






已知(其中n表示特征数量,m表示样本数量):
1、特征样本
2、标签样本
3、权重向量
4、偏置
5、关系:
线性回归:
线性:因变量和自变量之间是线性关系
回归:因变量是一个连续性变量
训练:把权重和偏置
求解出来
推理:把除训练用到的代入方程求解要预测的
线性回归求解、
的方法:
最小二乘法:
令:
最小二乘法使用python实现模型的训练与预测代码如下:
import numpy as np
class MyLinearRegression(object):
def __init__(self):
#特征数量
self.n_feature = None
#w
self.coef_ = None
#b
self.intercept_ = None
#样本均值
self.mean_ = None
#样本方差
self.std_ = None
def fit(self,X,y):
#变量转numpy
X = np.array(X)
y = np.array(y)
#参数校验
if X.ndim!=2 or y.ndim!=1 or X.shape[0] != y.shape[0]:
raise ValueError("参数输入错误")
#获取特征数量
self.n_feature = X.shape[1]
#获取样本均值
self.mean_ = np.mean(X,axis=0)
#获取样本方差
self.std_ = np.std(X,axis=0) + 1e-9
#样本数据标准化
X = (X - self.mean_) / self.std_
#调整矩阵形状
y = y.reshape(-1,1)
#拼接系数矩阵
X = np.hstack(tup=(X,np.ones(X.shape[0],1)))
#计算w = (w1,...,wn,b)
w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
#获取w
self.coef_ = w.reshape(-1)[:-1]
#获取b
self.intercept_ = w.reshape(-1)[-1]
def predict(self,X):
#变量转numpy
X = np.array(X)
#参数校验
if X.ndim!=2 or X.shape[1]!=self.n_feature:
raise ValueError("参数错误")
#数据预处理
X = (X - self.mean_) / self.std_
return (X.dot(self.coef_) + self.intercept_).reshape(-1)
梯度下降法:
1、任取,已知
令:
即:
将已知 代入
得到预测值为:
此时样本真实值为:
2、计算当前预测值与样本真实值误差统称为损失函数,有多种如下:
| 损失函数 | 公式特点 | 对异常值敏感性 | 可导性 | 典型用途 | 公式 |
|---|---|---|---|---|---|
| MSE | 平方误差 | 高 | 二阶可导 | 一般回归任务 | |
| MAE | 绝对误差 | 低 | 零点不可导 | 鲁棒回归 | |
| Huber | MSE+MAE混合 | 中等 | 分段可导 | 平衡鲁棒性与效率 | |
| Quantile | 非对称惩罚 | 可调 | 分段可导 | 分位数回归 | |
| Log-Cosh | 平滑近似MSE | 中等 | 二阶可导 | 数值稳定优化 | |
| Max Error | 最大化绝对误差 | 极高 | 不可导 | 极端值控制 |
假设选择第一个损失函数MSE,所以可以得到损失函数为:
假设损失函数loss与中的
的函数图像如图所示:
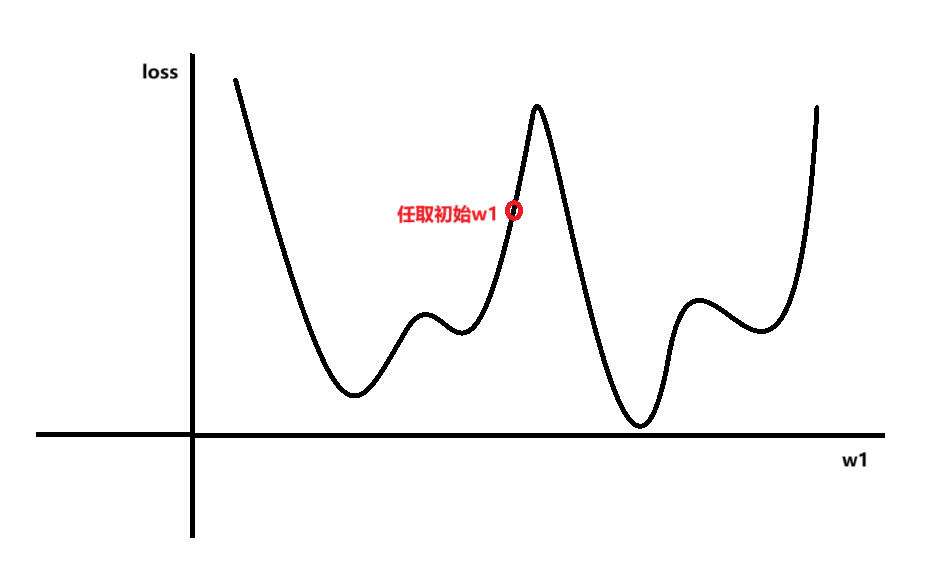
要使的损失函数loss最小,就得通过一轮一轮的训练,每一轮计算函数当前w1
对应的导数,判断当前点是否是最小值以及下一步w1的增大还是减小,直到训
练到loss为相对最小值为止,其中中的其他w和b也类似。
梯度下降法使用python实现模型的训练与预测代码如下:
import torch
import numpy as np
class MyLinearRegression(object):
def __init__(self,max_iter=10000,learning_rate=1e-2):
#初始化最大训练次数
self.max_iter = max_iter
#初始化学习率
self.learning_rate = learning_rate
#初始化特征个数
self.n_featrue = None
初始化w
self.w = None
初始化b
self.b = None
初始化损失值数组
self.losses = []
def fit(self,X,y):
#赋值特征个数
self.n_feature = X.size[1]
#随机生成w,b
self.w = torch.randn(size(self.n_feature,1),requires_gard=True)
self.b = torch.zeros(size(1,),requires_gard=True)
#训练循环
for idx in range(self.max_iter):
#正向传播
y_pred = linear_regression(X)
#求损失函数
loss = self._get_loss(y_true=y,y_pred=y_pred)
#反向传播(计算梯度)
loss.backward()
losses.append(loss.data.item())
#优化一步
self.w -= self.learning_rate * self.w.gard
self.b -= self.learning_rate * self.b.gard
#清空梯度
self.w.gard.zero_()
self.b.gard.zero_()
#判断是否继续迭代
if len(losses) > 2:
if np.abs(losses[-1] - losses[-2]) < 1e-6:
break
def predict(self,X):
return self._linear_regression(X)
def _get_loss(self,y_true,y_pred):
return ((y_true - y_pred) ** 2).mean()
def _linear_regression(self,X):
return self.w.dot(X) + self.b使用pytorch深度学习框架对模型的训练基本步骤如下:
1、正向传播:由于当前已经随机生成了,所以将训练样本
带入已知
线性方程计算出当前预测值。
2、计算损失函数:将预测值和训练样本真实值代入损失函数MSE中,得
到损失函数。
3、反向传播(计算梯度):pytorch框架计算当前损失函数的梯度值
4、优化参数一步(优化参数):将当前
值更新到使损失函数更小一点的值,
即根据模型初始化时超参数学习率leraning_rate和梯度的乘积得出步伐大小和方向
5、清空梯度:重置损失函数对的梯度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









