









所有assignment相关链接:
Coursera | Applied Machine Learning in Python(University of Michigan)| Assignment1
Coursera | Applied Machine Learning in Python(University of Michigan)| Assignment2
Coursera | Applied Machine Learning in Python(University of Michigan)| Assignment3
Coursera | Applied Machine Learning in Python(University of Michigan)| Assignment4
有时间(需求)就把所有代码放到github上
嘿,顺便推广下自己的博客,以后CSDN的文章都会放到自己的博客的。
Coursera | Applied Machine Learning in Python(University of Michigan)| Assignment2
You are currently looking at version 1.3 of this notebook. To download notebooks and datafiles, as well as get help on Jupyter notebooks in the Coursera platform, visit the Jupyter Notebook FAQ course resource.
Assignment 2
In this assignment you’ll explore the relationship between model complexity and generalization performance, by adjusting key parameters of various supervised learning models. Part 1 of this assignment will look at regression and Part 2 will look at classification.
Part 1 - Regression
First, run the following block to set up the variables needed for later sections.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
np.random.seed(0)
n = 15
x = np.linspace(0, 10, n) + np.random.randn(n) / 5
y = np.sin(x) + x / 6 + np.random.randn(n) / 10
X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=0)
# You can use this function to help you visualize the dataset by
# plotting a scatterplot of the data points
# in the training and test sets.
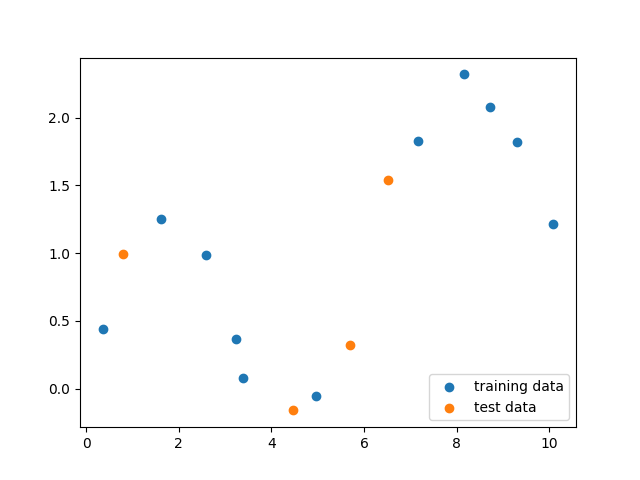
def part1_scatter():
import matplotlib.pyplot as plt
% matplotlib notebook
plt.figure()
plt.scatter(X_train, y_train, label='training data')
plt.scatter(X_test, y_test, label='test data')
plt.legend(loc=4)
# NOTE: Uncomment the function below to visualize the data, but be sure
# to **re-comment it before submitting this assignment to the autograder**.
part1_scatter()
Question 1
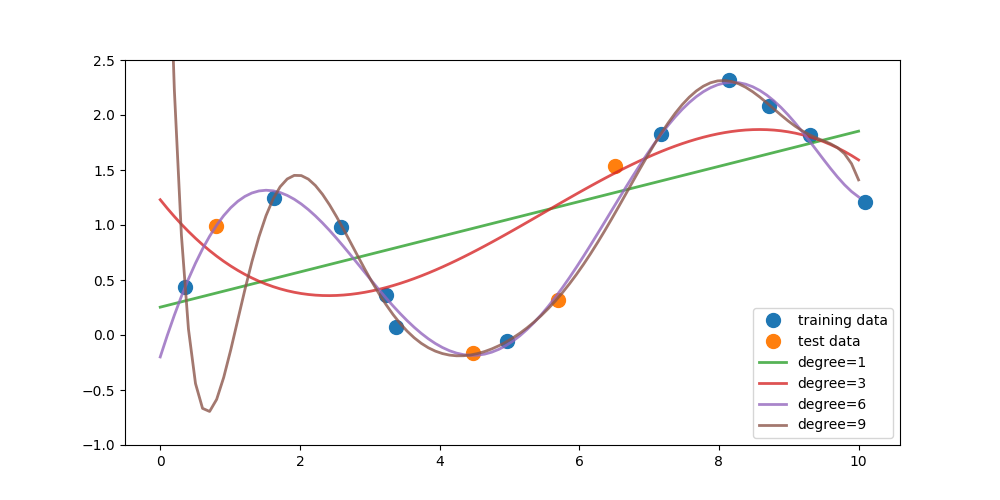
Write a function that fits a polynomial LinearRegression model on the training data X_train for degrees 1, 3, 6, and 9. (Use PolynomialFeatures in sklearn.preprocessing to create the polynomial features and then fit a linear regression model) For each model, find 100 predicted values over the interval x = 0 to 10 (e.g. np.linspace(0,10,100)) and store this in a numpy array. The first row of this array should correspond to the output from the model trained on degree 1, the second row degree 3, the third row degree 6, and the fourth row degree 9.

The figure above shows the fitted models plotted on top of the original data (using plot_one()).
*This function should return a numpy array with shape `(4, 100)`*
def answer_one():
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
result = np.zeros((4, 100))
test = np.linspace(0, 10, 100)
for i, degree in enumerate([1, 3, 6, 9]):
poly = PolynomialFeatures(degree=degree)
X_poly = poly.fit_transform(X_train.reshape(len(X_train), 1))
linreg = LinearRegression().fit(X_poly, y_train)
y = linreg.predict(poly.fit_transform(test.reshape(len(test), 1)))
result[i, :] = y
return result
# feel free to use the function plot_one() to replicate the figure
# from the prompt once you have completed question one
def plot_one(degree_predictions):
import matplotlib.pyplot as plt
%matplotlib notebook
plt.figure(figsize=(10, 5))
plt.plot(X_train, y_train, 'o', label='training data', markersize=10)
plt.plot(X_test, y_test, 'o', label='test data', markersize=10)
for i, degree in enumerate([1, 3, 6, 9]):
plt.plot(np.linspace(0, 10, 100),
degree_predictions[i],
alpha=0.8,
lw=2,
label='degree={}'.format(degree))
plt.ylim(-1, 2.5)
plt.legend(loc=4)
plot_one(answer_one())
Question 2
Write a function that fits a polynomial LinearRegression model on the training data X_train for degrees 0 through 9. For each model compute the
R
2
R^2
R2 (coefficient of determination) regression score on the training data as well as the the test data, and return both of these arrays in a tuple.
This function should return one tuple of numpy arrays (r2_train, r2_test). Both arrays should have shape (10,)
def answer_two():
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics.regression import r2_score
r2_test = np.zeros(10)
r2_train = np.zeros(10)
for degree in range(10):
#train polynomial linear regression
poly = PolynomialFeatures(degree=degree)
X_train_poly = poly.fit_transform(X_train.reshape(len(X_train), 1))
linreg = LinearRegression().fit(X_train_poly, y_train)
#evaluate the polynomial linear regression
r2_train[degree] = linreg.score(X_train_poly, y_train)
X_test_poly = poly.fit_transform(X_test.reshape(len(X_test), 1))
r2_test[degree] = linreg.score(X_test_poly, y_test)
return (r2_train, r2_test)
answer_two()
(array([0. , 0.42924578, 0.4510998 , 0.58719954, 0.91941945,
0.97578641, 0.99018233, 0.99352509, 0.99637545, 0.99803706]),
array([-0.47808642, -0.45237104, -0.06856984, 0.00533105, 0.73004943,
0.87708301, 0.9214094 , 0.92021504, 0.63247942, -0.64525453]))
Question 3
Based on the R 2 R^2 R2 scores from question 2 (degree levels 0 through 9), what degree level corresponds to a model that is underfitting? What degree level corresponds to a model that is overfitting? What choice of degree level would provide a model with good generalization performance on this dataset? Note: there may be multiple correct solutions to this question.
(Hint: Try plotting the R 2 R^2 R2 scores from question 2 to visualize the relationship between degree level and R 2 R^2 R2)
This function should return one tuple with the degree values in this order: (Underfitting, Overfitting, Good_Generalization)
def plot_answer_three():
import matplotlib.pyplot as plt
r2_train, r2_test = answer_two()
degrees = np.arange(0, 10)
plt.figure()
plt.plot(degrees, r2_train, degrees, r2_test)
plot_answer_three()
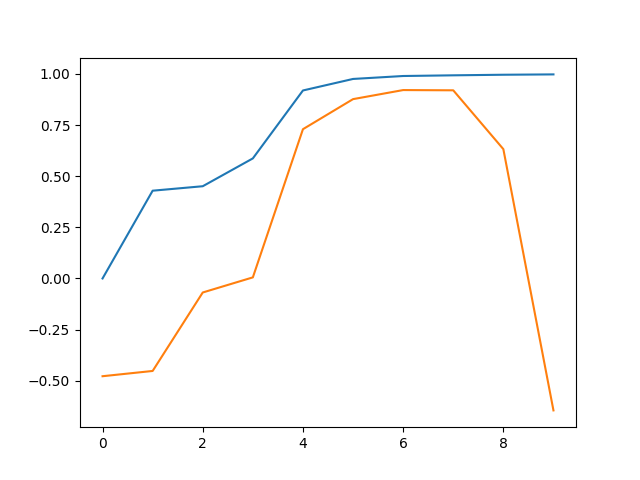
def answer_three():
Underfitting, Overfitting, Good_Generalization = 0, 9, 7
return (Underfitting, Overfitting, Good_Generalization)
answer_three()
(0, 9, 7)
Question 4
Training models on high degree polynomial features can result in overly complex models that overfit, so we often use regularized versions of the model to constrain model complexity, as we saw with Ridge and Lasso linear regression.
For this question, train two models: a non-regularized LinearRegression model (default parameters) and a regularized Lasso Regression model (with parameters alpha=0.01, max_iter=10000) on polynomial features of degree 12. Return the
R
2
R^2
R2 score for both the LinearRegression and Lasso model’s test sets.
This function should return one tuple (LinearRegression_R2_test_score, Lasso_R2_test_score)
def answer_four():
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import Lasso, LinearRegression
from sklearn.metrics.regression import r2_score
poly = PolynomialFeatures(12)
X_poly = poly.fit_transform(X_train.reshape(len(X_train), 1))
X_test_poly = poly.fit_transform(X_test.reshape(len(X_test), 1))
linreg = LinearRegression().fit(X_poly, y_train)
LinearRegression_R2_test_score = linreg.score(X_test_poly, y_test)
linlasso = Lasso(alpha=0.01, max_iter=10000).fit(X_poly, y_train)
Lasso_R2_test_score = linlasso.score(X_test_poly, y_test)
return (LinearRegression_R2_test_score, Lasso_R2_test_score)
answer_four()
(-4.311988870193713, 0.8406625614749974)
Part 2 - Classification
Here’s an application of machine learning that could save your life! For this section of the assignment we will be working with the UCI Mushroom Data Set stored in mushrooms.csv. The data will be used to train a model to predict whether or not a mushroom is poisonous. The following attributes are provided:
Attribute Information:
- cap-shape: bell=b, conical=c, convex=x, flat=f, knobbed=k, sunken=s
- cap-surface: fibrous=f, grooves=g, scaly=y, smooth=s
- cap-color: brown=n, buff=b, cinnamon=c, gray=g, green=r, pink=p, purple=u, red=e, white=w, yellow=y
- bruises?: bruises=t, no=f
- odor: almond=a, anise=l, creosote=c, fishy=y, foul=f, musty=m, none=n, pungent=p, spicy=s
- gill-attachment: attached=a, descending=d, free=f, notched=n
- gill-spacing: close=c, crowded=w, distant=d
- gill-size: broad=b, narrow=n
- gill-color: black=k, brown=n, buff=b, chocolate=h, gray=g, green=r, orange=o, pink=p, purple=u, red=e, white=w, yellow=y
- stalk-shape: enlarging=e, tapering=t
- stalk-root: bulbous=b, club=c, cup=u, equal=e, rhizomorphs=z, rooted=r, missing=?
- stalk-surface-above-ring: fibrous=f, scaly=y, silky=k, smooth=s
- stalk-surface-below-ring: fibrous=f, scaly=y, silky=k, smooth=s
- stalk-color-above-ring: brown=n, buff=b, cinnamon=c, gray=g, orange=o, pink=p, red=e, white=w, yellow=y
- stalk-color-below-ring: brown=n, buff=b, cinnamon=c, gray=g, orange=o, pink=p, red=e, white=w, yellow=y
- veil-type: partial=p, universal=u
- veil-color: brown=n, orange=o, white=w, yellow=y
- ring-number: none=n, one=o, two=t
- ring-type: cobwebby=c, evanescent=e, flaring=f, large=l, none=n, pendant=p, sheathing=s, zone=z
- spore-print-color: black=k, brown=n, buff=b, chocolate=h, green=r, orange=o, purple=u, white=w, yellow=y
- population: abundant=a, clustered=c, numerous=n, scattered=s, several=v, solitary=y
- habitat: grasses=g, leaves=l, meadows=m, paths=p, urban=u, waste=w, woods=d
The data in the mushrooms dataset is currently encoded with strings. These values will need to be encoded to numeric to work with sklearn. We’ll use pd.get_dummies to convert the categorical variables into indicator variables.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
mush_df = pd.read_csv('mushrooms.csv')
mush_df2 = pd.get_dummies(mush_df)
X_mush = mush_df2.iloc[:, 2:]
y_mush = mush_df2.iloc[:, 1]
# use the variables X_train2, y_train2 for Question 5
X_train2, X_test2, y_train2, y_test2 = train_test_split(X_mush,
y_mush,
random_state=0)
# For performance reasons in Questions 6 and 7, we will create a smaller version of the
# entire mushroom dataset for use in those questions. For simplicity we'll just re-use
# the 25% test split created above as the representative subset.
#
# Use the variables X_subset, y_subset for Questions 6 and 7.
X_subset = X_test2
y_subset = y_test2
Question 5
Using X_train2 and y_train2 from the preceeding cell, train a DecisionTreeClassifier with default parameters and random_state=0. What are the 5 most important features found by the decision tree?
As a reminder, the feature names are available in the X_train2.columns property, and the order of the features in X_train2.columns matches the order of the feature importance values in the classifier’s feature_importances_ property.
This function should return a list of length 5 containing the feature names in descending order of importance.
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0).fit(X_train2, y_train2)
features = []
clf.feature_importances_.argsort()[::-1][:5]
array([ 27, 53, 55, 100, 25], dtype=int32)
def answer_five():
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0).fit(X_train2, y_train2)
features = []
ind = clf.feature_importances_.argsort()[::-1][:5]
return X_train2.columns[ind].tolist()
answer_five()
['odor_n', 'stalk-root_c', 'stalk-root_r', 'spore-print-color_r', 'odor_l']
Question 6
For this question, we’re going to use the validation_curve function in sklearn.model_selection to determine training and test scores for a Support Vector Classifier (SVC) with varying parameter values. Recall that the validation_curve function, in addition to taking an initialized unfitted classifier object, takes a dataset as input and does its own internal train-test splits to compute results.
Because creating a validation curve requires fitting multiple models, for performance reasons this question will use just a subset of the original mushroom dataset: please use the variables X_subset and y_subset as input to the validation curve function (instead of X_mush and y_mush) to reduce computation time.
The initialized unfitted classifier object we’ll be using is a Support Vector Classifier with radial basis kernel. So your first step is to create an SVC object with default parameters (i.e. kernel='rbf', C=1) and random_state=0. Recall that the kernel width of the RBF kernel is controlled using the gamma parameter.
With this classifier, and the dataset in X_subset, y_subset, explore the effect of gamma on classifier accuracy by using the validation_curve function to find the training and test scores for 6 values of gamma from 0.0001 to 10 (i.e. np.logspace(-4,1,6)). Recall that you can specify what scoring metric you want validation_curve to use by setting the “scoring” parameter. In this case, we want to use “accuracy” as the scoring metric.
For each level of gamma, validation_curve will fit 3 models on different subsets of the data, returning two 6x3 (6 levels of gamma x 3 fits per level) arrays of the scores for the training and test sets.
Find the mean score across the three models for each level of gamma for both arrays, creating two arrays of length 6, and return a tuple with the two arrays.
e.g.
if one of your array of scores is
array([[ 0.5, 0.4, 0.6],
[ 0.7, 0.8, 0.7],
[ 0.9, 0.8, 0.8],
[ 0.8, 0.7, 0.8],
[ 0.7, 0.6, 0.6],
[ 0.4, 0.6, 0.5]])
it should then become
array([ 0.5, 0.73333333, 0.83333333, 0.76666667, 0.63333333, 0.5])
This function should return one tuple of numpy arrays (training_scores, test_scores) where each array in the tuple has shape (6,).
def answer_six():
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
svc = SVC(kernel='rbf', C=1, random_state=0)
train_scores, test_scores = validation_curve(svc,
X_subset,
y_subset,
param_name='gamma',
param_range=np.logspace(
-4, 1, 6),
scoring='accuracy',
cv=3)
train_mscores = train_scores.mean(axis=1)
test_mscores = test_scores.mean(axis=1)
return (train_mscores, test_mscores)
answer_six()
(array([0.56646972, 0.93106844, 0.990645 , 1. , 1. ,
1. ]),
array([0.56720827, 0.9300837 , 0.98966027, 1. , 0.99458395,
0.52240276]))
Question 7
Based on the scores from question 6, what gamma value corresponds to a model that is underfitting (and has the worst test set accuracy)? What gamma value corresponds to a model that is overfitting (and has the worst test set accuracy)? What choice of gamma would be the best choice for a model with good generalization performance on this dataset (high accuracy on both training and test set)? Note: there may be multiple correct solutions to this question.
(Hint: Try plotting the scores from question 6 to visualize the relationship between gamma and accuracy.)
This function should return one tuple with the degree values in this order: (Underfitting, Overfitting, Good_Generalization)
train_scores, test_scores = answer_six()
def plot_answer_seven():
import matplotlib.pyplot as plt
gamma = np.logspace(-4, 1, 6)
plt.figure()
plt.plot(gamma, train_scores, 'b--.', label='train_scores')
plt.plot(gamma, test_scores, 'g-*', label='test_scores')
plt.legend()
plot_answer_seven()
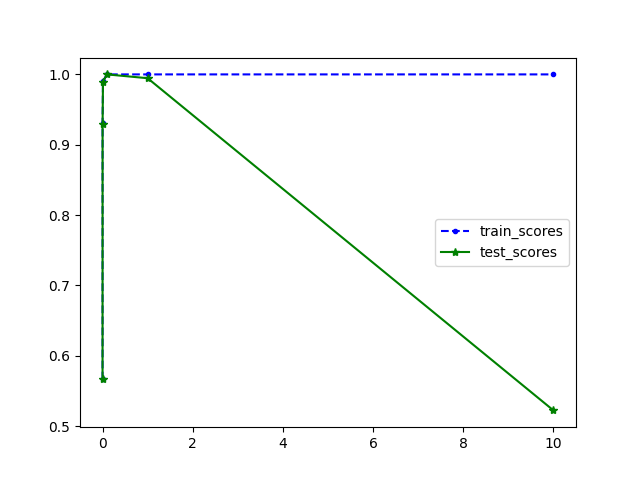
def answer_seven():
param_range = np.logspace(-4, 1, 6)
Underfitting, Overfitting, Good_Generalization = param_range[
0], param_range[5], param_range[3]
return (Underfitting, Overfitting, Good_Generalization)
answer_seven()
(0.0001, 10.0, 0.1)















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









