







 这篇博客介绍了回归分析的基础,包括线性回归和多元线性回归。线性回归中讲解了模型建立、残差分析和模型评估,通过R-squared衡量模型拟合优度。在多元线性回归中,提到了模型筛选的重要性,并详细阐述了向前逐步法的步骤和代码实现,用于寻找最佳变量组合。最终,通过向前法确定了最佳模型,展示了模型筛选对于提升模型解释力的关键作用。
这篇博客介绍了回归分析的基础,包括线性回归和多元线性回归。线性回归中讲解了模型建立、残差分析和模型评估,通过R-squared衡量模型拟合优度。在多元线性回归中,提到了模型筛选的重要性,并详细阐述了向前逐步法的步骤和代码实现,用于寻找最佳变量组合。最终,通过向前法确定了最佳模型,展示了模型筛选对于提升模型解释力的关键作用。
回归分析
一、线性回归
- 1.线性回归:
y
=
β
0
+
β
1
x
1
+
ϵ
,
β
0
截
距
,
β
1
斜
率
y = \beta_0 + \beta_1x_1 +\epsilon , \beta_0截距, \beta_1斜率
y=β0+β1x1+ϵ,β0截距,β1斜率
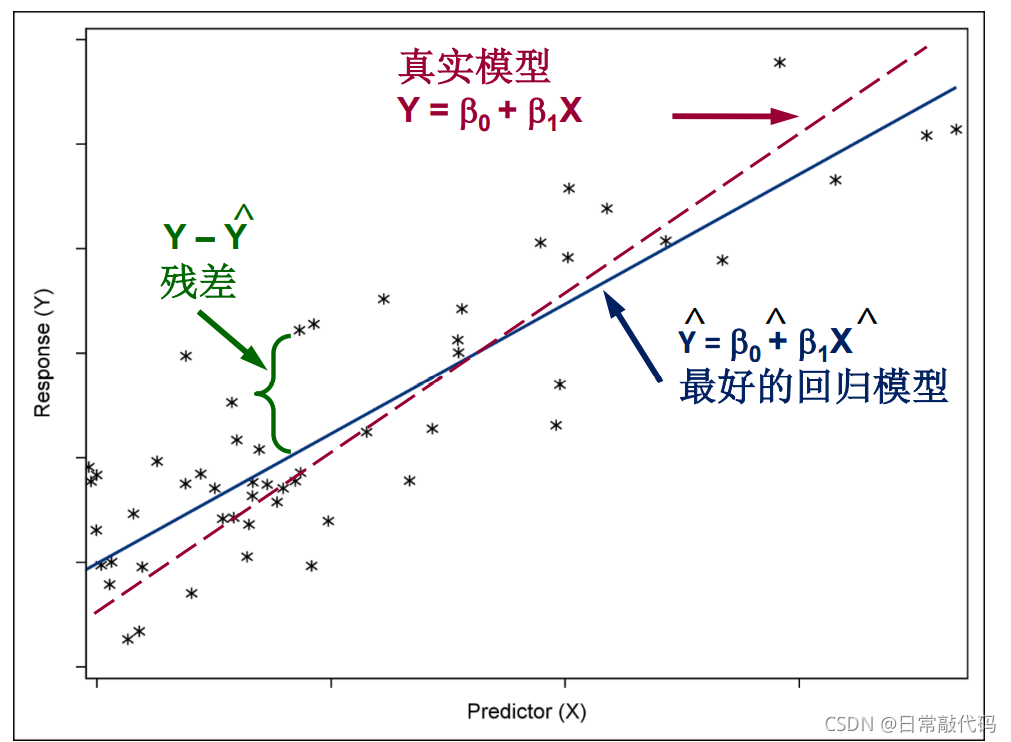
- 2 线性回归的估计
残差:点到线的竖直距离
残差平方和:
L = ∑ ( y i − y ^ ) 2 = ∑ ( y i − ( β 0 + β 1 x 1 ) ) 2 L = \sum{(y_i - \hat{y})^2} = \sum{(y_i - (\beta_0 + \beta_1x_1))^2} L=∑(yi−y^)2=∑(yi−(β0+β1x1))2
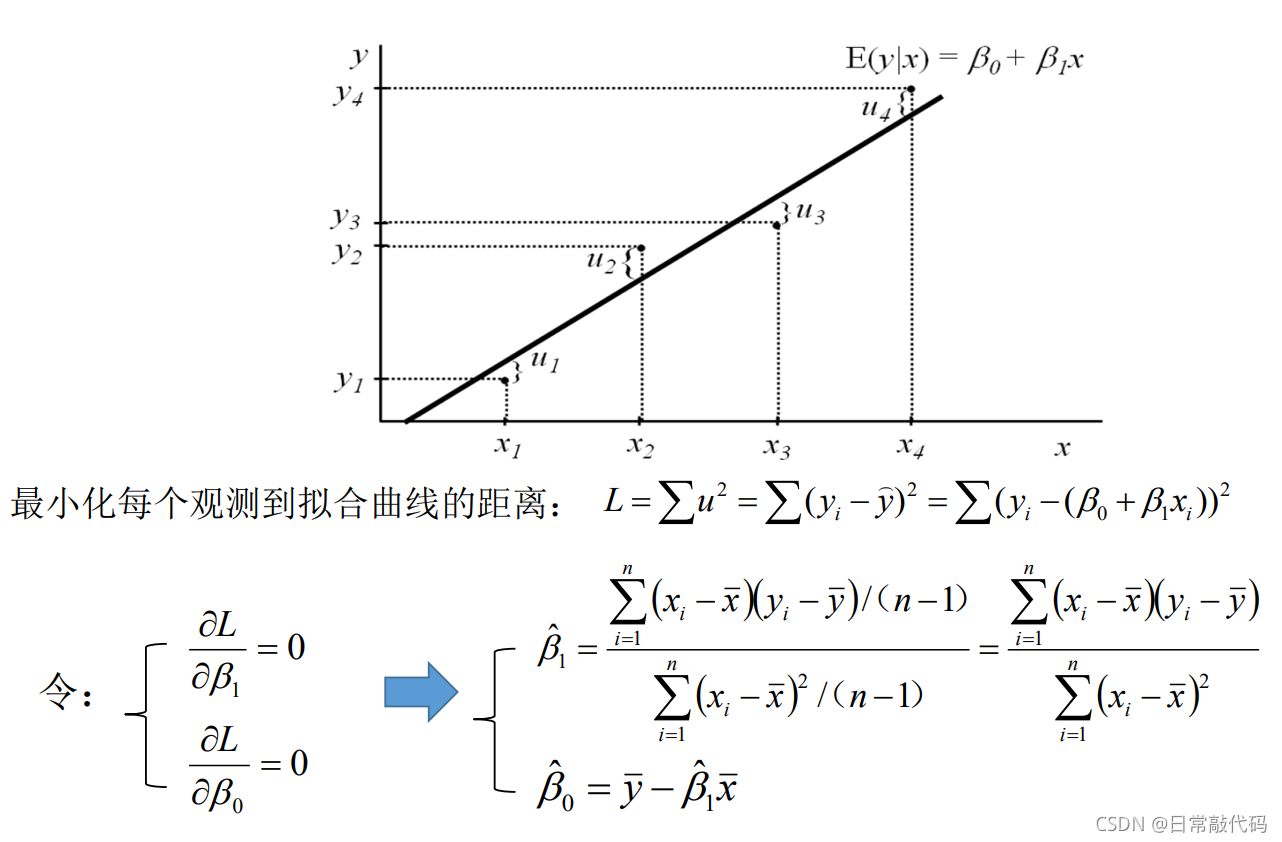
残差平方和越小越好。即线距离每个点的竖直距离平方相加最小。
import matplotlib.pyplot as plt
import os
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
os.chdir(r"E:脚本\7linearmodel")
raw = pd.read_csv(r'creditcard_exp.csv', skipinitialspace=True)
raw.head()

exp = raw[raw['avg_exp'].notnull()].copy().iloc[:, 2:].drop('age2',axis=1)
exp_new = raw[raw['avg_exp'].isnull()].copy().iloc[:, 2:].drop('age2',axis=1)
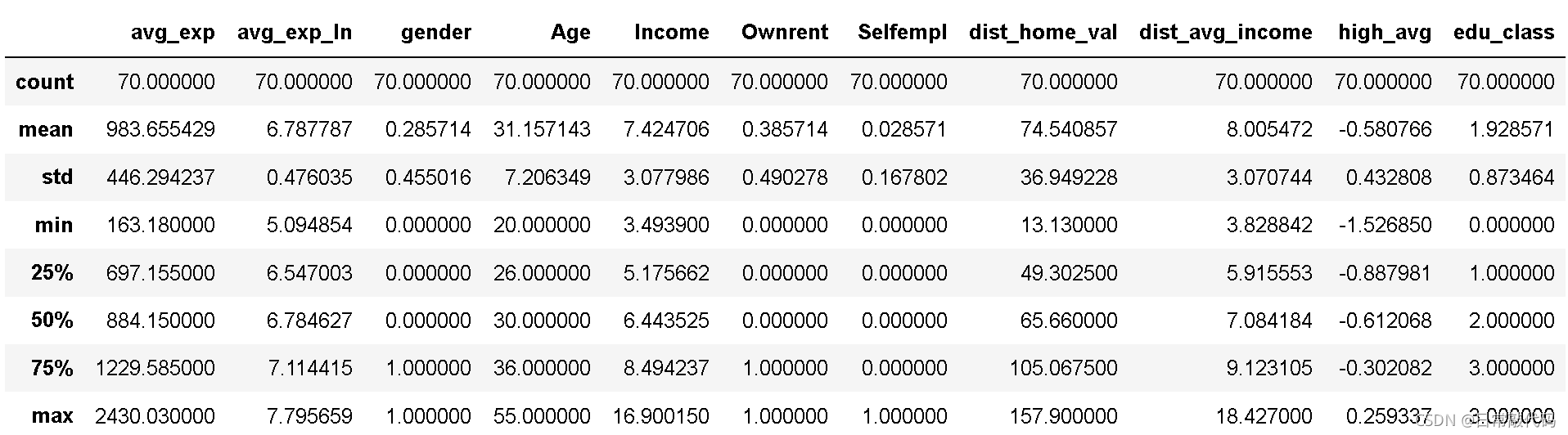
exp.describe(include='all')
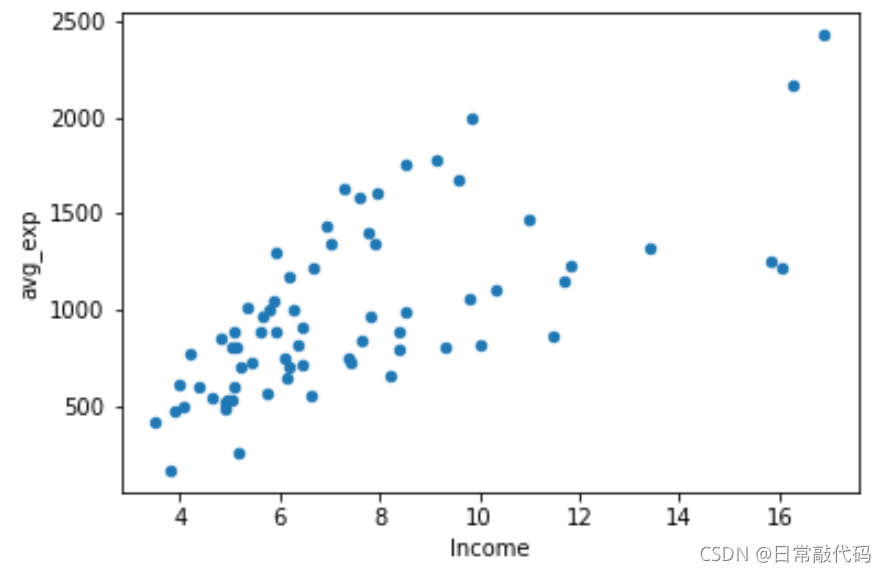
- 散点图:看收入与支出的关系
exp.plot('Income','avg_exp',kind='scatter')
plt.show()
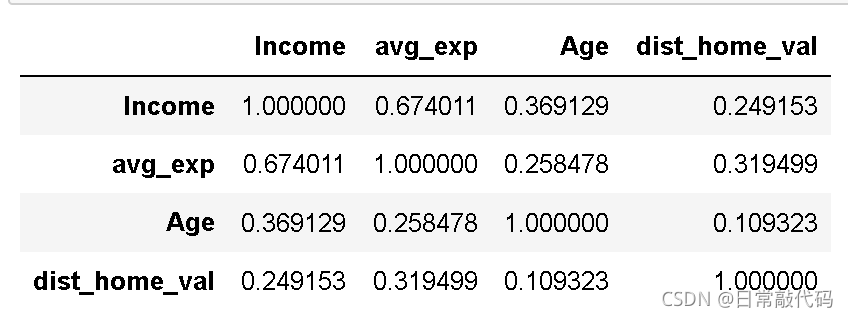
- 相关系数
exp[['Income', 'avg_exp', 'Age', 'dist_home_val']].corr(method='pearson')
-
评价模型的拟合优度的为 R 2 R^2 R2
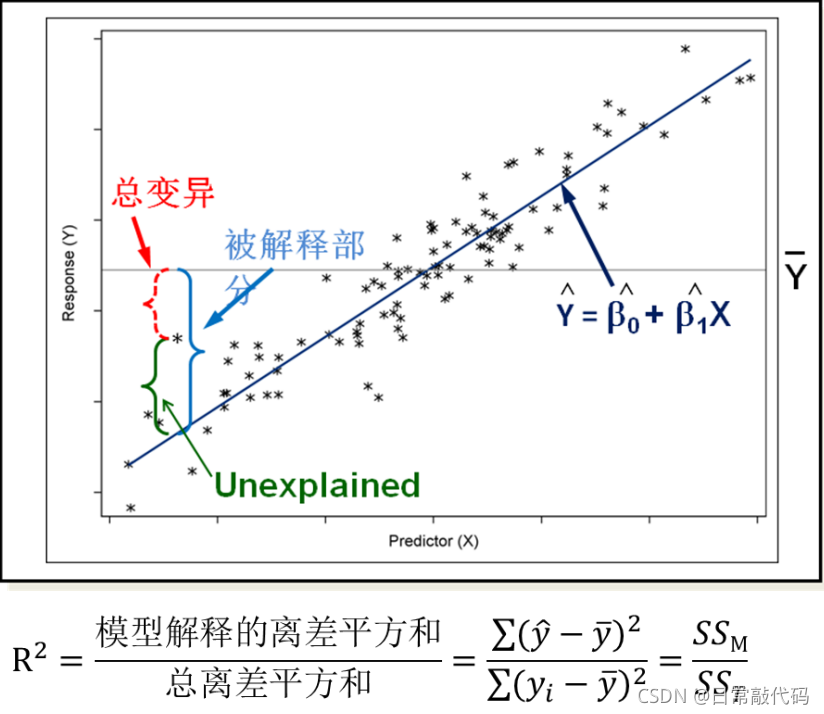
注:不能被模型所解释的:SSE;能被模型所解释的:SSM -
3 线性回归
#调用ols
lm_s = ols('avg_exp ~ Income', data=exp).fit()
lm_s.summary()#简单线性回归的模型完成
# 结果中 先看β1的P值,即P>|t|; 显著了β1才有意义,不显著的话β1在模型中是没有意义的
# Omnibus及其后半部分:是对残差的检验
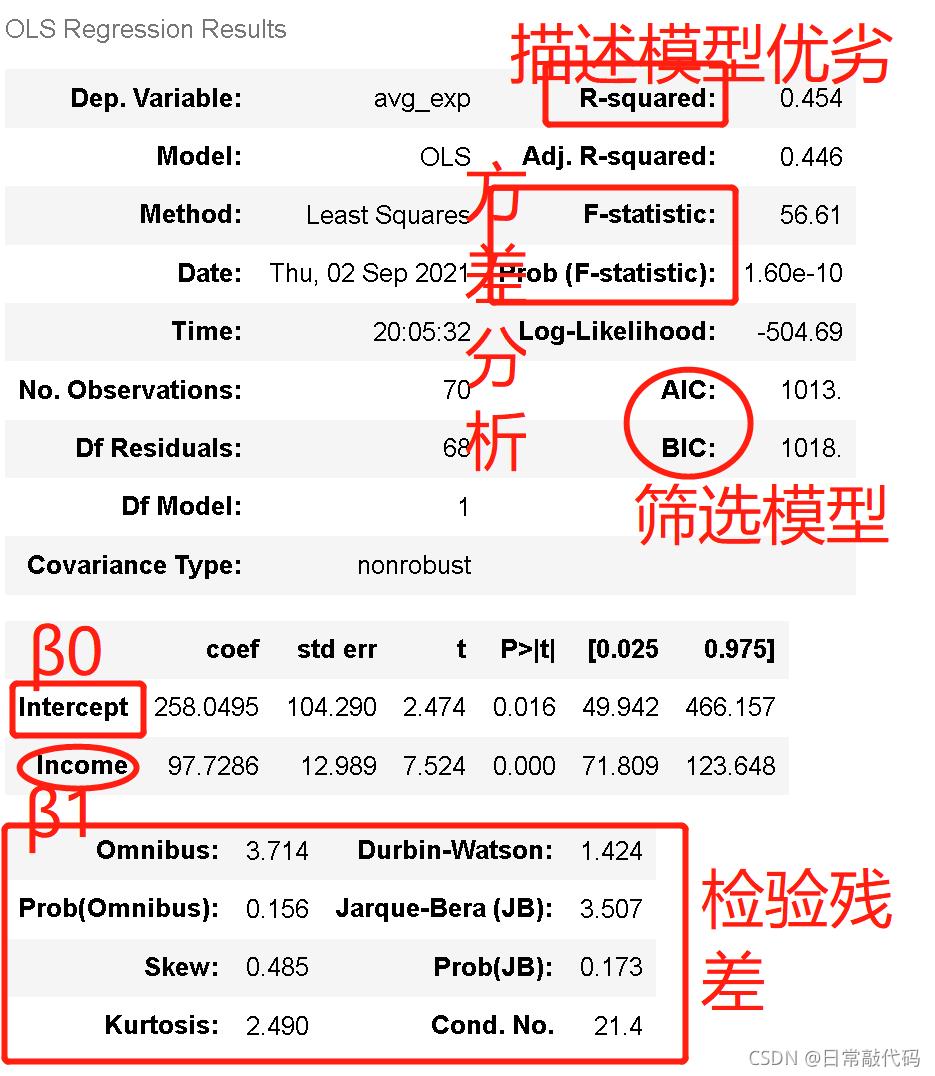
解:
- β1:x每增加一个单位,y增加97.7个单位。
先看β1的p值,显著β1才有意义 - R-squared:是描述模型优劣的,越高越好(最小为0,最小为1)
- Adj. R-squared:是选择模型用的,只有多个模型对比才能有意义,单个模型没有意义;AIC、BIC和Adj. R-squared用处一样
- F-statistic、Prob (F-statistic):方差分析
- 4 检验模型系数是否有意义:单样本T检验
1.提出假设:原假设(β1 = 0)、备择假设(β1 ≠ 0)。如上图可知,β1的P值为0.000,是显著的。
2.多元的情况下,看总体的显著性检验,即F-statistics
3.模型之后产生预测
3.1 单样本(有值)进行预测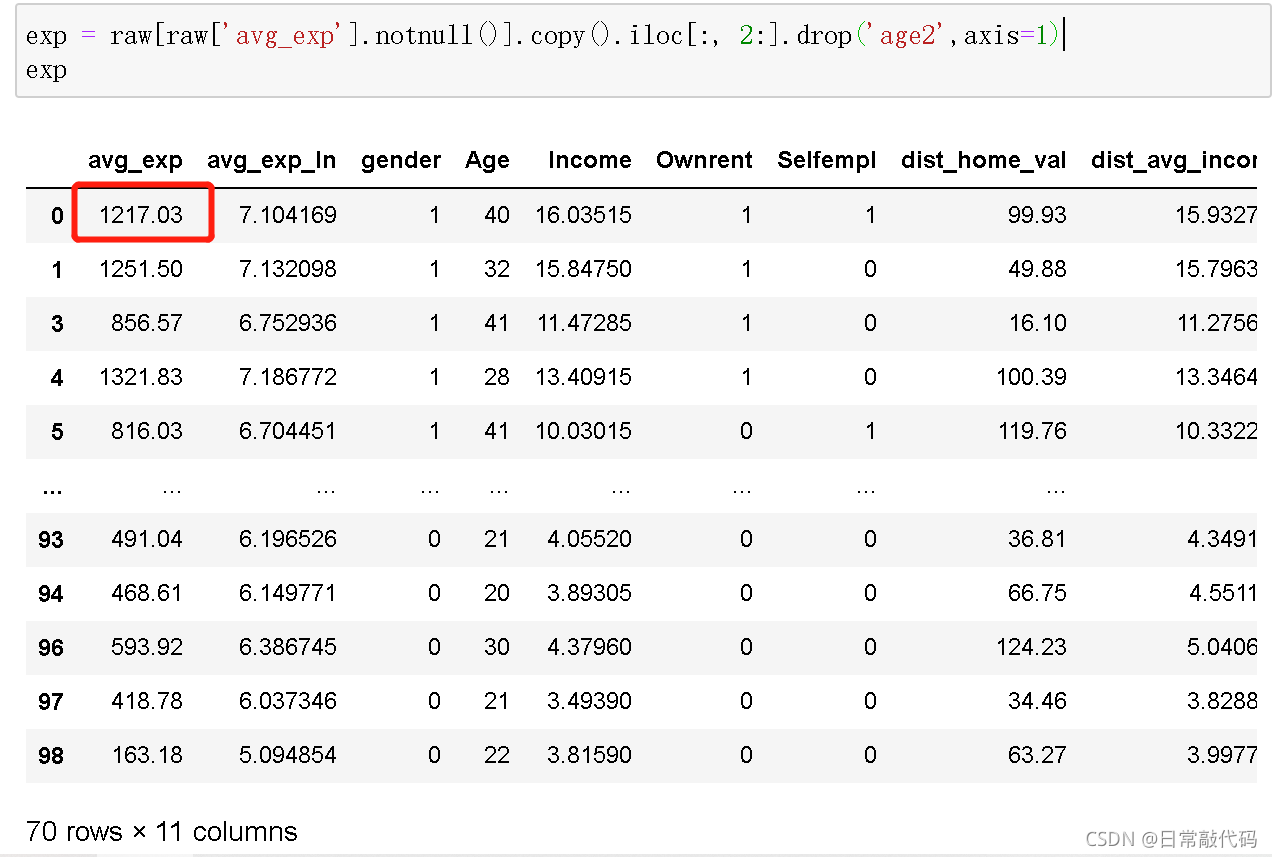
#上述简单线性回归的预测
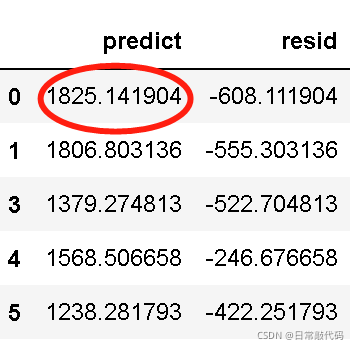
lm_s.predict(exp) #对exp的值进行预测,如1217为实际值,1825为预测值,608为残差
#残差:实际值-预测值
lm_s.resid
#预测值和残差
pd.DataFrame([lm_s.predict(exp),lm_s.resid],index=['predict','resid']).T.head()
3.2 单样本(没有值)进行预测
exp_new = raw[raw['avg_exp'].isnull()].copy().iloc[:, 2:].drop('age2',axis=1)
exp_new
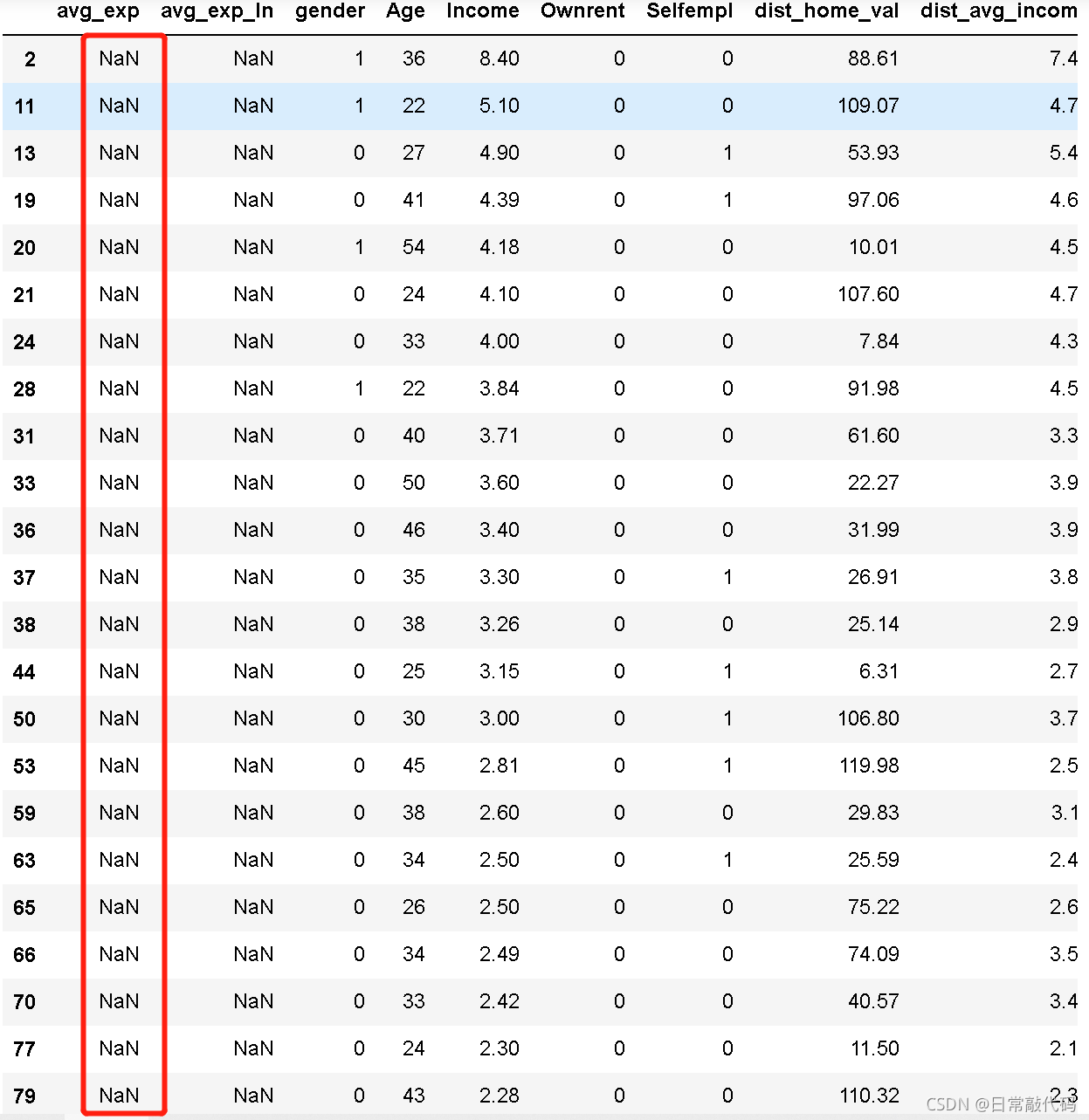
#对没有值的数据进行预测,exp_new值为nan
lm_s.predict(exp_new)[:5]

二、多元线性回归
- 步骤:
- 构建模型
- 模型筛选:
一般用多种方法筛选两两变量相关性检验- 逐步法进行变量筛选
- 向前法
- 向后法
- 逐步法
1建模-对多个X进行建模
#定义模型之后拟合模型
lm_m = ols('avg_exp ~ Age+ Income + dist_home_val + dist_avg_income',data=exp).fit()
lm_m.summary()#输出拟合结果
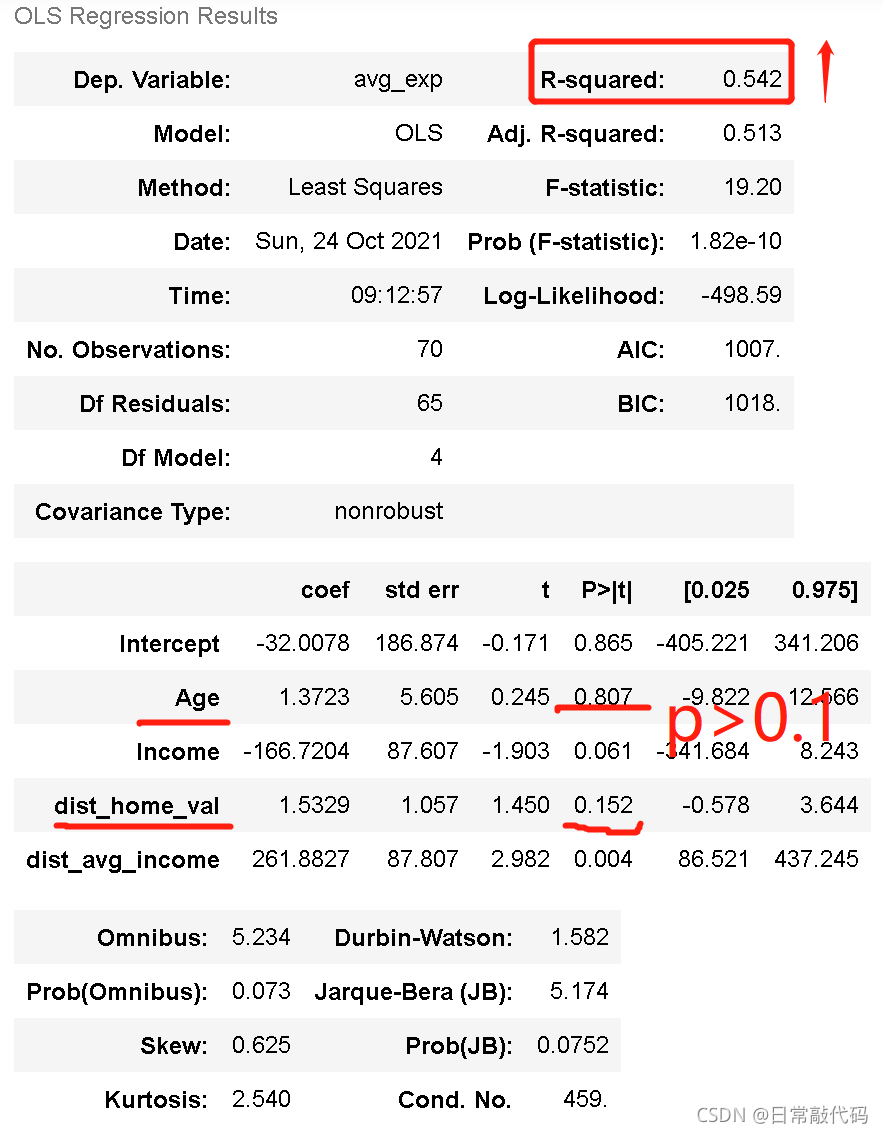
注:根据样本量,显著度α应为0.1,结果可知有两个模型p值>0.1,结果不显著,需要进行模型筛选。
三、回归模型做变量筛选
1.向前逐步法
向前法: 首先第一个变量进入回归方程,并进行F检验和T检验,计算残差平方和,记为S1,如果通过检验,则该变量保留,引入第二个变量,重新构建一个新的估计方程,并进行F检验和T检验,同时计算残差平方和,记为S2。从直观上看,增加一个新的变量后,回归平方和应该增大,残差平方和相应应该减少,即S2小于等于S1,即S1-S2的值是第二个变量的偏回归平方和,直观地说,如果该值明显偏大,则说明第二个变量对因变量有显著影响,反之则没有显著影响。
1.1步骤
一、每个解释变量(x)分别对被解释变量(y)做模型,以某一个标准【P值最小的、R^2最高的、F值最小的、AIC最小的或BIC最小的】选择最好的变量放进去,完成了
y
=
β
k
x
k
y= \beta_kx_k
y=βkxk模型。
二、在给定了第一个变量之后,令残差
ϵ
1
=
y
−
β
k
x
k
\epsilon_1=y - \beta_kx_k
ϵ1=y−βkxk与剩下的x做回归,按照第一步骤的标准选择最好的变量
三、得到第二步的残差
ϵ
2
=
y
−
β
k
x
k
−
β
j
x
j
\epsilon_2=y - \beta_kx_k - \beta_jx_j
ϵ2=y−βkxk−βjxj与其他的剩下的x做回归,步骤同上
四、设定一个截止的阈值,例如P值不能大于5%,则当引入新变量时,每一个都大于5%时,自动停止操作。
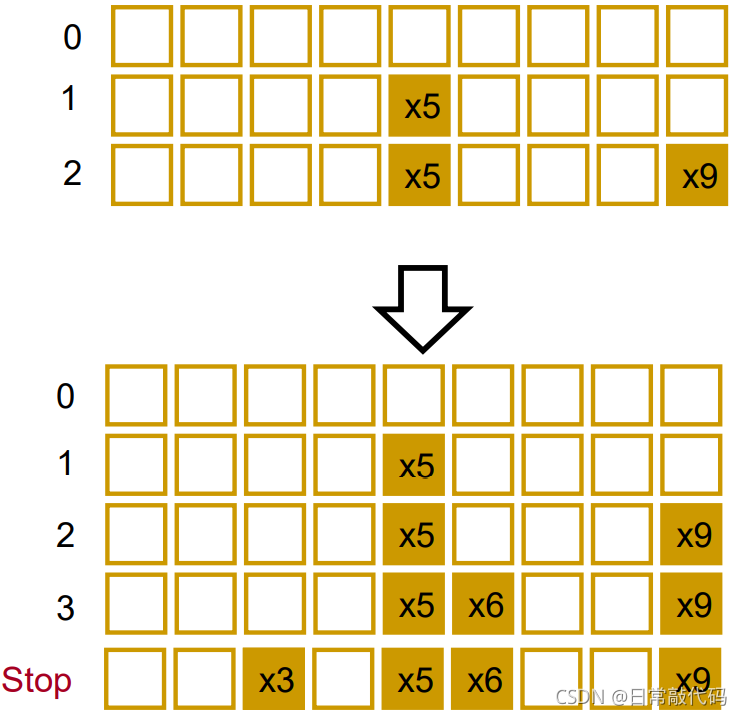
1.2 代码
#向前回归法
'''
data:数据
response:y
'''
def forward_select(data, response):
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
#标准选择的AIC
aic = ols(formula=formula, data=data).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = ols(formula=formula, data=data).fit()
return(model)
#自动筛选出好的模型
data_for_select = exp[['avg_exp', 'Income', 'Age', 'dist_home_val',
'dist_avg_income']]
lm_m = forward_select(data=data_for_select, response='avg_exp')
print(lm_m.rsquared)
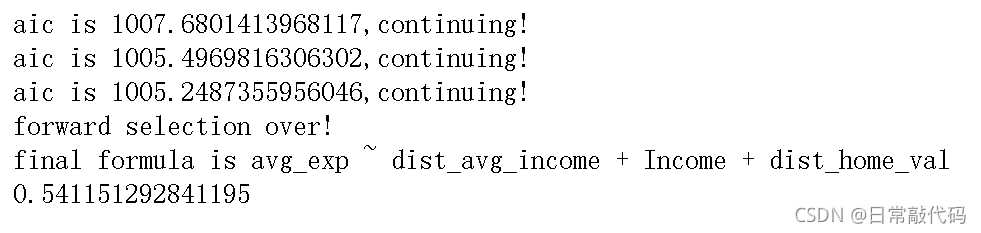
结果可知,设定的是AIC为标准,输出可以看出AIC在逐渐减小,在减小到一定程度就不再继续减小。最后的找出的最好模型是dist_avg_income + Income + dist_home_val 三个变量。这三个变量构成的线性回归效果是最好的,对应的R^2值是0.541151292841195
通过向前法模型筛选找出最好的模型
lm_m.summary()
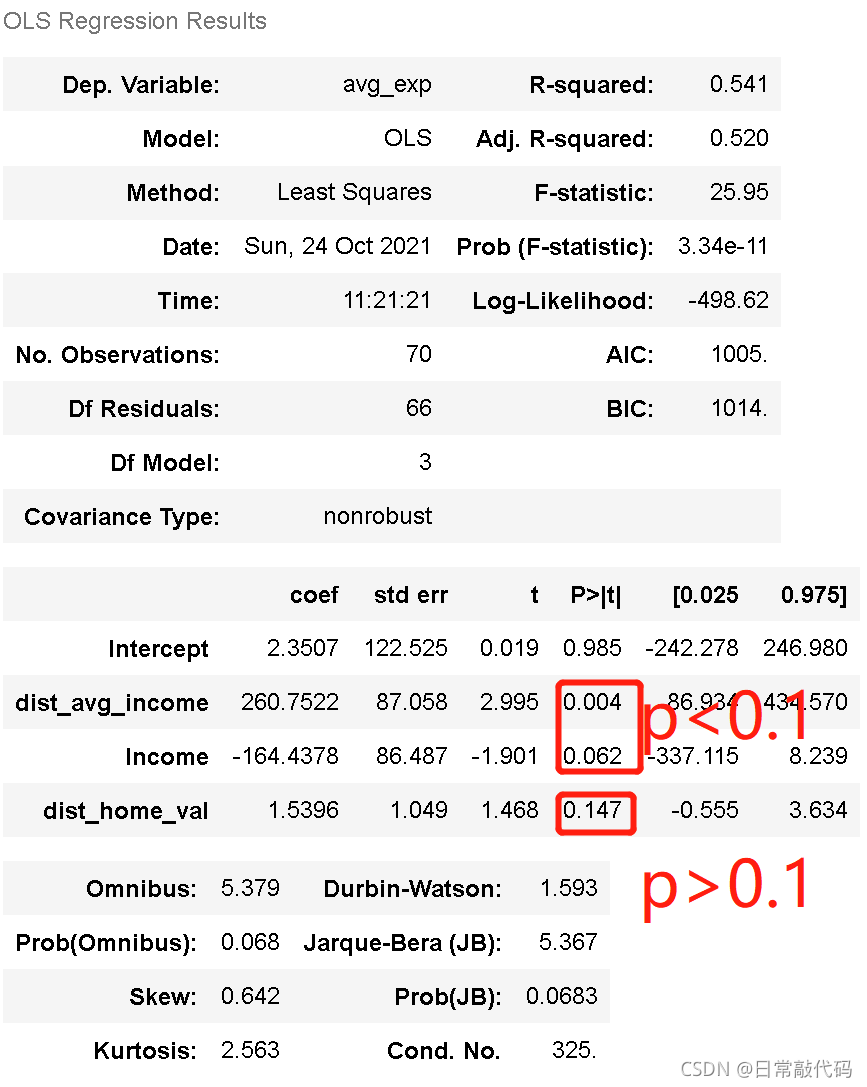
结果可知:存在不显著的模型(p>0.1),AIC算法是贪婪算法,只求AIC最小的模型,不能保证每个模型都是显著的。经过模型筛选之后,可以删除变量。
2 向后法
向后法:同向前回归法正好相反,首先,所有的X变量一次性进入模型进行F检验和T检验,然后逐个删除不显著的变量,删除的原则是根据其偏回归平方和的大小决定去留。如果偏回归平方和很大则保留,反之则删除。
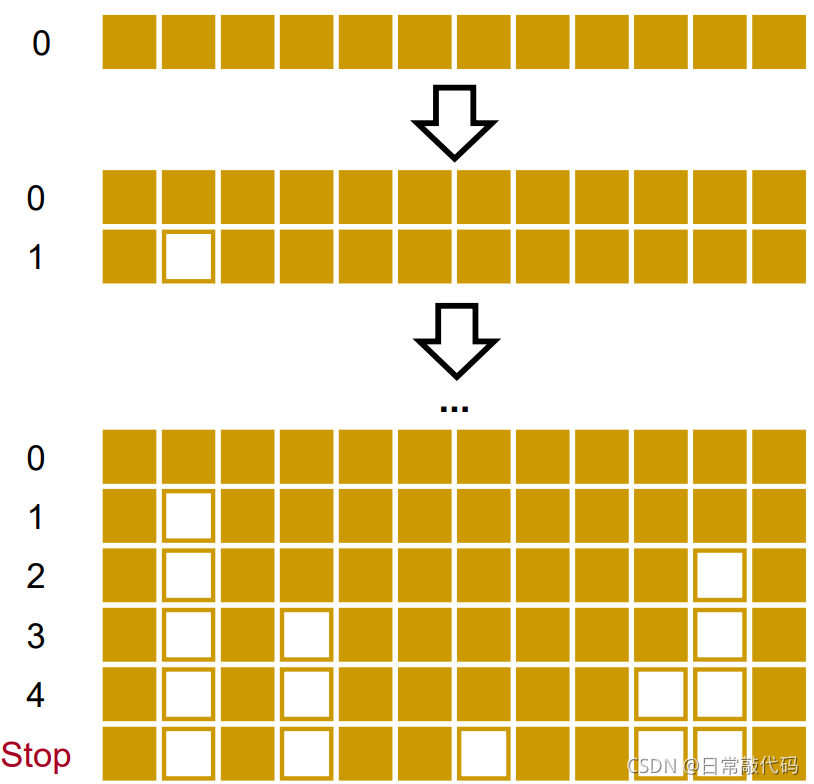
3 逐步法
逐步法:综合向前和向后回归法的特点,变量一个个进入方程,在引入变量时需要利用偏回归平方和进行检验,当显著时才加入该变量,当方程加入了该变量后,又要对原有的老变量重新用偏回归平方和进行检验,一旦某变量变得不显著时要删除该变量,如此下去,直到老变量均不可删除,新变量也无法加入为止。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









