小的N个元素
这可以通过heapq模块,其实也使用了数据结构最大堆和最小堆的性质,本质上就是用最大堆和最小堆去实现的。
heapq模块有两个函数: nlargest() 和 nsmallest() 可以完美解决这个问题。
先看第一段代码:
import heapq
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
print(heapq.nlargest(3, nums)) # Prints [42, 37, 23]
print(heapq.nsmallest(3, nums)) # Prints [-4, 1, 2]
运行结果:
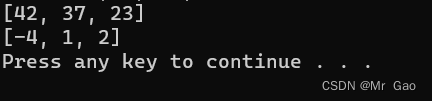
heapq.nlargest(3, nums),就是说从nums找出最大的三个元素。
但是你肯定会想,这个不好用啊,实际开发中,很多时候用的都是对象集合,二级列表,很少纯数字让你去处理,不用担心,heapq对各种数据类型都考虑到了。
来看下面一个例子:
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive =heapq.nlargest(3, portfolio, key=lambda s: s['price'])
print(cheap)
print(expensive)
可以通过lambda 进行key(排序所用)值选择。

1.5 实现一个优先级队列
看一下构建优先级队列类的代码:
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index +=1
def pop(self):
return heapq.heappop(self._queue)[-1]
data=[['job',6],['alice',5],['tom',8]]
p=PriorityQueue()
for d in data:
p.push(d[0],d[1])
print(p.pop())
print(p.pop())
print(p.pop())

博主觉得,这个构造方法,一般般,不算特别好,但是大家如果没什么经验,可以选择这种优先级队列构造方式。
1.6 字典中的键映射多个值
一个字典就是一个键对应一个单值的映射。如果你想要一个键映射多个值,那么你就需要
将这多个值放到另外的容器中, 比如列表或者集合里面。比如,你可以像下面这样构造
这样的字典:
d= {
'a' : [1, 2, 3],
'b' : [4, 5]
}
e= {
'a' : {1, 2, 3},
'b' : {4, 5}
}
在这本书中使用了 collections 模块中的 defaultdict 来构造这样的字典。
来看一下代码:
from collections import defaultdict
d=defaultdict(list)
d['a'].append(1)
d['a'].append(2)
d['b'].append(4)
d['b'].append(5)
print(d)
d=defaultdict(set)
d['a'].add(1)
d['a'].add(2)
d['b'].add(4)
d['b'].add(5)
print(d)
注意,defaultdict(set),使用的什么容器,就要采用那个容器的方法。

这个知识点还是很实用的,可以帮助我们解决很多问题。
也哭一自己实现,就是像下面这样:
d= {}
for key, value in pairs:
if keynotin d:
d[key] = []
d[key].append(value)
1.7 字典排序
这个问题并不是说,我们对字典排序,因为这个方法很多,而是说,我们在构建的同时进行排序。
来看一下代码:
from collections import OrderedDict
def ordered_dict():
d =OrderedDict()
d['foo'] = 1
d['bar'] = 2
d['spam'] = 3
d['grok'] = 4
# Outputs "foo 1", "bar 2", "spam 3", "grok 4"
for key in d:
print(key, d[key])
return d
d=ordered_dict()
print(d)

OrderedDict 内部维护着一个根据键插入顺序排序的双向链表。每次当一个新的元素插入
进来的时候, 它会被放到链表的尾部。对于一个已经存在的键的重复赋值不会改变键的
顺序。
需要注意的是,一个 OrderedDict 的大小是一个普通字典的两倍,因为它内部维护着另外
一个链表。 所以如果你要构建一个需要大量 OrderedDict 实例的数据结构的时候(比如读
取100,000行CSV数据到一个 OrderedDict 列表中去), 那么你就得仔细权衡一下是否使用
OrderedDict 带来的好处要大过额外内存消耗的影响。
这个方法不太好,有点拉,对于简单的数据对象可以使用。
1.8 字典的运算
怎样在数据字典中执行一些计算操作(比如求最小值、最大值、排序等等)?
这里,我们只说排序,书中求最大值和最小值没什么亮点:
prices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
prices_sorted = sorted(zip(prices.values(), prices.keys()))
print(prices_sorted)
运行结果:

1.9 查找两字典的相同点
怎样在两个字典中寻寻找相同点(比如相同的键、相同的值等等)?
这个在书中技巧挺不错的,看一下代码:
a = {
'x' : 1,
'y' : 2,
'z' : 3
}
b = {
'w' : 10,
'x' : 11,
'y' : 2
}
# Find keys in common
print(a.keys() &b.keys()) # { 'x', 'y' }
#Findkeysin athat are not in b
print(a.keys() -b.keys()) # { 'z' }
# Find (key,value) pairs in common
print(a.items() &b.items()) # { ('y', 2) }
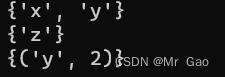
通过集合的运算,巧妙解决了这些问题。
1.10 删除序列相同元素并保持顺序
怎样在一个序列上面保持元素顺序的同时消除重复的值?
这块内容实际开发中很常用,可以好好学习一下。
来看一下代码:
def dedupe(items):
seen =set()
for item in items:
if item not in seen:
yield item
seen.add(item)
return seen
a = [1, 5, 2, 1, 9, 1, 5, 10]
print(list(dedupe(a)))

其实也是一种巧妙利用集合的方法。当然这个方法是有限制的,所以,诸位其实可以构建自己的类,因为当元素比较复杂的时候,这个方法就行不通了。
1.11 命名切片
这一节就不细讲了,大家可以去了解一下slice这个方法,这个部分内容对我们平时编程帮助不大。
放一段代码大家可以体会:
items = [0, 1, 2, 3, 4, 5, 6]
a = slice(2, 4)
print(items[a])

1.12 序列中出现次数最多的元素
怎样找出一个序列中出现次数最多的元素呢?
collections.Counter 类就是专门为这类问题而设计的, 它甚至有一个有用的most_common() 方法直接给了你答案。
来看一下代码:
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around', 'the',
'eyes', "don't", 'look', 'around', 'the','eyes', 'look', 'into',
'my', 'eyes', "you're", 'under'
]
from collections import Counter
word_counts = Counter(words)
# 出现频率最高的3个单词
top_three = word_counts.most_common(3)

这块内容很实用,我记得以前开发我也常用这个方法。
1.13 通过某个关键字排序一个字典列表
这个内容就是,我们常说的嵌套数据结构,内部元素排序。
来看一下代码:
rows= [
{'fname': 'Brian','lname': 'Jones', 'uid': 1003},
{'fname': 'David','lname': 'Beazley', 'uid': 1002},
{'fname': 'John', 'lname': 'Cleese', 'uid': 1001},
{'fname': 'Big', 'lname': 'Jones', 'uid':1004}
]
from operator import itemgetter
rows_by_fname = sorted(rows, key=itemgetter('fname'))
rows_by_uid = sorted(rows,key=itemgetter('uid'))
print(rows_by_fname)
print(rows_by_uid)
rows_by_lfname = sorted(rows, key=itemgetter('lname','fname'))
print(rows_by_lfname)
结果:

这个其实,网上内容很多,但是itemgetter方法支持多值排序还是很棒的。
#1.14 排序不支持原生比较的对象
看一下代码:
这个代码跟书上的不一样,原则上,我是想让大家学习下面的,好记住。
class User:
def __init__(self,user_id):
self.user_id =user_id
def __repr__(self):
return 'User({})'.format(self.user_id)
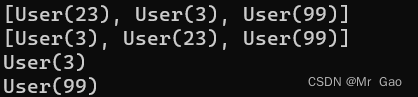
users = [User(23),User(3), User(99)]
print(users)
print(sorted(users,key=lambda u: u.user_id))
print(min(users, key=lambda u: u.user_id))
print(max(users, key=lambda u: u.user_id))
另外如果是多键值排序,那么要用另一种方法:
from operator import attrgetter
by_name = sorted(users,key=attrgetter('last_name', 'first_name')
1.15 通过某个字段将记录分组
你有一个字典或者实例的序列,然后你想根据某个特定的字段比如 date 来分组迭代访问
主要通过itertools 的groupby方法实现,这个很实用,可以学习学习的。
print("*"*50)
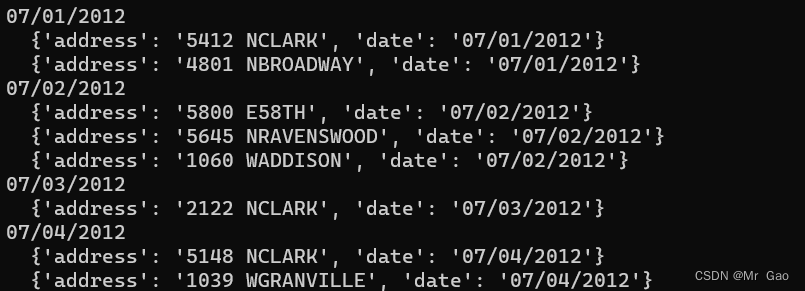
rows= [
{'address': '5412 NCLARK', 'date': '07/01/2012'},
{'address': '5148 NCLARK', 'date': '07/04/2012'},
{'address': '5800 E58TH', 'date': '07/02/2012'},
{'address': '2122 NCLARK', 'date': '07/03/2012'},
{'address': '5645 NRAVENSWOOD', 'date':'07/02/2012'},
{'address': '1060 WADDISON', 'date': '07/02/2012'},
{'address': '4801 NBROADWAY', 'date': '07/01/2012'},
{'address': '1039 WGRANVILLE', 'date':'07/04/2012'},
]
from operator import itemgetter
from itertools import groupby
# Sort by the desired field first
rows.sort(key=itemgetter('date'))
# Iterate in groups
for date, items in groupby(rows, key=itemgetter('date')):
print(date)
for i in items:
print(' ', i)
1.16 过滤序列元素
你有一个数据序列,想利用一些规则从中提取出需要的值或者是缩短序列
代码:
mylist = [1, 4, -5,10, -7, 2, 3, -1]
mylist_filter=[n for n in mylist if n > 0]
print(mylist_filter)
values = ['1', '2', '-3', '-', '4', 'N/A', '5']
def is_int(val):
try:
x = int(val)
return True
except ValueError:
return False
ivals = list(filter(is_int, values))
print(ivals)
上面展示了两种方法,第二种,是对于过滤条件比较复杂的一种处理方式。

1.17 从字典中提取子集
你想构造一个字典,它是另外一个字典的子集。
代码:
prices = {
'ACME': 45.23,
'AAPL': 612.78,
'IBM': 205.55,
'HPQ': 37.20,
'FB': 10.75
}
# Make a dictionary ofallprices over 200
p1 ={key: value for key, value in prices.items() if value > 200}
# Make a dictionary oftech stocks
tech_names = {'AAPL', 'IBM', 'HPQ', 'MSFT'}
p2 ={key: value for key, value in prices.items() if key in tech_names}
print(p1)
print(p2)
列表推导,我听说挺多的,这个字典推导,让博主也是愣了一愣。

1.18 转换并同时计算数据
你需要在数据序列上执行聚集函数(比如 sum() , min() , max() ), 但是首先你需要先转
换或者过滤数据。
看一下示例代码:
nums= [1, 2, 3, 4, 5]
s =sum(x * x for x in nums)
# Determine if any .pyfiles exist in a directory
print(s)
# Output a tuple as CSV
s =('ACME', 50, 123.45)
print(','.join(str(x) for x in s))
# Data reduction acrossfields of a data structure
portfolio = [
{'name':'GOOG', 'shares': 50},
{'name':'YHOO', 'shares': 75},
{'name':'AOL', 'shares': 20},
{'name':'SCOX', 'shares': 65}
]
min_shares = min(s['shares'] for s in portfolio)
print(min_shares)
运行结果:

这里用的其实还是列表推导式,没什么特别的。
1.19 合并多个字典或映射
现在有多个字典或者映射,你想将它们从逻辑上合并为一个单一的映射后执行某些操作,
比如查找值或者检查某些键是否存在。
ChainMap,这个方法可以合并两个字典,但是如果出现重复键,值会以传递的第一个字典为基准。
a ={'x': 1, 'z': 3 }
b ={'y': 2, 'z': 4 }
from collections import ChainMap
c =ChainMap(a,b)
print(c['x']) # Outputs1 (from a)
print(c['y']) # Outputs2 (from b)
print(c['z']) # Outputs3 (from a)
print(c)
运行结果。















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









