






今天我们来聊一下如何用协程来进行数据的抓取,协程又称为是微线程,也被称为是用户级线程,在单线程的情况下完成多任务,多个任务按照一定顺序交替执行。
那么aiohttp模块在Python中作为异步的HTTP客户端/服务端框架,是基于asyncio的异步模块,可以用于实现异步爬虫,更快于requests的同步爬虫。下面我们就通过一个具体的案例来看一下该模块到底是如何实现异步爬虫的。
发起请求
我们先来看一下发起请求的部分,代码如下
async def fetch(url, session):
try:
async with session.get(url, headers=headers, verify_ssl=False) as resp:
if resp.status in [200, 201]:
logger.info("请求成功")
data = await resp.text()
return data
except Exception as e:
print(e)
logger.warning(e)要是返回的状态码是200或者是201,则获取响应内容,下一步我们便是对响应内容的解析
响应内容解析
这里用到的是PyQuery模块来对响应的内容进行解析,代码如下
def extract_elements(source):
try:
dom = etree.HTML(source)
id = dom.xpath('......')[0]
title = dom.xpath('......')[0]
price = dom.xpath('.......')[0]
information = dict(re.compile('.......').findall(source))
information.update(title=title, price=price, url=id)
print(information)
asyncio.ensure_future(save_to_database(information, pool=pool))
except Exception as e:
print('解析详情页出错!')
logger.warning('解析详情页出错!')
pass最后则是将解析出来的内容存入至数据库当中
数据存储
这里用到的是aiomysql模块,使用异步IO的方式保存数据到Mysql当中,要是不存在对应的数据表,我们则创建对应的表格,代码如下
async def save_to_database(information, pool):
COLstr = '' # 列的字段
ROWstr = '' # 行字段
ColumnStyle = ' VARCHAR(255)'
if len(information.keys()) == 14:
for key in information.keys():
COLstr = COLstr + ' ' + key + ColumnStyle + ','
ROWstr = (ROWstr + '"%s"' + ',') % (information[key])
async with pool.acquire() as conn:
async with conn.cursor() as cur:
try:
await cur.execute("SELECT * FROM %s" % (TABLE_NAME))
await cur.execute("INSERT INTO %s VALUES (%s)" % (TABLE_NAME, ROWstr[:-1]))
except aiomysql.Error as e:
await cur.execute("CREATE TABLE %s (%s)" % (TABLE_NAME, COLstr[:-1]))
await cur.execute("INSERT INTO %s VALUES (%s)" % (TABLE_NAME, ROWstr[:-1]))
except aiomysql.Error as e:
pass项目的启动
最后我们来看一下项目启动的代码,如下
async def consumer():
async with aiohttp.ClientSession() as session:
while not stop:
if len(urls) != 0:
_url = urls.pop()
source = await fetch(_url, session)
extract_links(source)
if len(links_detail) == 0:
print('目前没有待爬取的链接')
await asyncio.sleep(np.random.randint(5, 10))
continue
link = links_detail.pop()
if link not in crawled_links_detail:
asyncio.ensure_future(handle_elements(link, session))我们通过调用ensure_future方法来安排协程的进行
async def handle_elements(link, session):
print('开始获取: {}'.format(link))
source = await fetch(link, session)
# 添加到已爬取的集合中
crawled_links_detail.add(link)
extract_elements(source)数据分析与可视化
下面我们针对抓取到的数据进行进一步的分析与可视化,数据源是关于上海的二手房的相关信息,我们先来看一下房屋户型的分布,代码如下
house_size_dict = {}
for house_size, num in zip(df["房屋户型"].value_counts().head(10).index, df["房屋户型"].value_counts().head(10).tolist()):
house_size_dict[house_size] = num
print(house_size_dict)
house_size_keys_list = [key for key, values in house_size_dict.items()]
house_size_values_list = [values for key, values in house_size_dict.items()]
p = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add("", [list(z) for z in zip(house_size_keys_list, house_size_values_list)],
radius=["35%", "58%"],
center=["58%", "42%"])
.set_global_opts(title_opts=opts.TitleOpts(title="房屋面积大小的区间", pos_left="40%"),
legend_opts=opts.LegendOpts(orient="vertical",
pos_top="15%",
pos_left="10%"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
p.render("house_size.html")output
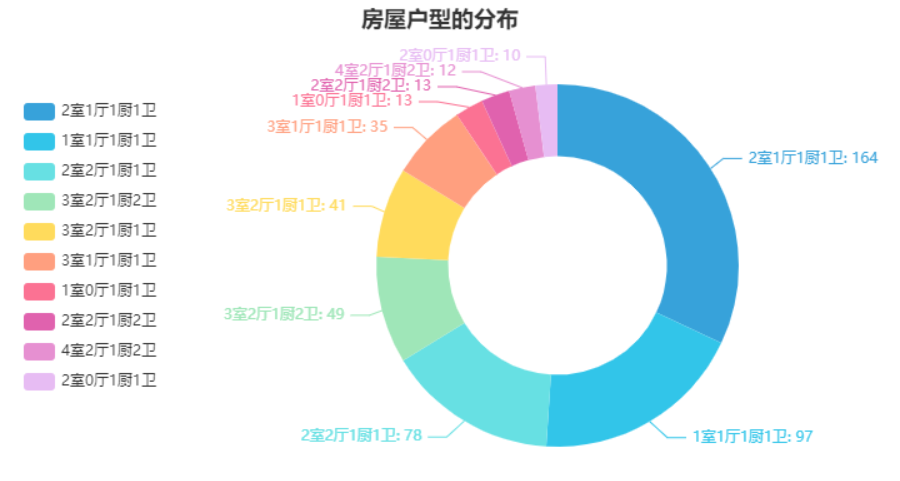
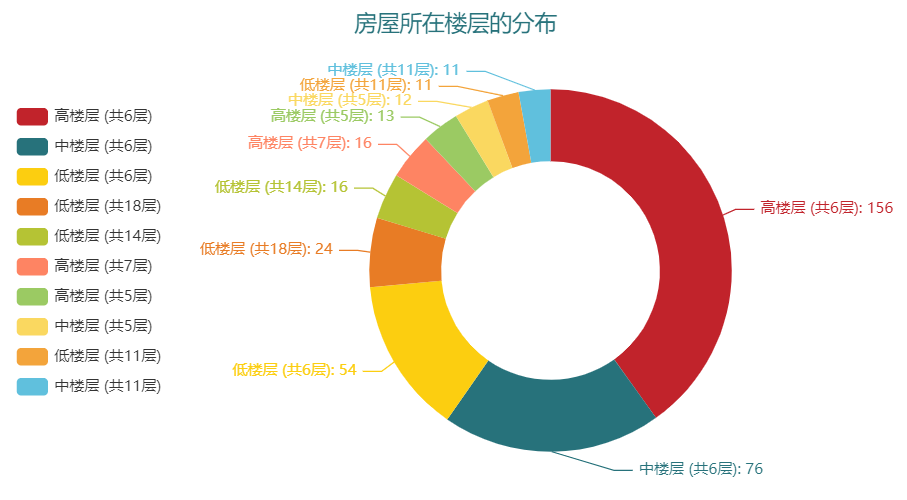
我们可以看到占到大多数的都是“2室1厅1厨1卫”的户型,其次便是“1室1厅1厨1卫”的户型,可见上海二手房交易的市场卖的小户型为主。而他们的所在楼层,大多也是在高楼层(共6层)的为主,如下图所示
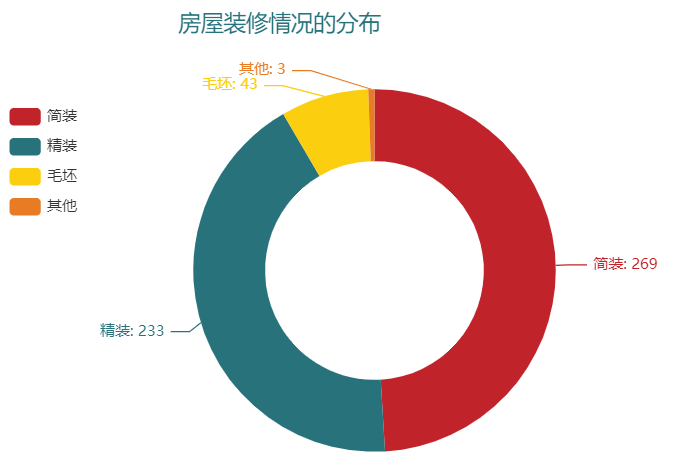
我们再来看一下房屋的装修情况,市场上的二手房大多都是以“简装”或者是“精装”为主,很少会看到“毛坯”的存在,具体如下图所示
至此,我们就暂时先说到这里,本篇文章主要是通过异步协程的方式来进行数据的抓取,相比较于常规的requests数据抓取而言,速度会更快一些。当然由于数据采集本身的合规性问题,代码并没有全部的公开,想要源代码的童鞋也可以后台私信小编来获取。
NO.1
往期推荐
Historical articles
【干货原创】厉害了,在Pandas中用SQL来查询数据,效率超高
分享、收藏、点赞、在看安排一下?



















 4144
4144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









