







feapder官方文档
AirSpider文档
环境要求
Python 3.6.0+
Works on Linux, Windows, macOS
安装
From PyPi:
通用版
pip3 install feapder
完整版:
pip3 install feapder[all]
通用版与完整版区别:
完整版支持基于内存去重
完整版可能会安装出错,若安装出错,请参考安装问题
一、 轻量级爬虫
1、创建爬虫项目
feapder create -p <project_name>

items: 文件夹存放与数据库表映射的item
spiders: 文件夹存放爬虫脚本
main.py: 运行入口
setting.py: 爬虫配置文件
若项目比较简单,不需要这个层次结构管理,也可不创建项目,直接创建爬虫
2. 创建爬虫
爬虫分为3种,分别为 轻量级爬虫(AirSpider)、分布式爬虫(Spider)以及 批次爬虫(BatchSpider)
命令
feapder create -s <spider_name> <spider_type>
AirSpider 对应的 spider_type 值为 1
Spider 对应的 spider_type 值为 2
BatchSpider 对应的 spider_type 值为 3
默认 spider_type 值为 1
AirSpider爬虫示例:
feapder create -s first_spider 1
此命令参考官方文档报错

使用下列命令即可:
feapder create -s first_spider

first_spider.py 整体代码:
# -*- coding: utf-8 -*-
import feapder
import random
from items.spider_data_item import SpiderDataItem
class FirstSpider(feapder.AirSpider):
def start_requests(self):
for i in range(1,10):
url = f"https://www.willsfitness.net/api/v1/shops?type=&province=&city=&pageNo={i}&pageSize=10"
yield feapder.Request(url)
def parse(self, request, response):
# print(f"url:{response.url}")
print(response.json)
data = response.json
shops = data.get("shops")
for shop in shops:
item = SpiderDataItem()
item.code = shop.get("code")
item.name = shop.get("name")
print(item)
yield item
def download_midware(self, request):
"""
下载中间件
:param request:
:return:
"""
# 自定义请求头,否则会自动随机
request.headers = {
"Host": "www.willsfitness.net",
"Referer": "https://www.willsfitness.net/trademark",
"User-Agent": f"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/5{random.randint(20, 50)}.36"
}
# request.cookies = {}
# request.proxies = {}
return request
if __name__ == "__main__":
FirstSpider().start()
3、数据自动入库
除了导入MysqlDB这种方式外,Spider支持数据自动批量入库。我们需要将数据封装为一个item,然后返回给框架即可。步骤如下:
1、建表
示例
CREATE TABLE `spider_data` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
2、创建item前要配置seeting文件
# # MYSQL
MYSQL_IP = "localhost"
MYSQL_PORT = 3306
MYSQL_DB = "spiders"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "xxxx"
# # 数据入库的pipeline,可自定义,默认MysqlPipeline
ITEM_PIPELINES = [
"feapder.pipelines.mysql_pipeline.MysqlPipeline",
# "feapder.pipelines.mongo_pipeline.MongoPipeline",
]
3、创建item,
item为与数据库表的映射,与数据入库的逻辑相关。 在使用此命令前,需在数据库中创建好表,且setting.py中配置好数据库连接地址
命令
feapder create -i <item_name>
feapder create -i spider_data
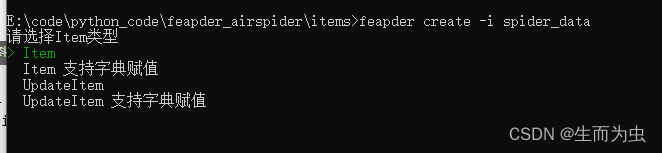
若item字段过多,不想逐一赋值,可选择支持字典赋值的Item类型创建
生成如下代码:
from feapder import Item
class SpiderDataItem(Item):
"""
This class was generated by feapder
command: feapder create -i spider_data
"""
__table_name__ = "feapder_airspider"
def __init__(self, *args, **kwargs):
self.code = None
# self.id = None
self.name = None
self.date = None
self.spider_time = None
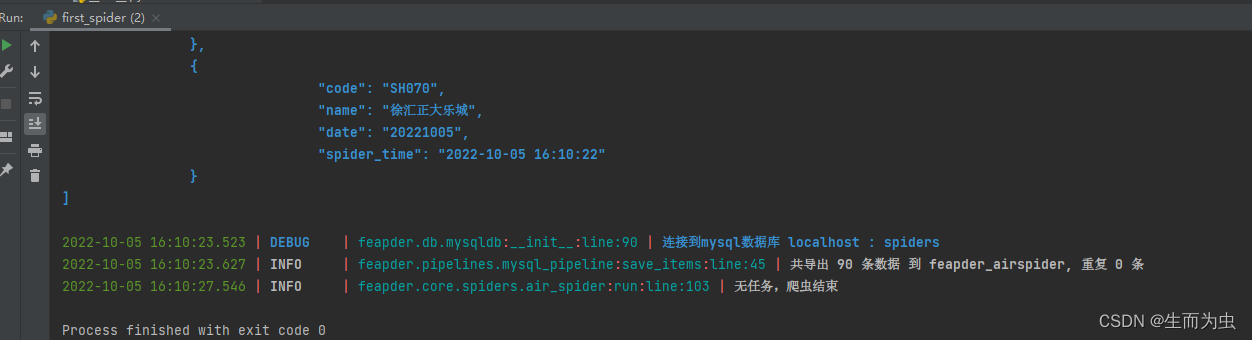
执行爬虫,结果如图
轻量级爬虫测试代码下载:
二 、分布式爬虫-Spider
1. 创建项目
示例:
feapder create -p 项目名
feapder create -p feapder_fbs
2.创建爬虫
示例:
feapder create -s 爬虫名
feapder create -s spider_test
选择爬虫模板
生成代码如下:
# -*- coding: utf-8 -*-
"""
Created on 2022-10-05 15:18:25
---------
@summary:
---------
@author: 30306
"""
import feapder
class SpiderTest(feapder.Spider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379", REDISDB_USER_PASS="", REDISDB_DB=0
)
def start_requests(self):
yield feapder.Request("https://spidertools.cn")
def parse(self, request, response):
# 提取网站title
print(response.xpath("//title/text()").extract_first())
# 提取网站描述
print(response.xpath("//meta[@name='description']/@content").extract_first())
print("网站地址: ", response.url)
if __name__ == "__main__":
SpiderTest(redis_key="xxx:xxx").start()
配置信息:
REDISDB_IP_PORTS: 连接地址,若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个REDISDB_SERVICE_NAME参数
REDISDB_USER_PASS: 连接密码
REDISDB_DB:数据库
Spider参数:
redis_key为redis中存储任务等信息的key前缀,如redis_key=“feapder:spider_test”, 则redis中会生成如下
3、数据自动入库
除了导入MysqlDB这种方式外,Spider支持数据自动批量入库。我们需要将数据封装为一个item,然后返回给框架即可。步骤如下:
1、建表
示例
CREATE TABLE `spider_data` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
2、创建item前要配置seeting文件
# # MYSQL
MYSQL_IP = "localhost"
MYSQL_PORT = 3306
MYSQL_DB = "spiders"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "xxxx"
# # 数据入库的pipeline,可自定义,默认MysqlPipeline
ITEM_PIPELINES = [
"feapder.pipelines.mysql_pipeline.MysqlPipeline",
# "feapder.pipelines.mongo_pipeline.MongoPipeline",
]
3、创建item,
item为与数据库表的映射,与数据入库的逻辑相关。 在使用此命令前,需在数据库中创建好表,且setting.py中配置好数据库连接地址
命令
feapder create -i <item_name>
feapder create -i feapder_fbs
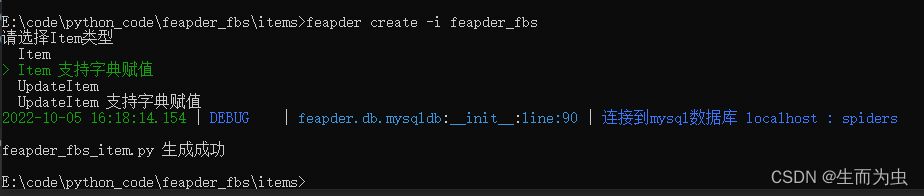
若item字段过多,不想逐一赋值,可选择支持字典赋值的Item类型创建
生成如下:
class FeapderFbsItem(Item):
"""
This class was generated by feapder
command: feapder create -i feapder_fbs 1
"""
__table_name__ = "feapder_fbs"
def __init__(self, *args, **kwargs):
self.code = kwargs.get('code')
self.name = kwargs.get('name')
self.date = kwargs.get('date')
self.spider_time = kwargs.get('spider_time')
4. 调试
开发过程中,我们可能需要针对某个请求进行调试,常规的做法是修改下发任务的代码。但这样并不好,改来改去可能把之前写好的逻辑搞乱了,或者忘记改回来直接发布了,又或者调试的数据入库了,污染了库里已有的数据,造成了很多本来不应该发生的问题。
本框架支持Debug爬虫,可针对某条任务进行调试,写法如下:
if __name__ == "__main__":
spider = SpiderTest.to_DebugSpider(
redis_key="feapder:spider_test", request=feapder.Request("http://www.baidu.com")
)
spider.start()
三 、批次爬虫BatchSpider
TaskSpider是一款分布式爬虫,内部封装了取种子任务的逻辑,内置支持从redis或者mysql获取任务,也可通过自定义实现从其他来源获取任务
1. 创建项目
feapder create -p <project_name>
feapder create -p feapder_task
2、创建爬虫
feapder create -s batch_spider_test
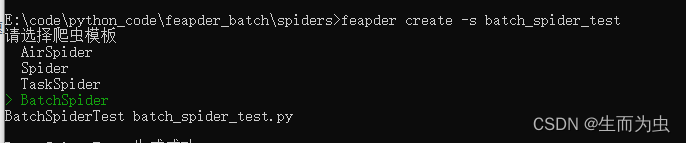
生成如下
import feapder
class BatchSpiderTest(feapder.BatchSpider):
# 自定义数据库,若项目中有setting.py文件,此自定义可删除
__custom_setting__ = dict(
REDISDB_IP_PORTS="localhost:6379",
REDISDB_USER_PASS="",
REDISDB_DB=0,
MYSQL_IP="localhost",
MYSQL_PORT=3306,
MYSQL_DB="feapder",
MYSQL_USER_NAME="feapder",
MYSQL_USER_PASS="feapder123",
)
def start_requests(self, task):
yield feapder.Request("https://www.baidu.com")
def parse(self, request, response):
print(response)
if __name__ == "__main__":
spider = BatchSpiderTest(
redis_key="xxx:xxxx", # 分布式爬虫调度信息存储位置
task_table="", # mysql中的任务表
task_keys=["id", "xxx"], # 需要获取任务表里的字段名,可添加多个
task_state="state", # mysql中任务状态字段
batch_record_table="xxx_batch_record", # mysql中的批次记录表
batch_name="xxx(周全)", # 批次名字
batch_interval=7, # 批次周期 天为单位 若为小时 可写 1 / 24
)
# spider.start_monitor_task() # 下发及监控任务
spider.start() # 采集
因BatchSpider是基于redis做的分布式,mysql来维护任务种子及批次信息,因此模板代码默认给了redis及mysql的配置方式,连接信息需按真实情况修改
3. 代码讲解
配置信息:
REDISDB_IP_PORTS: 连接地址,若为集群或哨兵模式,多个连接地址用逗号分开,若为哨兵模式,需要加个REDISDB_SERVICE_NAME参数
REDISDB_USER_PASS: 连接密码
REDISDB_DB:数据库
BatchSpider参数:
1、redis_key:redis中存储任务等信息的key前缀,如redis_key=“feapder:spider_test”, 则redis中会生成如下

2、task_table:mysql中的任务表,为抓取的任务种子,需要运行前手动创建好
3、task_keys:任务表里需要获取的字段,框架会将这些字段的数据查询出来,传递给爬虫,然后拼接请求
4、task_state:任务表里表示任务完成状态的字段,默认是state。字段为整形,有4种状态(0 待抓取,1抓取完毕,2抓取中,-1抓取失败)
5、batch_record_table:批次信息表,用于记录批次信息,由爬虫自动创建
6、batch_name: 批次名称,可以理解成爬虫的名字,用于报警等
7、batch_interval:批次周期 天为单位 若为小时 可写 1 / 24
启动:BatchSpider分为master及work两种程序
1、master负责下发任务,监控批次进度,创建批次等功能,启动方式:
spider.start_monitor_task()
2、worker负责消费任务,抓取数据,启动方式:
spider.start()
更详细的说明可查看 BatchSpider进阶
执行分布式爬虫前必须先建好相关表
1、任务表 batch_spider_task(用于存放任务)

2、数据表(用于存储数据)
根据自身爬虫采集字段创建
4、注意事项
1、运行前加此段代码更新任务状态,否则任务会一直重复执行
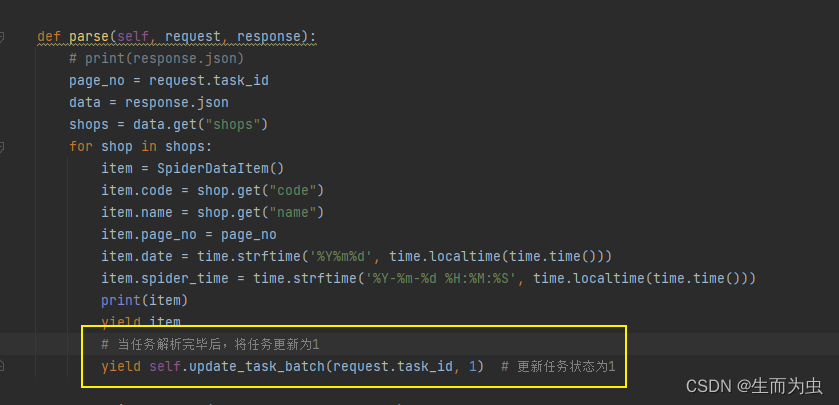
运行结果截图
1、下发任务及监控进度:
python main.py --crawl_test 1
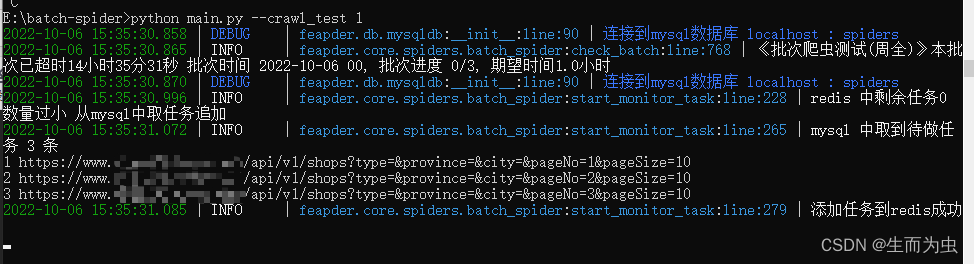
2、采集
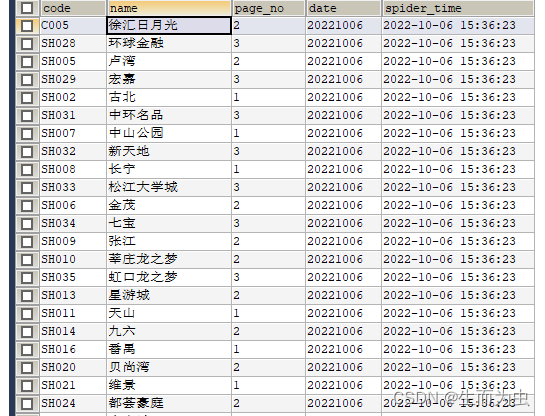
3、采集结果如下图:
















 3887
3887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











