







 本文介绍了ControlNet如何通过额外输入控制扩散模型生成,解决AI绘画的随机性问题,重点讲解了其在构图和风格控制中的应用,以及openpose_full的基本操作和参数设置。
本文介绍了ControlNet如何通过额外输入控制扩散模型生成,解决AI绘画的随机性问题,重点讲解了其在构图和风格控制中的应用,以及openpose_full的基本操作和参数设置。
本文专门开一节写提示词相关的内容,在看之前,可以同步关注:
stable diffusion实践操作
文章目录
前言
为什么ControlNet 会引发如此大的轰动呢?
因为在这之前,基于扩散模型的AI绘画是非常难以控制的,去扩散这张图片的过程充满随机性,如果只是使用它来自娱自乐,那这种随机性并不会给你带来很大的困扰,画出来的内容和你预想中的有一点偏差也可以让自己接受,但是一些面对具体需求的图片就很难了,如果只能依赖抽卡式的反复尝试来得到你想要的东西,那么肯定不行。
ControlNet就初步解决了这中问题,它的定位是对大模型做微调的网络。
控制网的核心作用是基于一些额外输入给它的信息来给扩散模型的生成提供明确的指引。
比如姿势,面部表情。
本章主要参考B站视频:
视频入口:入口
1、ControlNet是什么?
通俗点来说,如果要画一幅画,一方面是构图,一方面是风格。之前大家都听说过现在AI绘画就是炼丹对吧?其实炼的是什么呢?说白了还是通过各种咒语来控制画面的构图和风格。
大家应该也知道这个咒语很烦是吧?其实这种所谓咒语在我看来就是反人类的,AI本来就应该是降低门槛而不是抬高门槛的,随着AI技术这日新月异的发展,这种咒语未来肯定是被淘汰掉的。其实现在已经有了两大利器,就是来解决这个问题的:ControlNet就是用来控制构图的,LoRA就是用来控制风格的 。不过针对这句话有一点补充:ControlNet框架太厉害了,感觉逐渐会无所不能;目前已经出了一个很厉害的风格迁移的模型shuffle,后文会详细介绍。
那ControlNet是怎么控制构图呢?技术原理我就不介绍了,简单来说,就是你手上已经有一副图了,基于这个图你去创造出新的图。那么这个图有两种来源:
1、你很有才,你自己画了一幅手稿图。但是后期修图太费劲,你想交给AI去做后面的美化的事情;
2、你不是那么有才(譬如我),然后正好手边有那么一幅现成的图,想照着那个样子去改改。
那么这就是ControlNet做的事情:通过你手上已有的图而不是咒语,实现对AI绘图的控制。
可能你比较细致,会追着问,不是总体有两步么,那我是不是还得学习LoRA来学习控制风格啊?嗯,LoRA么,有最好,没有的话,现在的一些基础大模型也够用了(毕竟只用SD1.5也是能生成一些不错的图的,只是不好控制而已),不妨碍我们只用ControlNet就可以画出非常好的效果。你可以理解为LoRA是锦上添花。
2.常用的模型

3.基本操作 openpose_full
1.提示词
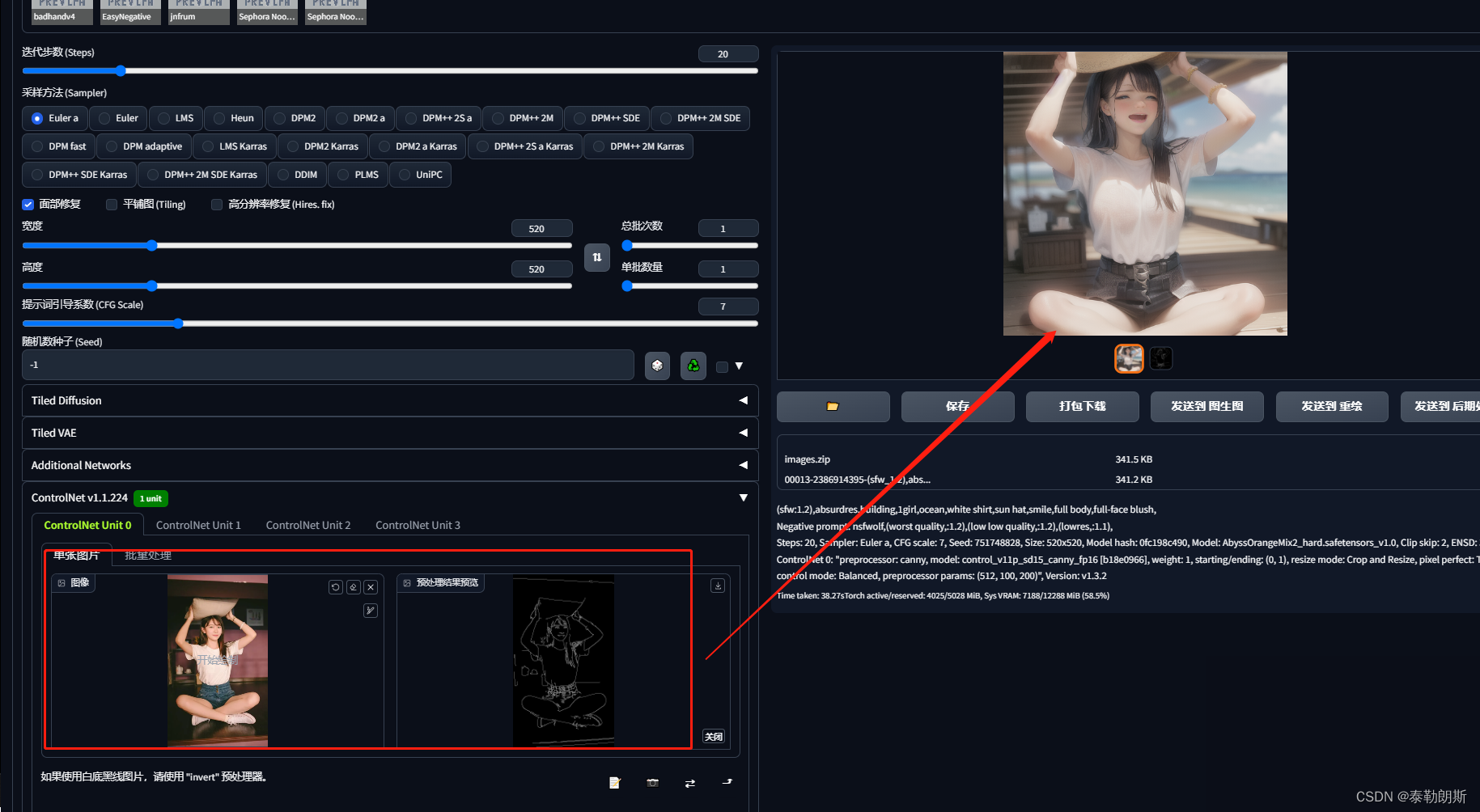
正向提示词
(sfw:1.2),absurdres,1girl,ocean,white shirt,sun hat,smile,full body,
反向提示词
nsfwolf,(worst quality,:1.2),(low low quality,:1.2),(lowres,:1.1),EasyNegative badhandv4,
ControlNet设置
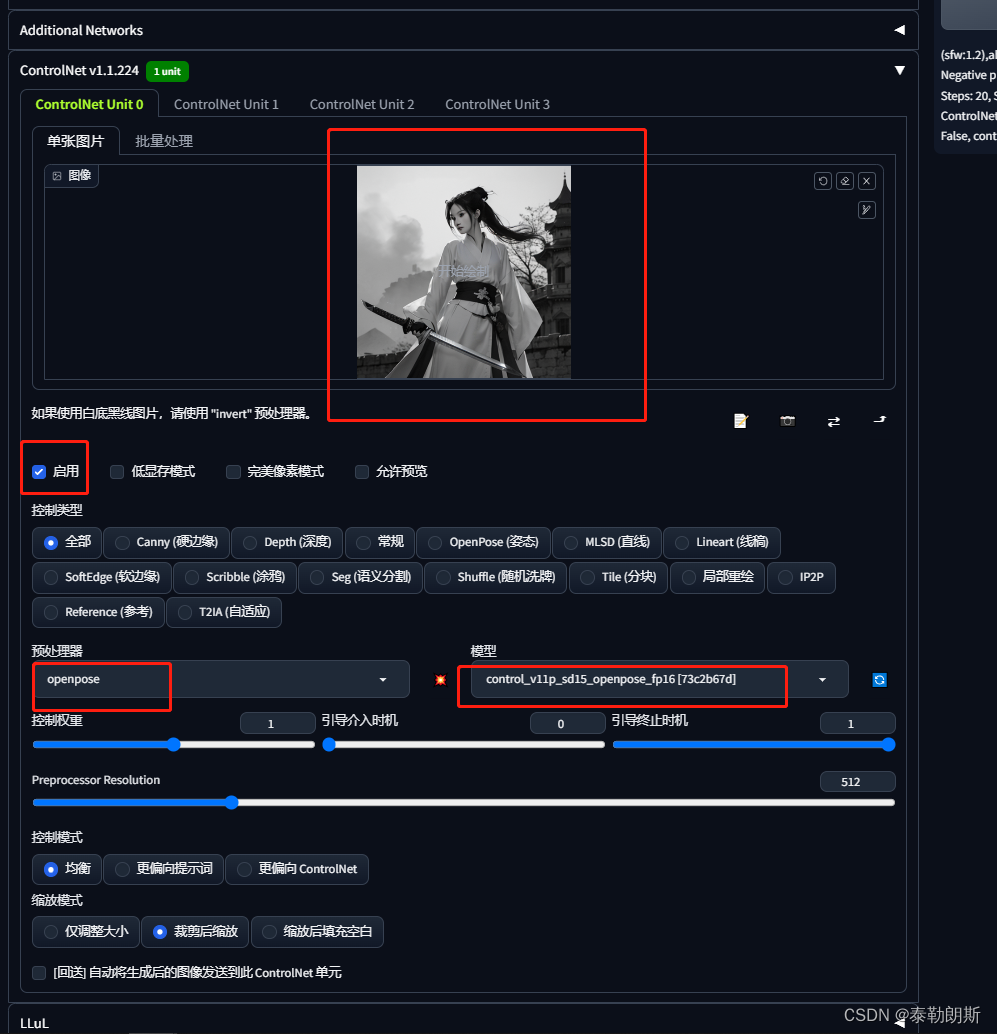
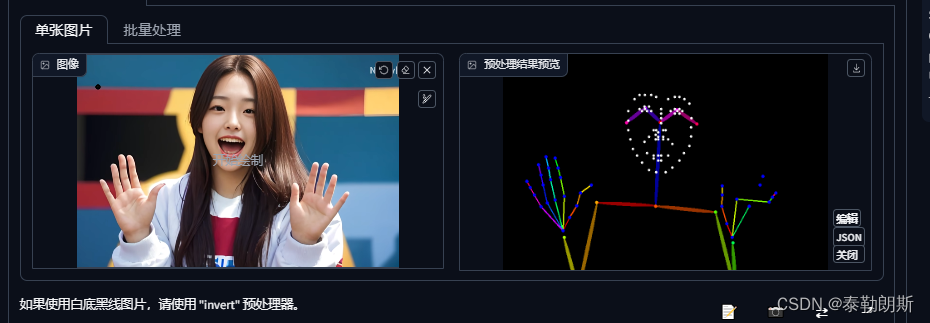
生成结果,可是看到,姿势被完全控制了

2.参数-控制效果参数

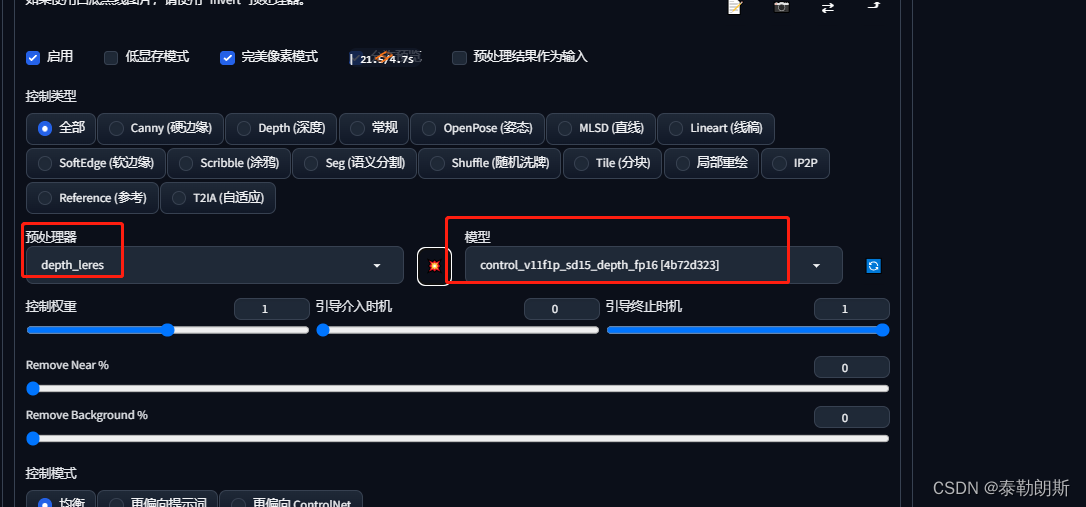
4.基本操作 depth场景的描绘还原 人物 + 场景
预处理器和模型必须一致

5. Caning 边缘检测算法-
黑色是背景,白色是线条
6.soft edge 和Canny类似
7.scribble 涂鸦
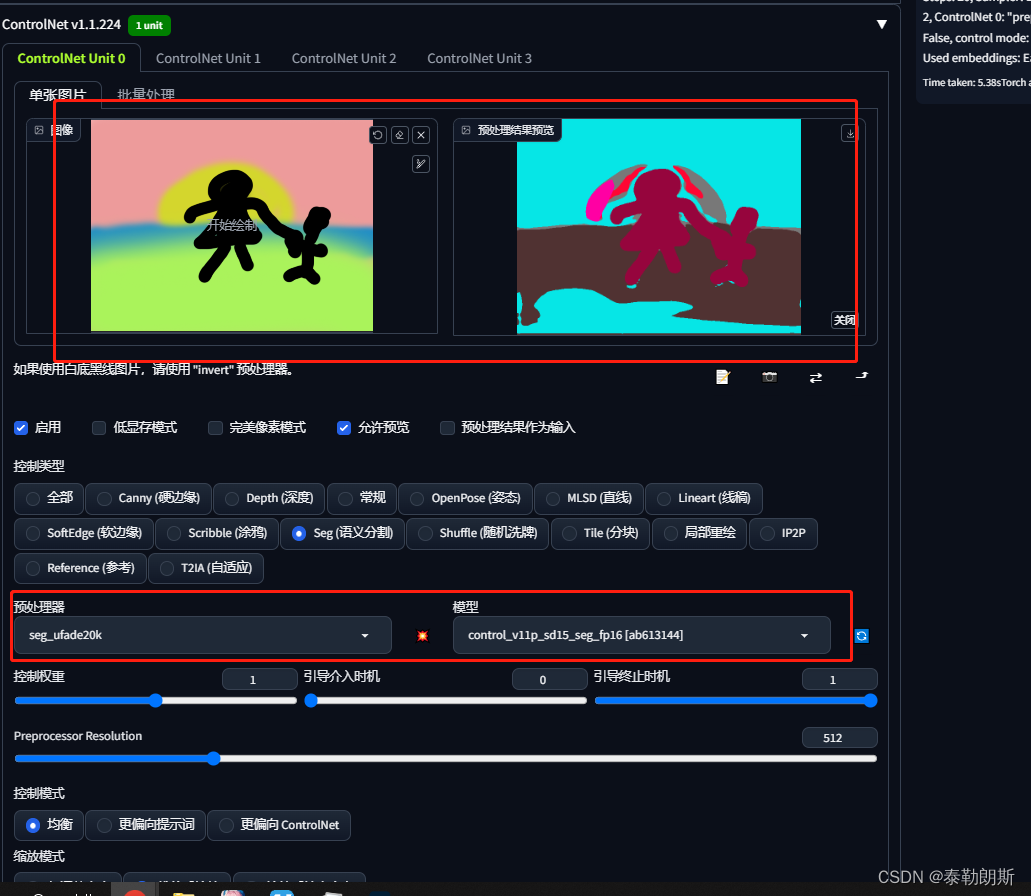

4.多重控制网络
多个模型一起控制使用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









