







摘要
现有方法局限
现有方法在静态图像或视频上进行嘴唇同步有很好的性能,但对于动态的说话不受约束的人脸视频仍然难以很好的嘴唇同步。
本文方法
通过学习一个强大的唇部同步鉴别器来解决这些问题。接着,提出了新的严格评估基准和指标,以准确衡量不受限制视频中的唇部同步。通过在我们具有挑战性的基准上的广泛定量评估,结果表明,Wav2Lip模型生成的视频的唇部同步精度几乎与真实同步视频一样好。
引言
应用需求
随着音视频内容消费的指数级增长,快速视频内容创作已成为一种基本需求。同时,使这些视频能够以不同的语言被更多人所接受也是一个关键挑战。例如,如果将深度学习讲座系列、著名电影或国家公开演讲翻译成目标语言,它们就能被数百万新观众所接受。在翻译这样的面部视频或创建新视频的过程中,一个关键的方面是纠正唇部同步以匹配目标语音。因此,将给定输入音轨与说话面部视频的唇部同步匹配的研究受到了广泛关注。
背景
早期的工作使用深度学习从语音表示到唇部标志点的映射学习,需要几个小时单一说话者的数据。最近的工作直接从语音表示生成图像,并展示了对于他们所训练的特定说话者来说,生成质量异常出色的能力。然而,许多实际应用需要模型能够立即处理通用身份和语音输入。这导致了说话者无关的语音到唇部生成模型的创建,这些模型是在成千上万的身份和声音上训练的。他们可以在任何身份的单个静态图像上生成准确的唇部动作,包括由文本到语音系统生成的合成语音。然而,要用于例如翻译讲座/电视剧等应用,这些模型需要能够在这些动态、不受限制的视频中改变广泛的唇形多样性,而不仅仅是在静态图像上。我们的工作建立在后一类说话者无关的工作中,这些工作旨在为任何身份和声音的视频进行唇部同步。我们发现,对于静态图像效果很好的这些模型无法准确地改变不受限制的视频内容中大量的唇形,导致生成的视频与新的 target 音频显著不同步。观众可以识别出只有大约0.05-0.1秒的不同步视频片段。因此,令人信服地将真实世界的视频与全新的语音进行唇部同步是非常具有挑战性的,考虑到允许的错误程度非常小。此外,我们的目标是在没有任何额外的说话者特定数据开销的情况下,采用说话者无关的方法,这使我们的任务变得更加困难。
原因分析
实际视频中包含快速的姿势、规模和光照变化,生成的面部结果还必须无缝地融入原始目标视频中。我们首先检查现有的说话者无关的语音到唇部生成方法。我们发现这些模型没有充分惩罚错误的唇形,要么是因为只使用重建损失,要么是因为唇部同步鉴别器不够强大。
本文贡献
我们采用了一个强大的唇部同步鉴别器,可以强制生成器始终产生准确、真实的唇部动作。接下来,我们重新审视当前的评估协议,并提出了新的严格评估基准,这些基准源自三个标准测试集。我们还提出了使用SyncNet进行可靠评估的可靠评估指标,以精确评估不受限制视频中的唇部同步。我们还收集并发布了ReSyncED,这是一个具有挑战性的现实世界视频集,可以基准测试模型在实践中的表现。我们进行了广泛的定量和主观人类评估,并在所有基准上大幅超越了先前的方法。我们的主要贡献/声明如下:
- 我们提出了一种新的唇部同步网络Wav2Lip,它比以前的工作在野外任意说话面部视频的唇部同步方面更加准确。
- 我们提出了一个新的评估框架,包括新的基准和指标,以便在不受限制的视频中公平地评判唇部同步。
- 我们收集并发布了ReSyncED,这是一个真实世界的唇部同步评估数据集,用于基准测试唇部同步模型在完全未见过的野外视频上的表现。
- Wav2Lip是第一个说话者无关的模型,生成的视频唇部同步精度与真实同步视频相匹配。人类评估表明,Wav2Lip生成的视频比现有方法和未同步版本更受欢迎,超过90%的时间。
- 我们的网站上可以找到演示视频,其中包含几个定性示例,清楚地说明了我们的模型的影响。我们还将发布网站上的交互式演示,允许用户使用他们选择的音频和视频样本尝试模型。论文的其余部分组织如下:第2节调查了语音到唇部生成领域的最新发展,第3节讨论了现有作品的问题,并描述了我们提出的缓解措施,第4节提出了一个新的可靠评估框架。我们在第5节讨论了各种潜在应用,并解决了一些伦理问题,最后在第6节中得出结论。
相关工作
- 受约束的说话人脸生成(特定的身份,特定的人物说话视频)
- 特定人物:通过学习输入音频与相应的唇部标志点之间的映射,实现了在奥巴马的视频中生成逼真的说话面部视频。由于这些方法只针对特定说话者进行训练,因此无法为新的身份或声音合成。此外,它们还需要大量特定说话者的数据,通常需要几个小时。
- 一项工作提出了一种通过添加或删除说话中的短语来无缝编辑个别说话者视频的方法。他们仍然需要每个说话者一小时的数据来完成这项任务。
- 另一项工作尝试通过使用两阶段方法来最小化数据开销,首先学习说话者无关的特征,然后用约5分钟的目标说话者数据学习渲染映射。然而,他们在一个明显更小的语料库上训练他们的说话者无关网络,并且还需要每个目标说话者的干净训练数据来为该说话者生成。
- 现有工作的局限(现有工作的另一个限制在于词汇量。一些工作在词汇量有限的数据集上进行训练,例如GRID(56个单词)、TIMIT和LRW(1000个单词),这显著限制了模型从真实视频中学习广泛的音素-音素映射的能力。)
- 无约束的说话人脸生成(任意身份、声音和语言的说话面部视频)
- You Said That?: Synthesising Talking Faces from Audio
- Towards Automatic Face-to-Face Translation
- 给定一个短的语音片段S和一个随机参考面部图像R,网络的任务是生成一个与音频匹配的输入面部的唇部同步版本 Lg,这两项工作都有一个显著的局限性:它们在任意身份的静态图像上工作得非常好,但在尝试在同步无约束的视频时,会产生不准确的唇部生成。
方法
改进了损失函数和口唇同步鉴别器。
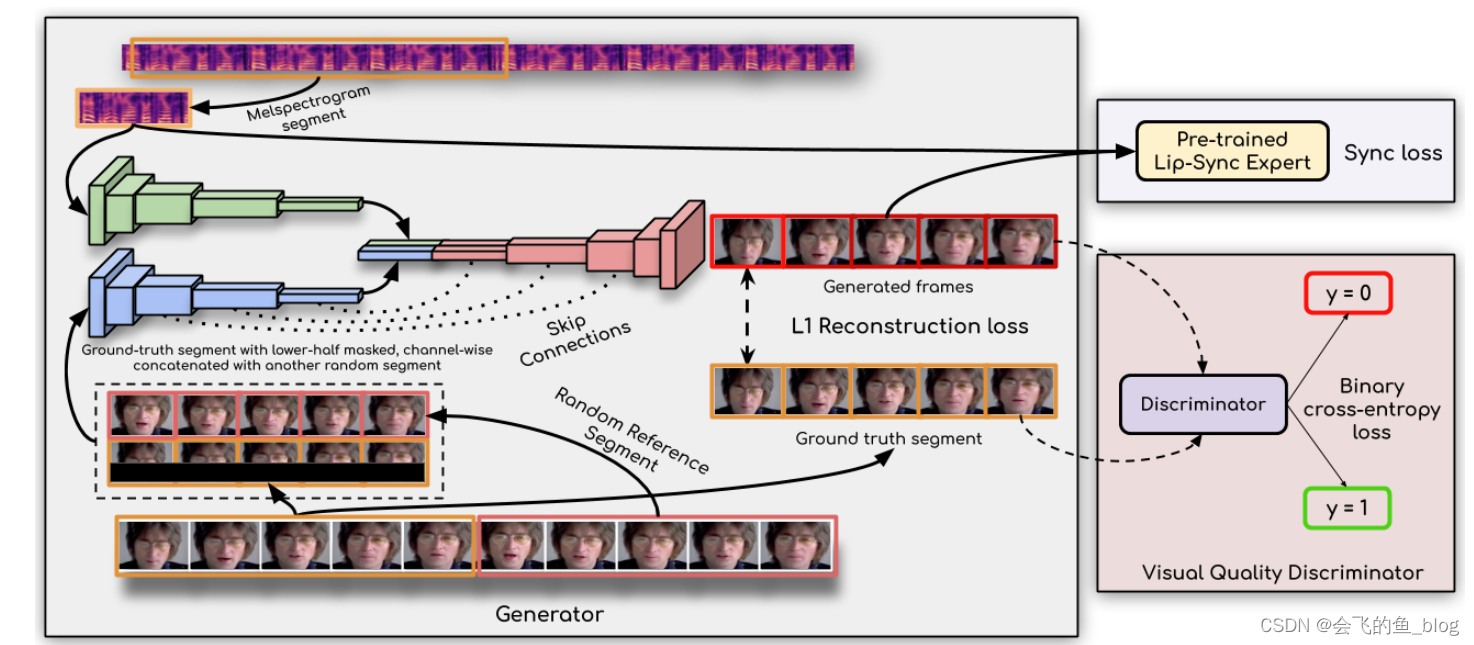
论文设计除了根据视频和声音生成唇音同步的视频的生成模型外,还有两个鉴别器模型
- 生成模型(generator):
- 结构:图像特征编码,语音编码和人脸解码,均为卷积网络
- 输入:视频和音频
- 输出:视频
- 唇音同步鉴别器:
- SyncNet网络结构
- 输入生成的视频帧和原始音频
- 在训练过程中计算同步损失
- 视频质量鉴别器
- GAN网络
- 输入原始视频帧和生成的视频帧,进行二分类判别生成的图片质量好与坏
- 用于训练模型生成高质量的人脸图片
训练过程:
从原始视频中随机采样组成连续帧,和原始音频输入到模型中,用同步鉴别器和视频质量鉴别器对模式生成的视频帧进行反馈学习。
评估方案:
使用Out of Time: Automated Lip Sync in the Wild中的同步自动评估模型(两个指标)
















 8351
8351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









