









在前端想要对于字符串进行提取或者校验,不可避免使用正则表达式。
现在记录使用JavaScipt的正则表达式的过程。
提示:以下正则代码内容如果看不懂,可以到这个链接去学下不懂的地方,直接在页面中ctrl+f搜对应不懂的知识点即可。
大神很详细的js正则表达式基础教程
- 有一个需求,需要提取一个字符串中指定的多个内容。这个字符串是关于个人简介的。
字符串"姓名张三性别男出生年月(岁)1972.01(49岁)家庭主要成员及重要社会关系 称 谓 姓 名 出生日期 政 治 面 貌 工 作 单 位 及 职 务 妻子 ",
提取他的姓名“张三”、他的性别:“男”、他的出生年月(岁):“1972.01(49岁)”。
可以看出提取时,“张三”夹在“姓名”、“性别”这两个词语之间,所以想当然可以用正则去提取这两个固定词语之间的内容即为他的真实名字。
先用个小demo举个例子,
<script>
var str = '姓名张三性别男'
var regName = /姓名(.+)性别/
console.log("测试1:",regName.exec(str))
console.log("测试2:",regName.exec(str)[1])
</script>
输出如下:

解释:
根据regName,在str字符串中提取了子字符串,这个子字符串是类似于"姓名"开头,“性别”结尾,中间夹着任意长度大于1的字符串的字符串。
测试1返回结果是一个数组,数组第1个元素是[“姓名张三性别”]是找到的子字符串,第2个是[“张三”]是分组(.*)中的内容。
所以我们在测试2中,直接取数组的第2个元素,返回的结果就是[张三]。
好的,现在正式取一下。
<script>
var str = '姓名张三性别男出生年月(岁)1972.01(49岁)家庭主要成员及重要社会关系 称 谓 姓 名 出生日期 政 治 性别 面 貌 工 作 单 位 及 职 务'
console.log("去除前:",str)
str = str.replace(/\s/g,"")//去除字符串中的空白符
console.log("去除空字符后:",str)
var regName = /姓名(.+)性别/ //在.+ 两边带上(),充当分组,主要是想获取分组中的值,即为真实姓名 张三
console.log("测试:",regName.exec(str))
</script>

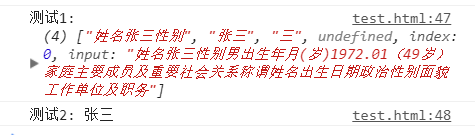
我们本来期望分组中出现,“张三”,但是出现的却是:“张三性别男出生年月(岁)1972.01(49岁)家庭主要成员及重要社会关系称谓姓名出生日期政治”。

原因是,整个字符串有两个“性别”,而我们这样regName = /姓名(.+)性别/
匹配的规则自然会把第一个“性别”当做(.+)中的,把第2个“性别”才当做regName中的“性别”。
所以我们要做的,就是不允许中出现“性别”即可。
代码如下:
<script>
var str = '姓名张三性别男出生年月(岁)1972.01(49岁)家庭主要成员及重要社会关系 称 谓 姓 名 出生日期 政 治 性别 面 貌 工 作 单 位 及 职 务'
console.log("去除前:",str)
str = str.replace(/\s/g,"")//去除字符串中的空白符
console.log("去除空字符后:",str)
var regName = /姓名(((?!性别).)*)性别/
console.log("测试1:",regName.exec(str))
console.log("测试2:",regName.exec(str)[1])
</script>
“?!”用法(引用上述链接解释):
(?!exp) 这个就是说字符出现的位置的右边缝隙不能是exp这个表达式。
var str = 'nodejs';
var reg = /node(?!js)/;
console.log(reg.test(str)) // false
姓名(?!性别) 意味着“姓名”的右侧不能是“性别”的0到多个字符串组成。
大佬的具体解释
一个字符串是由n个字符组成的。在每个字符之前和之后,都有一个空字符。这样,一个由n个字符组成的字符串就有n+1个空字符串。我们来看一下“ABhedeCD”这个字符串:
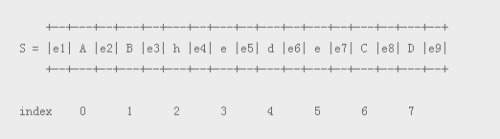
所有的e编号的位置都是空字符。表达式(?!hede).会往前查找,看看前面是不是没有“hede”字串,如果没有(是其它字符),那么.(点号)就会匹配这些其它字符。这种正则表达式的“查找”也叫做“zero-width-assertions”(零宽度断言),因为它不会捕获任何的字符,只是判断。
在上面的例子里,每个空字符都会检查其前面的字符串是否不是‘hede’,如果不是,这.(点号)就是匹配捕捉这个字符。表达式(?!hede).只执行一次,所以,我们将这个表达式用括号包裹成组(group),然后用*(星号)修饰——匹配0次或多次:
((?!hede).)*
你可以理解,正则表达式((?!hede).)*匹配字符串"ABhedeCD"的结果false,因为在e3位置,(?!hede)匹配不合格,它之前有"hede"字符串,也就是包含了指定的字符串。
在正则表达式里, ?! 是否定式向前查找,它帮我们解决了字符串“不包含”匹配的问题。
综上,把其封装成方法:
<script>
/**
* @param {string} str 去除空白符的word字符串
* @param {string} former 提取字符串前的子字符串(取前2个字)
* @param {string} latter 提取字符串后的子字符串(取后2个字)
* 比如:在字符串“姓名张三性别”中, 提取“张三”这个字符串
* “姓名张三性别”是str
* "姓名"是former
* "性别"是latter
*/
function wordStringExtract(str,former,latter){
var reg = new RegExp(former+'(((?!(?:'+former+')|(?:'+latter+')).)*)'+latter)
var pro = reg.exec(str)[1]
return pro
}
var str = '姓名张三性别男出生年月(岁)1972.01(49岁)家庭主要成员及重要社会关系 称 谓 姓 名 出生日期 政 治 性别 面 貌 工 作 单 位 及 职 务';
str = str.replace(/\s/g,"")//去除字符串中的空白符
console.log(wordStringExtract(str,"姓名","性别"))//提取姓名"张三"
</script>



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









