







 本文探讨了北京房价数据,通过描述性统计、自变量分析(城区分布、影响、面积相关性)、取对数处理和线性回归模型,研究了区位、学区属性和房屋面积对房价的影响,并构建了预测模型,包括考虑交互项的对数线性模型。
本文探讨了北京房价数据,通过描述性统计、自变量分析(城区分布、影响、面积相关性)、取对数处理和线性回归模型,研究了区位、学区属性和房屋面积对房价的影响,并构建了预测模型,包括考虑交互项的对数线性模型。
目录
作业要求:
- 因变量分析:单位面积房价分析
- 自变量分析:
1>自变量自身分布情况
2>自变量对因变量影响分析 - 建立房价预测模型
1>线性回归模型
2>对因变量取对数的线性模型
3>考虑交互项的对数线性 - 预测房价
· 涵盖了描述性统计、统计推断、线性回归三个章节
一:数据展示
import pandas as pd
import numpy as np
import math
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
from numpy import corrcoef,array
# from numpy import corrconf,array
from statsmodels.formula.api import ols
matplotlib.rcParams['axes.unicode_minus']=False #解决符号问题
plt.rcParams['font.sans-serif']=['SimHei'] #指定默认字体,时显示中文
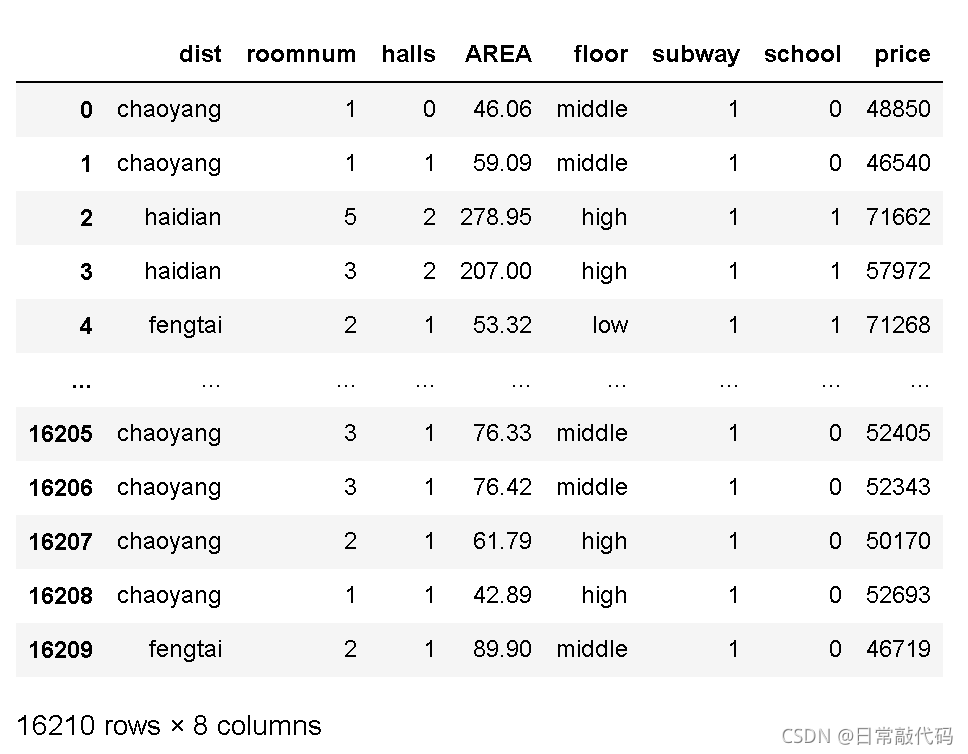
dat11 = pd.read_csv(r'E:\sndHsPr.csv')
dat11
变量含义:
| 列变量 | 含义 |
|---|---|
| roomnum | 几室 |
| subway | 是否临近地铁 |
| halls | 几厅 |
| school | 是否学区房 |
| AREA | 房屋面积 |
| price | 房屋每平米价格 |
| floor | 中层、低层、高层 |
二:数据基本情况
描述性统计分析:样本量全部使用
假设检验、建模:不能全部使用原始数据,进行抽样使用
In[] : dat0=dat11 - 数据转存
In[] : dat0.shape[0]
Out[] : 16210
- 样本量超过5000,p值没有意义==》所以进行建模和检验时进行抽样
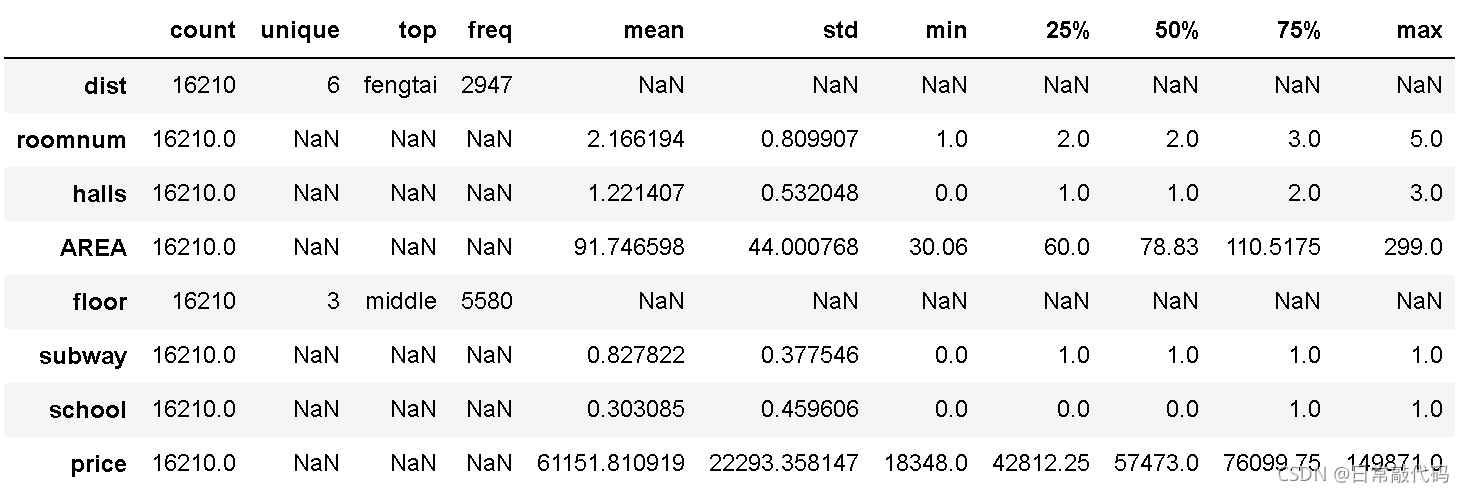
dat0.describe(include='all').T
- 竖列是统计量,横列是变量
- 连续变量:输出的是百分位数、中位数等
- 分类变量:输出的是频次信息
注: qq 图和PP 图用来检验某个分布是否符合正态分布,在统计占有一定的地位。在数据分析的时候,直方图已经可以能够描述了。
三:因变量分析
步骤一:数据整理
- 单位面积房价:单位换成万元
dat0.price=dat0.price/10000
- 区名换为中文
dict1 = {
u'chaoyang':'朝阳',
u'dongcheng':'东城',
u'fengtai':'丰台',
u'haidian':'海淀',
u'shijingshan':'石景山',
u'xicheng':'西城'
}
dat0.dist = dat0.dist.apply(lambda x : dict1[x])
dat0.head()

步骤二:直方图
只要是数据分析且是连续变量,必须画直方图。防止出现异常值等错误。
dat0.price.hist(bins=20) - 分20项
plt.xlabel('单位面积房价(万元/平方米)')
plt.ylabel('频数')
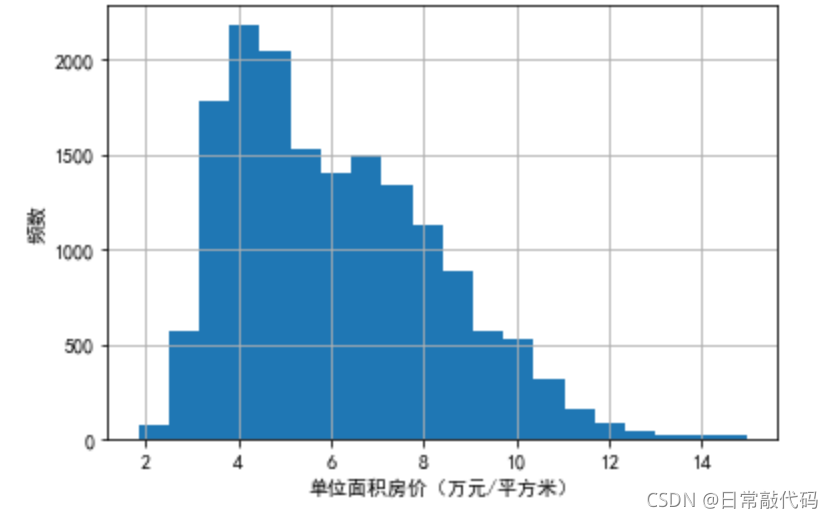
- 根据上述直方图,可以看出因变量成右偏函数,需要考虑取对数。
步骤三:描述性统计分析
- 连续变量:最大值、最小值、均值、中位数、标准差、四分位数
- 分类变量:频次分析
- 均值、中位数、标准差
In[]:dat0.price.agg(['mean','median','std'])
Out[]:
mean 6.115181
median 5.747300
std 2.229336
- 四分位数
In[] : dat0.price.quantile([0.25,0.5,0.75])
Out[]:
0.25 4.281225
0.50 5.747300
0.75 7.609975
- 关注异常值,对数据有个基本的认识
- 找出最低价格和最高价格对应的是哪个观测值,符合常理。
pd.concat([(dat0[dat0.price==min(dat0.price)]),(dat0[dat0.price==max(dat0.price)])])

四、自变量分析
步骤一:看整体数据
- 整体数据没有异常值
- 数据分为分类变量和连续变量两类
'''
根据数据可知,六个自变量有5个是分类变量,1个是连续变量;Y值是price
'''
for i in range(7):
if i!=3: # AREA是连续变量,不进行频次分析
print(dat0.columns.values[i],':')
print(dat0[dat0.columns.values[i]].agg(['value_counts']).T)
print('------------------------------------------')
else:
continue
print('AREA:')
print(dat0.AREA.agg(['min','max','median','std']).T)
# 样本量/总样本数>=0.05,样本的数量就不算太少

步骤二:对分类变量(城区)分析
1 自变量自身分布
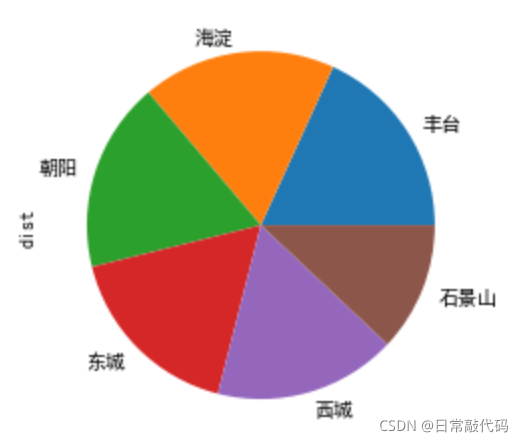
- 城区频次分析
data.dist.value_counts().plot(kind='pie')
2 自变量对因变量的影响分析
- 看每个区的平均房价是多少
- 方法一:柱形图
data.price.groupby(dat0.dist).mean().sort_values(ascending=True).plot(kind='barh')
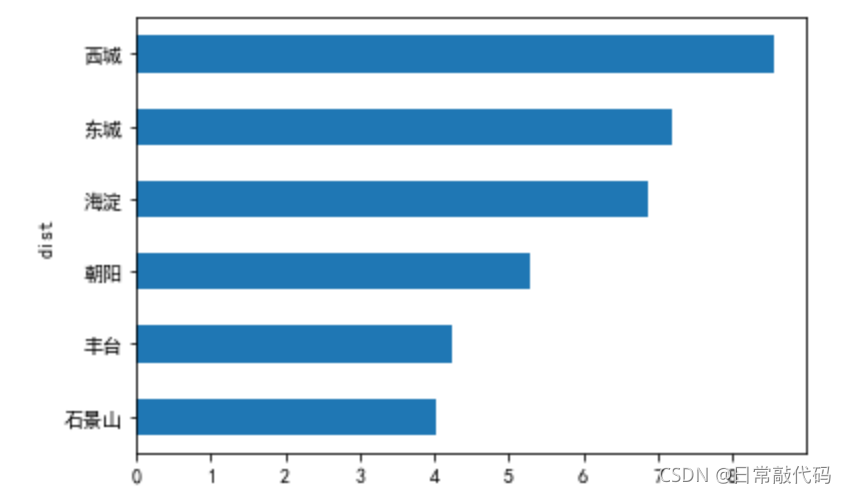
- 方法二:盒须图
dat1 = dat0[['dist','price']]
- 将区转为分类变量
dat1.dist = dat1.dist.astype('category')
- 定义分类变量的顺序,使之为升序排列
dat1.dist.cat.set_categories(['石景山','丰台','朝阳','海淀','东城','西城'],inplace=True)
sns.boxplot(x='dist',y='price',data=dat1)
plt.ylabel('单位面积房价(万元/平方米)')
plt.xlabel('城区')
plt.title('城区对房价的分组箱线图')
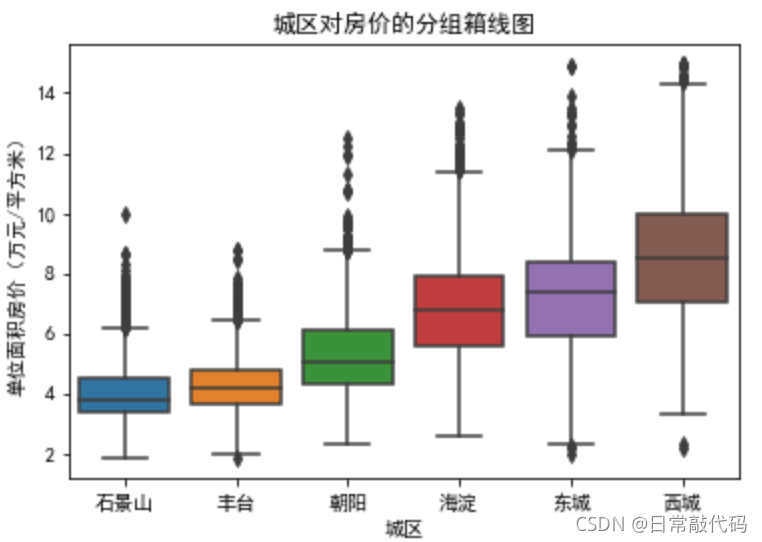
注:
看各区对Y有无影响:主要是看中心水平是否一致,不一致则表示两者是不独立的,那么X对Y有预测作用,可以纳入回归模型。
步骤三:对连续变量(面积)分析
1 房屋面积对价格是否相关
散点图:看是否右偏==》右偏考虑取对数
相关系数:判断相关性
- 散点图呈现左密集右疏散==》右偏函数
datA = dat0[['AREA','price']]
plt.scatter(datA.AREA,datA.price,marker='.')
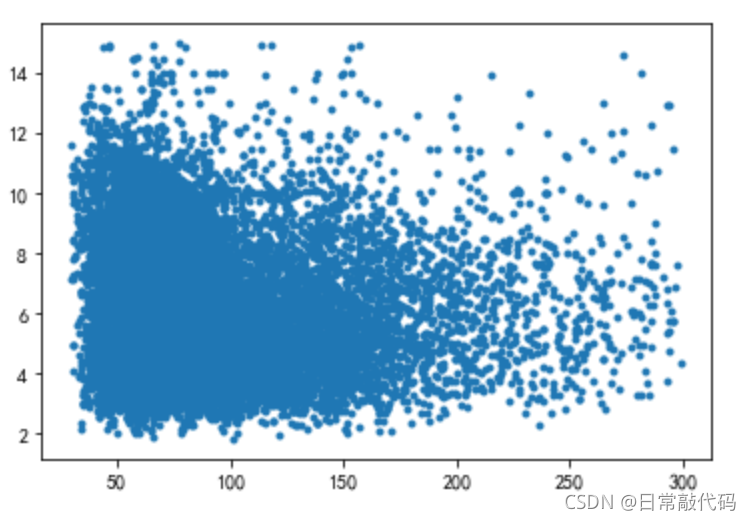
- pearson相关系数
datA[['AREA','price']].corr(method='pearson')

注:相关系数p>0.8是强相关,0.5<p<0.8 : 中度相关,p<0.3 : 弱相关或不相关。
- 作两两变量之间分析的时候,相关系数<0.3,是不考虑的。
- 做建模的时候或多个变量之间分析的时候或逻辑回归、神经网络的时候,相关系数小于0.3,是要考虑的。
2 取对数
2.1对Y取对数
datA['price_ln'] = np.log(datA['price']) # 对Y取对数
plt.figure(figsize=(8,8))
plt.scatter(datA.AREA,datA.price_ln,marker='.')
plt.xlabel('面积(平方米)')
plt.ylabel('单位面积房价(取对数后)')
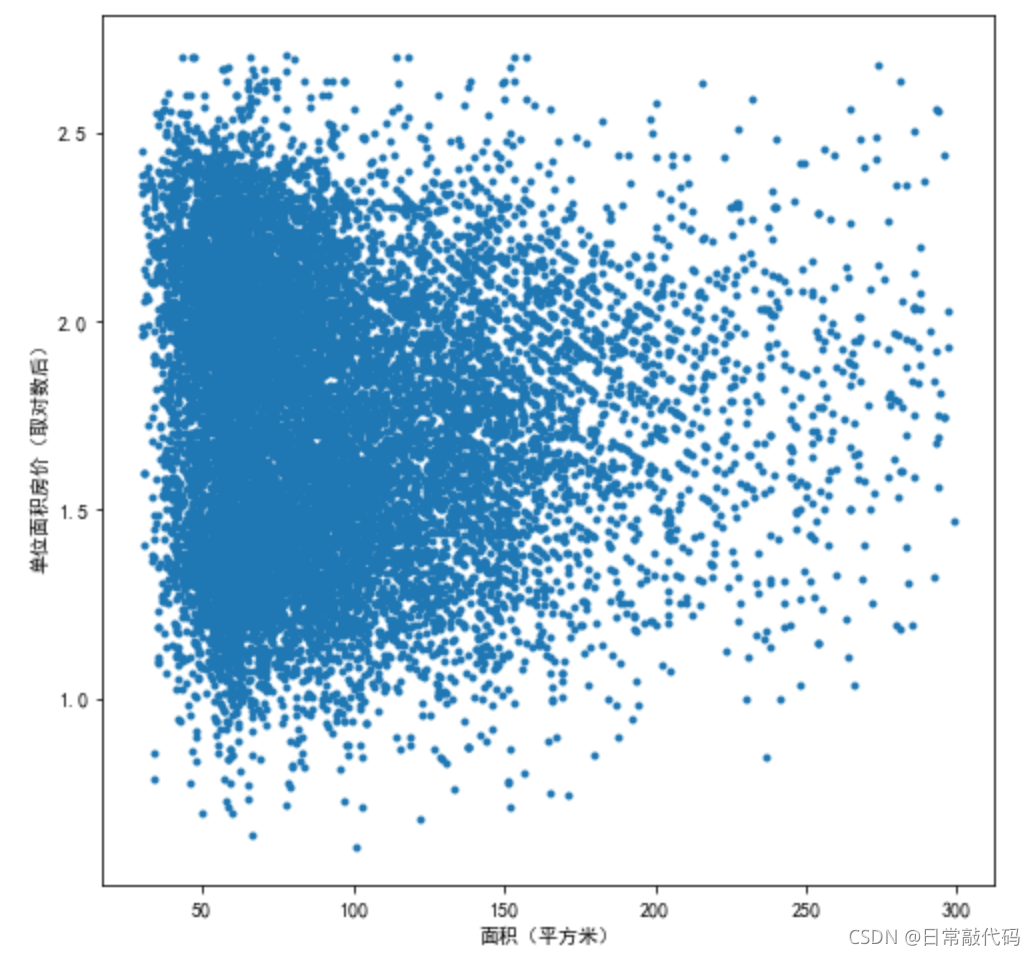
- 相关系数
datA[['AREA','price_ln']].corr(method='pearson')
- 散点图结果类似三角关系,散点结果点仍较密

一般取对数后相关系数应该升高,但是相关系数比未取对数前下降了,考虑对x取对数
2.2 对X、Y取对数
图形为中间密两边疏的状态,这样的图无论是X分布还是Y分布都是正态分布
datA['AREA_ln'] = np.log(datA['AREA'])
datA['price_ln'] = np.log(datA['price'])
plt.figure(figsize=(8,8))
plt.scatter(datA.AREA_ln,datA.price_ln,marker='.')
plt.xlabel('面积(平方米)')
plt.ylabel('单位面积房价(取对数后)')
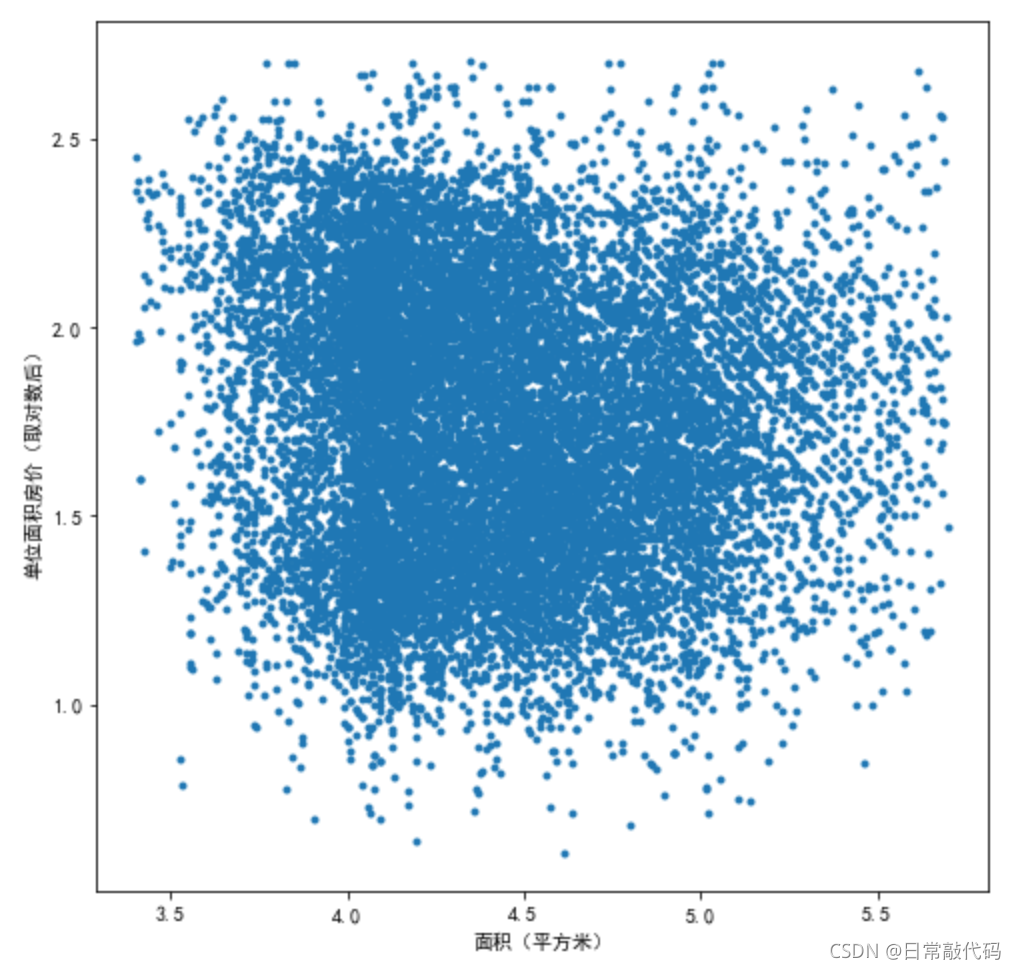
- 相关系数:相关性更高了
datA[['AREA_ln','price_ln']].corr(method='pearson')

根据描述性统计得到认识:房屋面积对房屋价格是有一定影响的。
根据上述结果应该对X、Y都取对数建立模型。
描述性统计分析是选用所有的原始数据进行分析的。
假设检验、数据建模选取部分数据进行分析
3 假设检验
假设检验:针对描述性统计得到的认识进行验证,由于原数据量有16000多条,所以进行抽样选取部分数据。
3.1 抽样
- 抽样代码
def get_sample(df, sampling="simple_random", k=1, stratified_col=None):
"""
对输入的 dataframe 进行抽样的函数
参数:
- df: 输入的数据框 pandas.dataframe 对象
- sampling:抽样方法 str
可选值有 ["simple_random", "stratified", "systematic"]
按顺序分别为: 简单随机抽样、分层抽样、系统抽样
- k: 抽样个数或抽样比例 int or float
(int, 则必须大于0; float, 则必须在区间(0,1)中)
如果 0 < k < 1 , 则 k 表示抽样对于总体的比例
如果 k >= 1 , 则 k 表示抽样的个数;当为分层抽样时,代表每层的样本量
- stratified_col: 需要分层的列名的列表 list
只有在分层抽样时才生效
返回值:
pandas.dataframe 对象, 抽样结果
"""
import random
import pandas as pd
from functools import reduce
import numpy as np
import math
len_df = len(df)
if k <= 0:
raise AssertionError("k不能为负数")
elif k >= 1:
assert isinstance(k, int), "选择抽样个数时, k必须为正整数"
sample_by_n=True
if sampling is "stratified":
alln=k*df.groupby(by=stratified_col)[stratified_col[0]].count().count() # 有问题的
#alln=k*df[stratified_col].value_counts().count()
if alln >= len_df:
raise AssertionError("请确认k乘以层数不能超过总样本量")
else:
sample_by_n=False
if sampling in ("simple_random", "systematic"):
k = math.ceil(len_df * k)
#print(k)
if sampling is "simple_random":
print("使用简单随机抽样")
idx = random.sample(range(len_df), k)
res_df = df.iloc[idx,:].copy()
return res_df
elif sampling is "systematic":
print("使用系统抽样")
step = len_df // k+1 #step=len_df//k-1
start = 0 #start=0
idx = range(len_df)[start::step] #idx=range(len_df+1)[start::step]
res_df = df.iloc[idx,:].copy()
#print("k=%d,step=%d,idx=%d"%(k,step,len(idx)))
return res_df
elif sampling is "stratified":
assert stratified_col is not None, "请传入包含需要分层的列名的列表"
assert all(np.in1d(stratified_col, df.columns)), "请检查输入的列名"
grouped = df.groupby(by=stratified_col)[stratified_col[0]].count()
if sample_by_n==True:
group_k = grouped.map(lambda x:k)
else:
group_k = grouped.map(lambda x: math.ceil(x * k))
res_df = df.head(0)
for df_idx in group_k.index:
df1=df
if len(stratified_col)==1:
df1=df1[df1[stratified_col[0]]==df_idx]
else:
for i in range(len(df_idx)):
df1=df1[df1[stratified_col[i]]==df_idx[i]]
idx = random.sample(range(len(df1)), group_k[df_idx])
group_df = df1.iloc[idx,:].copy()
res_df = res_df.append(group_df)
return res_df
else:
raise AssertionError("sampling is illegal")
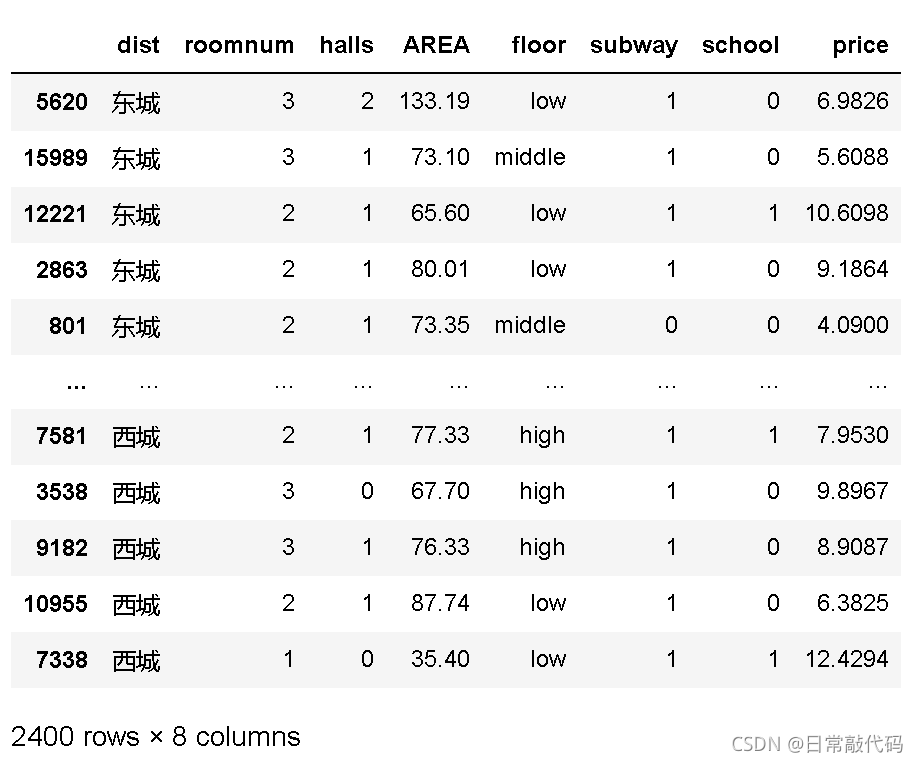
- 分层抽样:按区抽样,每个区抽400个样本
dat01 = get_sample(dat0, sampling="stratified", k=400, stratified_col=['dist'])
dat01
3.2 单变量显著度分析–方差分析
- 因为自变量都是分类变量,因变量为连续变量,所以进行方差分析
import statsmodels.api as sm
from statsmodels.formula.api import ols
print('dist的P值为:.4f'%sm.stats.anova_lm(ols('price~C(dist)',data=dat01).fit())._values[0][4])
print('roomnum的P值为:%.4f'%sm.stats.anova_lm(ols('price~C(roomnum)',data=dat01).fit())._values[0][4])
print("halls的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(halls)',data=dat01).fit())._values[0][4])#高于0.001->边际显著->暂时考虑
print("floor的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(floor)',data=dat01).fit())._values[0][4])#高于0.001->边际显著->暂时考虑
print("subway的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(subway)',data=dat01).fit())._values[0][4])
print("school的P值为:%.4f" %sm.stats.anova_lm(ols('price ~ C(school)',data=dat01).fit())._values[0][4])

由于随机抽样,每次的P值不一样,但结论肯定一致。
3.3 变量编码
变量进行编码方便后续建模。
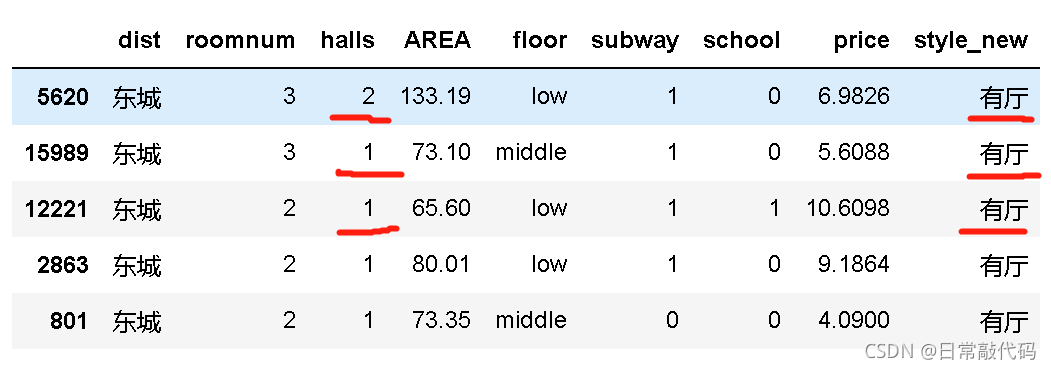
- 二分类变量编码
厅的数量影响不大,对其进行编码,使之变为有无厅(0-1变量),成为二分类变量
dat01['style_new'] = dat01.halls
dat01.style_new[dat01.style_new>0]='有厅'
dat01.style_new[dat01.style_new==0]='无厅'
dat01.head()
2. 多分类变量编码
对于多分类变量:放入模型的时候做一个哑变量编码
- 多变量:城区、楼层
datta = pd.get_dummies(dat01[['dist','floor']])
datta.head()
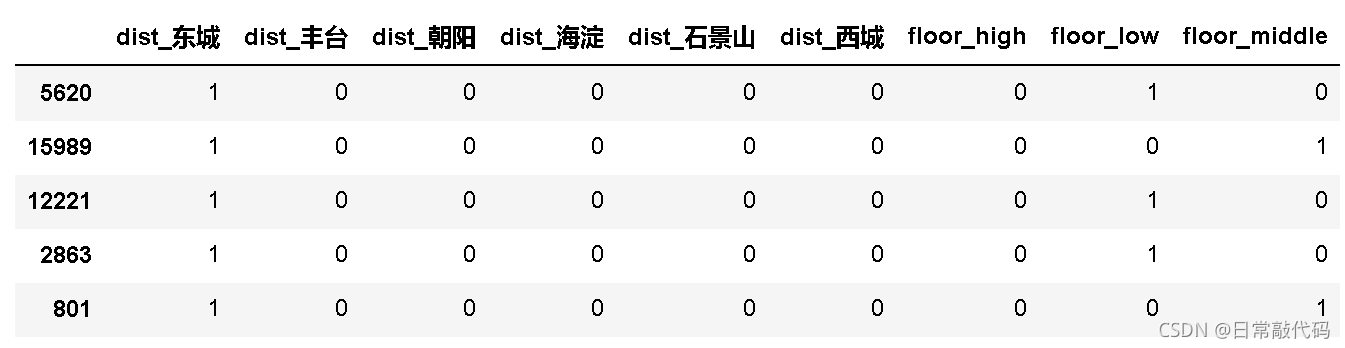
- 这两个是参照组,删去
- 保留K-1个哑变量
datta.drop(['dist_石景山','floor_high'],axis=1,inplace=True)
datta.head()
最后用于建模的数据
- 生成的哑变量与其他所需变量合并成新的数据框
dat1 = pd.concat([datta,dat01[['school','subway','style_new','roomnum','AREA','price']]],axis=1)
dat1.head()
4 建模–线性回归
方案一
- OLS:回归不带截距项的(不常用),ols:是常用的
from statsmodels.formula.api import ols
lm1 = ols('price ~ dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城+school+subway+floor_middle+floor_low+AREA',
data=dat1).fit()
'''
ols的y必须是连续变量,x可以是连续的或者分类的,
若x为分类变量,可以用C()代替建立哑变量
'''
lm1_summary= lm1.summary()
lm1_summary #回归结果显示
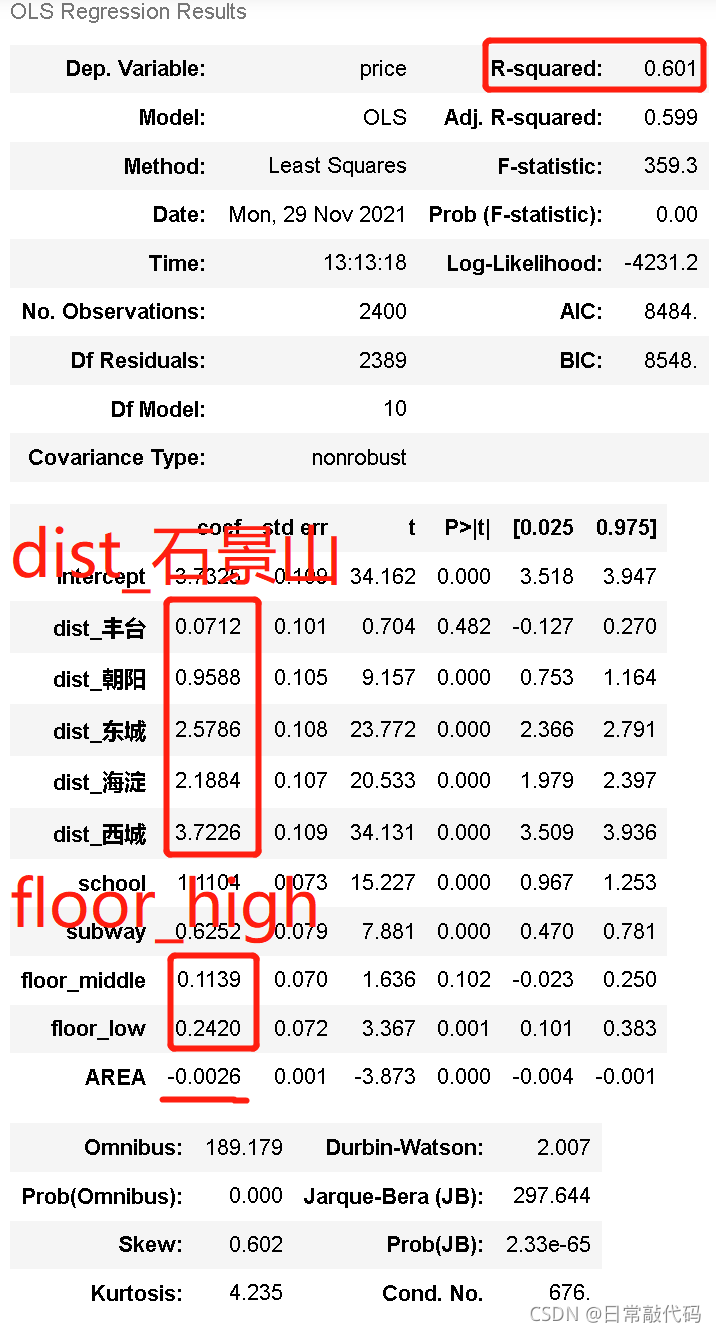
注:城区中每一个值都与石景山相比,楼层每一个值都与高层相比。
- 对模型取预测
dat1['pred1'] = lm1.predict(dat01)
- 取残差
dat1['resid1'] = lm1.resid
- pred1(预测值)为x,resid1(残差)为y,做散点图。
dat1.plot('pred1','resid1',kind='scatter')
'''
异方差:随着预测值的增加,残差在增加
该图为异方差,应对Y取对数
'''
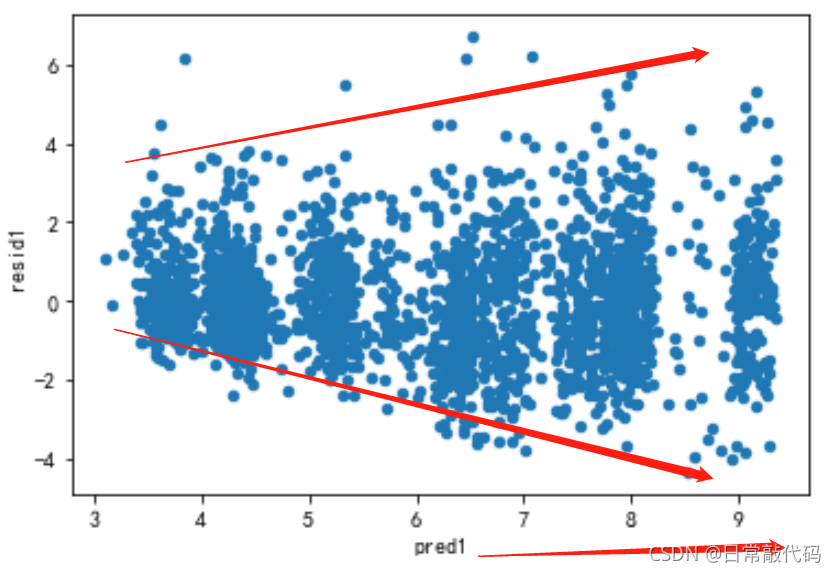
由结果再次证明,散点图为异方差,所以对模型取对数。
方案二:对X、Y取对数
dat1['price_ln'] = np.log(dat1['price']) # y值取对数
dat1['AREA_ln'] = np.log(dat1['AREA']) # x取对数
lm2 = ols("price_ln ~ dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城+school+subway+floor_middle+floor_low+AREA_ln", data=dat1).fit()
lm2_summary = lm2.summary()
lm2_summary #回归结果展示
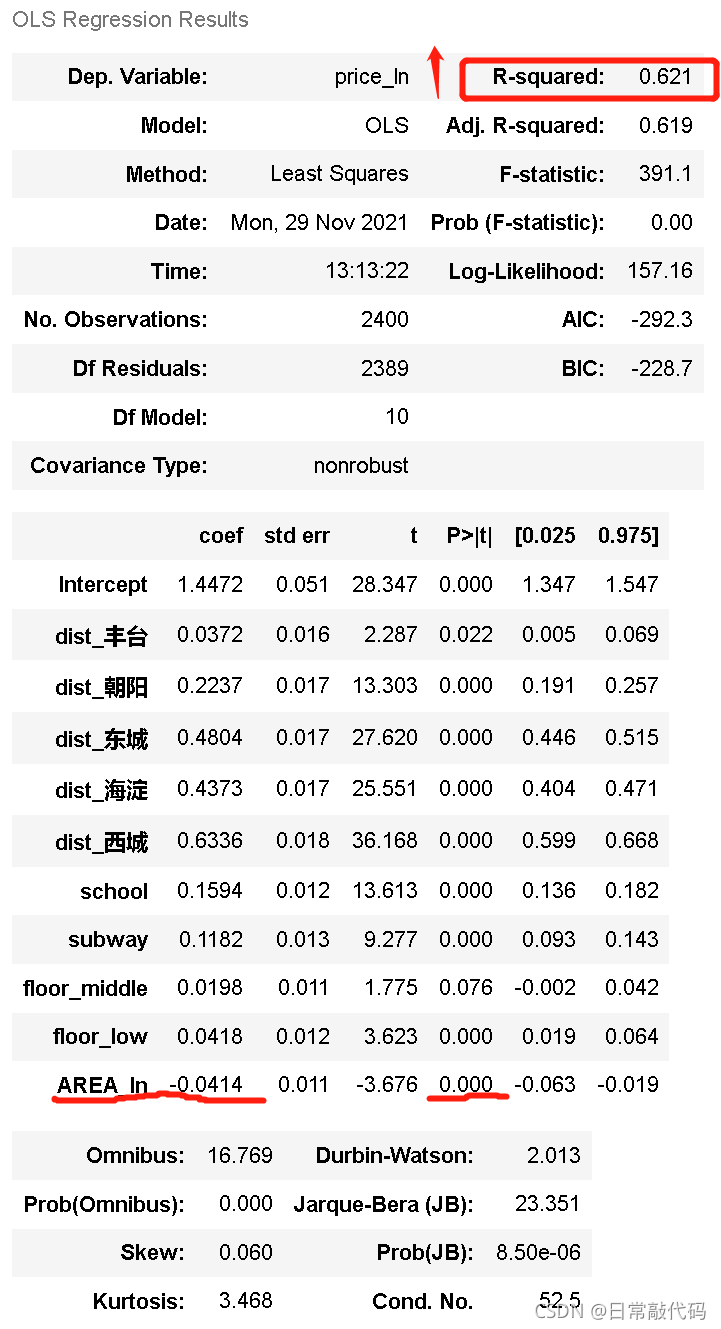
模型解释:取对数之后,变为百分比
丰台区的房价比石景山的房价贵3.72%,学区房比非学区房贵15.9%,低层房比高层房贵4.18%,房屋面积每增加一个百分比,房屋的价格回下降4.14个百分比。
五、预测
1 交互项
x1、x2作为交互项的形式(x1*x2)放入模型在不同的地方影响的斜率不同,考虑交互项
是否按区分、是否学区房、是否临近地铁三个变量是显著的,所以这三个变量的交互项是应该被考虑的。其他变量不显著,不用考虑。
1.1 描述性统计–城区和学区房的交互项
- 构造图形揭示不同城区是否学区房的价格问题
df=pd.DataFrame()
dist=['石景山','丰台','朝阳','东城','海淀','西城']
Noschool=[]
school=[]
for i in dist:
Noschool.append(dat0[(dat0['dist']==i)&(dat0['school']==0)]['price'].mean())
school.append(dat0[(dat0['dist']==i)&(dat0['school']==1)]['price'].mean())
df['dist']=pd.Series(dist)
df['Noschool']=pd.Series(Noschool)
df['school']=pd.Series(school)
df
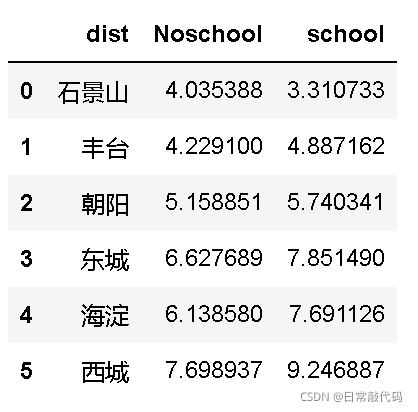
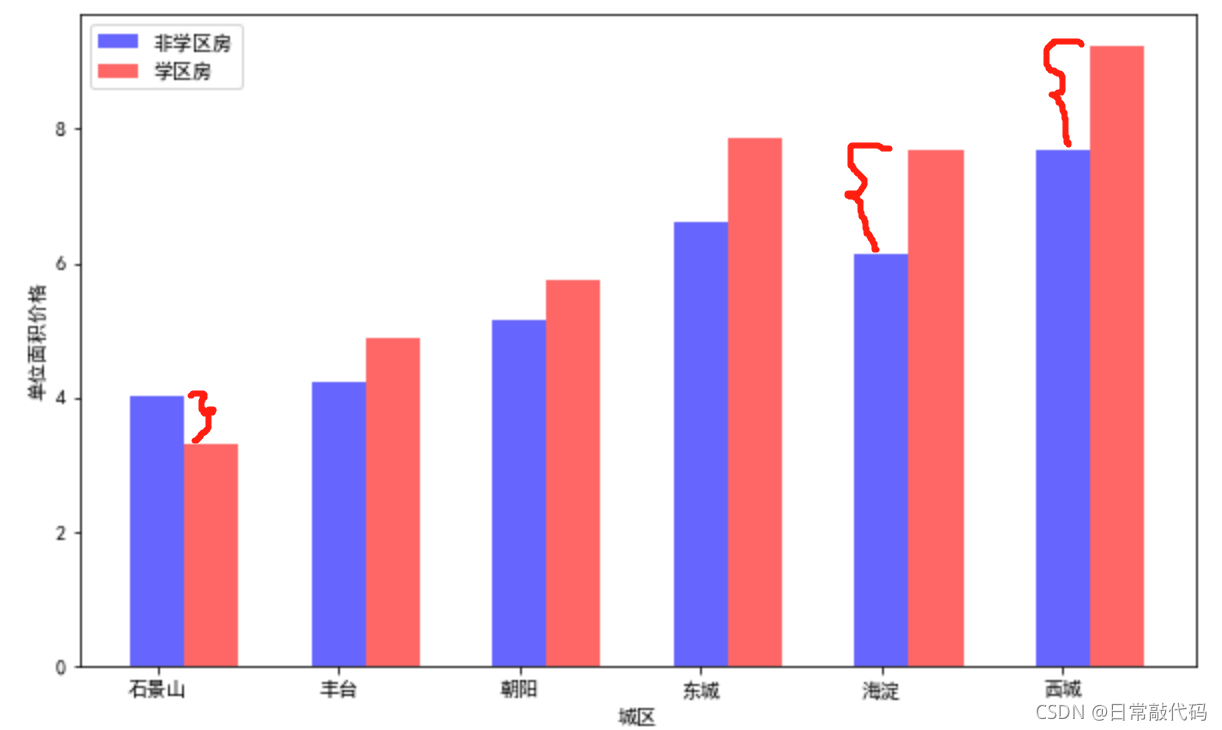
#描述性统计
df1 = df['Noschool'].T.values
df2 = df['school'].T.values
plt.figure(figsize=(10,6))
x1 = range(0,len(df))
x2=[i+0.3 for i in x1]
plt.bar(x1,df1,color='b',width=0.3,alpha=0.6,label='非学区房')
plt.bar(x2,df2,color='r',width=0.3,alpha=0.6,label='学区房')
plt.xlabel('城区')
plt.ylabel('单位面积价格')
plt.legend(loc='upper left')
plt.xticks(range(0,6),dist)
plt.show()
1.2 分类盒须图
- 分城区的学区房分组箱线图
school=['石景山','丰台','朝阳','东城','海淀','西城']
for i in school:
dat0[dat0.dist==i][['school','price']].boxplot(by='school',patch_artist=True)
plt.xlabel(i+'学区房')
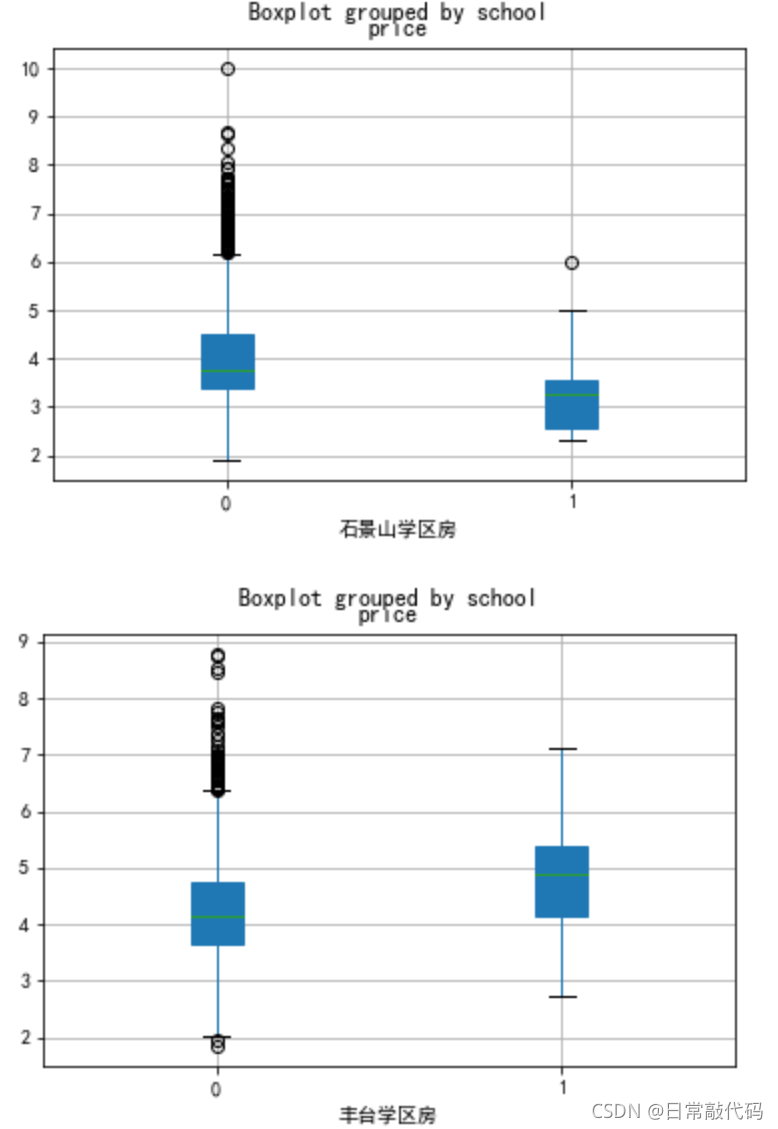 图1 图1
|
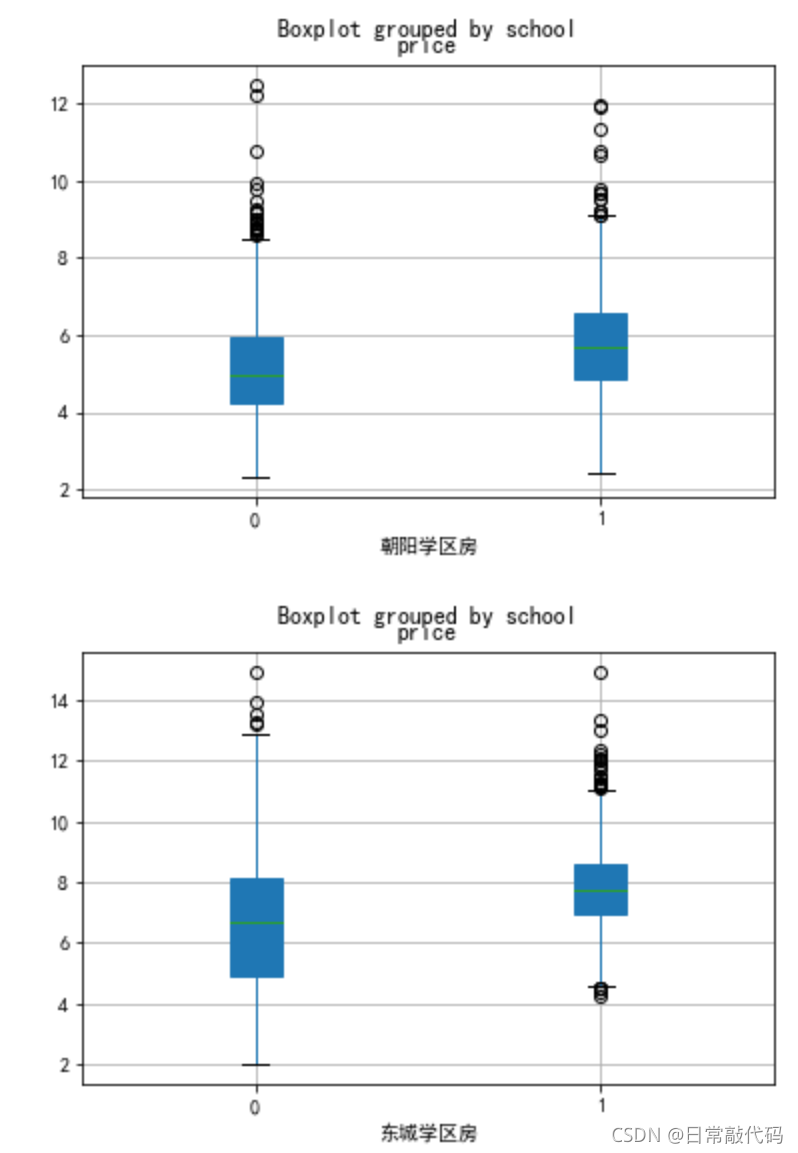 图2 图2
|
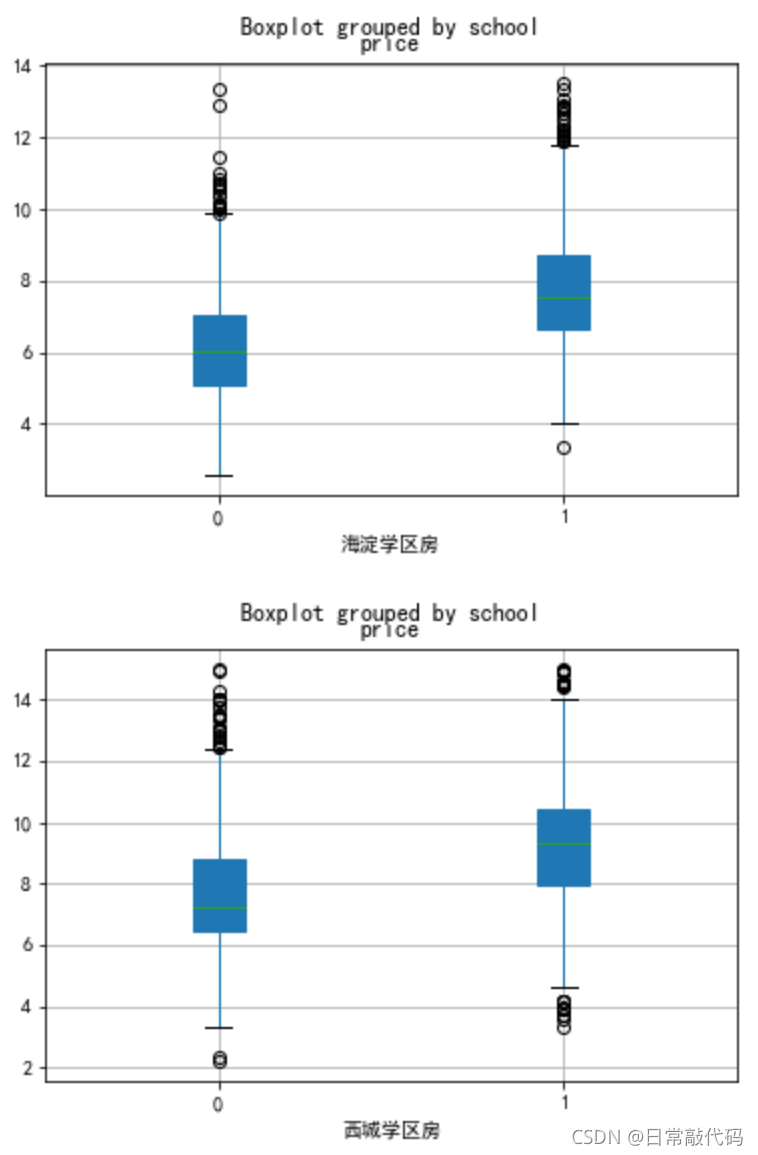 图3 图3
|
- 盒须图:各个城区是否有学区房对防区价格的影响,
看均值(中心水平)是否一致。 - 交互项:各个城区是否有学区房对防区价格的影响,
看各城区均值的差值是否一致
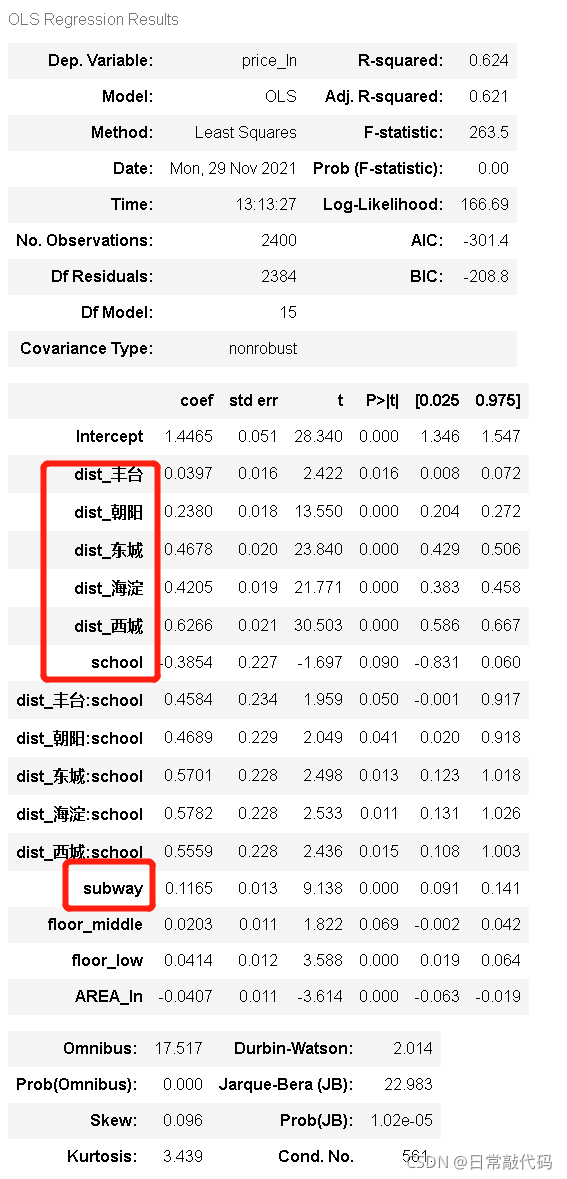
1.3 建立模型
- 放入模型看P值,判断是否显著。
- 有交互项的对数线性模型,城区和学区之间的交互作用
lm3 = ols("price_ln ~ (dist_丰台+dist_朝阳+dist_东城+dist_海淀+dist_西城)*school+subway+floor_middle+floor_low+AREA_ln", data=dat1).fit()
lm3_summary = lm3.summary()
lm3_summary #回归结果展示
模型解释:
基准点是石景山的学区房,石景山的学区房要比非学区房价格便宜。所以石景山学区房比非学区房便宜38.54%。丰台区的学区房比非学区房涨45.84%


















 3551
3551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









