









本文内容
一、前言
最近在看《C++ Concurrency In Action 2nd》,发现里面有一节基于锁来实现高并发队列讲解的非常棒,并且里面体现了很多细节,而且还给出了一些实现高并发数据结构的指导方针,因此觉得很不错,在此就边翻译边讲解一下。
本教程从比较粗糙的设计开始,一步一步转向更精细的设计,因此,最后的设计才是相对来说最好的版本。
开始前先给出书中关于实现高并发数据结构的指导方针,这个指导方针包含两方面,第一方面是如何确保并发的安全性,第二方面是如何尽可能的使代码有更多的并发机会,即尽可能的细粒度化锁。
- 确保并发安全性的指导方针:
- 确保其他线程无法看到本线程修改数据结构的中间过程。也就是说如果某个函数中的某一部分正在修改数据结构,则要确保在修改的过程中,其他线程无法对此数据结构进行任何访问("访问"这个术语同时包含了读取和写入的概念);
- 通过把一些分开的接口合并成一个接口,从而消除接口间固有的条件竞争。比如栈的
pop()和top(),分开实现的话,就会存在接口间固有的条件竞争,因此对于并发的版本,就应该将其合并为一个函数; - 注意,当操作过程中出现异常时,要确在保异常发生后,本数据结构的中的数据还是完整的,并没有出现数据丢失或者损坏的情况,即要保证并发过程中的“异常安全”。比如当你从栈中弹出一个元素时,假如在元素从函数传递到外面的过程中出现异常,而此时此元素又已经从栈中弹出来了,那么此异常的出现就会导致刚刚弹出的这个数据丢失。此时应该先将栈中的元素给复制出来,然后再将数据弹出来,下面的例子中都有体现;
- 在最小化锁的粒度时,要尽量避免死锁,同时尽量避免锁的嵌套;
- 创建细粒度化锁的一些提问:
- 在锁的保护范围内的一些操作可以移到锁的保护区域外面吗?比如一些关于IO操作或者资源申请及释放操作(如动态内存的申请或释放,等)都是耗时的操作,一般情况下这些耗时操作应该尽量避免放在锁的区域内部;
- 数据结构中不同部分的操作可以使用不同的锁来保护吗?使用单个锁来保护的话,会比较容易实现,且比较安全。但是,使用单个锁的话,粒度就会比较粗,可能并发性能就相对没那么高;
- 所有的操作都需要同等级别的保护吗?
- 可以在不改变操作语义的情况下通过简单的修改数据结构来提高并发性能吗?
二、线程安全的队列的实现
1. 使用锁和条件变量来实现线程安全的队列
如果让你实现一个简单的线程安全的队列,你首先可能会想到什么?应该是会想到直接对标准库中的std::queue<>进行包装吧?这是最简单的实现:
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue() = default;
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one();
}
// 将top和pop合二为一,解决接口的固有条件竞争
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
value = std::move(data_queue.front()); // 注意这里是先将值拿出来,在将队列中的值给删除,这样如果这里move出现异常,则这个值仍然在队列里,没有丢失
data_queue.pop();
}
// 同上,另一种重载形式
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
std::shared_ptr<T> res(std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return false;
value = std::move(data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if(data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res(std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
上面的实现几乎是线程安全的,可以满足指导方针第一条中的1,2,4。比如在弹出内部队列std::queue<>中的元素之前,先将元素拷贝出来,然后再弹出。不过,其中有一点异常安全相关的问题。由于唤醒操作是用的notify_one(),因此同一时刻只能唤醒一个等待中的wait_and_pop()。假如被唤醒的这个wait_and_pop()在执行过程中发生异常(比如新的std::shared_ptr<>被构造的时候出现异常),则此线程就可能退出,而其他等待中的线程在没有收到后续的notify_one()前就无法被唤醒。这里有三种解决方法:
- 使用
notify_all(),这会唤醒所有线程,只不过当他们被唤醒后又发现队列为空的时候,他们又会休眠,这样比较耗时; - 当
wait_and_pop()抛出异常时,在异常处理函数里面再加一条notify_one(),从而唤醒其他等待中的线程; - 直接将数据存储为
std::shared_ptr,然后将std::shared_ptr存储到std::queue<>中,因为这样在wait_and_pop()中就不需要创建新的std::shared_ptr对象了,所以就不会有异常了。
下面是基于第三种方案的实现:
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T>> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue() = default;
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = std::move(*data_queue.front()); // 注意这里是先将值拿出来,在将队列中的值给删除,这样如果这里move出现异常,则这个值仍然在队列里,没有丢失
data_queue.pop();
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return false;
value = std::move(*data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res = data_queue.front();
data_queue.pop();
return res;
}
void push(T new_value)
{
std::shared_ptr<T> data(std::make_shared<T>(std::move(new_value)));
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
使用std::shared_ptr还有一个好处,就是资源创建的过程移到了锁的区域之外。在push()函数中,在锁的区域外创建的std::shared_ptr对象(涉及到动态内存申请,十分耗时),这样使得程序持有锁的时间变短,因此提高了代码的并发性(持有锁的时间越短,则程序的并发性越高)。
此时,我们再深入的思考一下上面代码的并发性能。由于我们使用的是标准库中的std::queue来存储数据,因此我们无法控制数据的内部存储过程,这就导致在std::queue存储数据或读取数据过程中,其他线程只能干等。
那有木有方法来更进一步的提高并发性能呢?有,那就是自己来实现数据的存储和读取过程,不使用标准库的std::queue。这样,我们就可以有更多自由度来设计我们的锁,从而降低锁的粒度,来提高程序的并发性能。
2. 使用细粒度锁和条件变量来实现线程安全的队列
使用细粒度锁来实现队列的高并发性
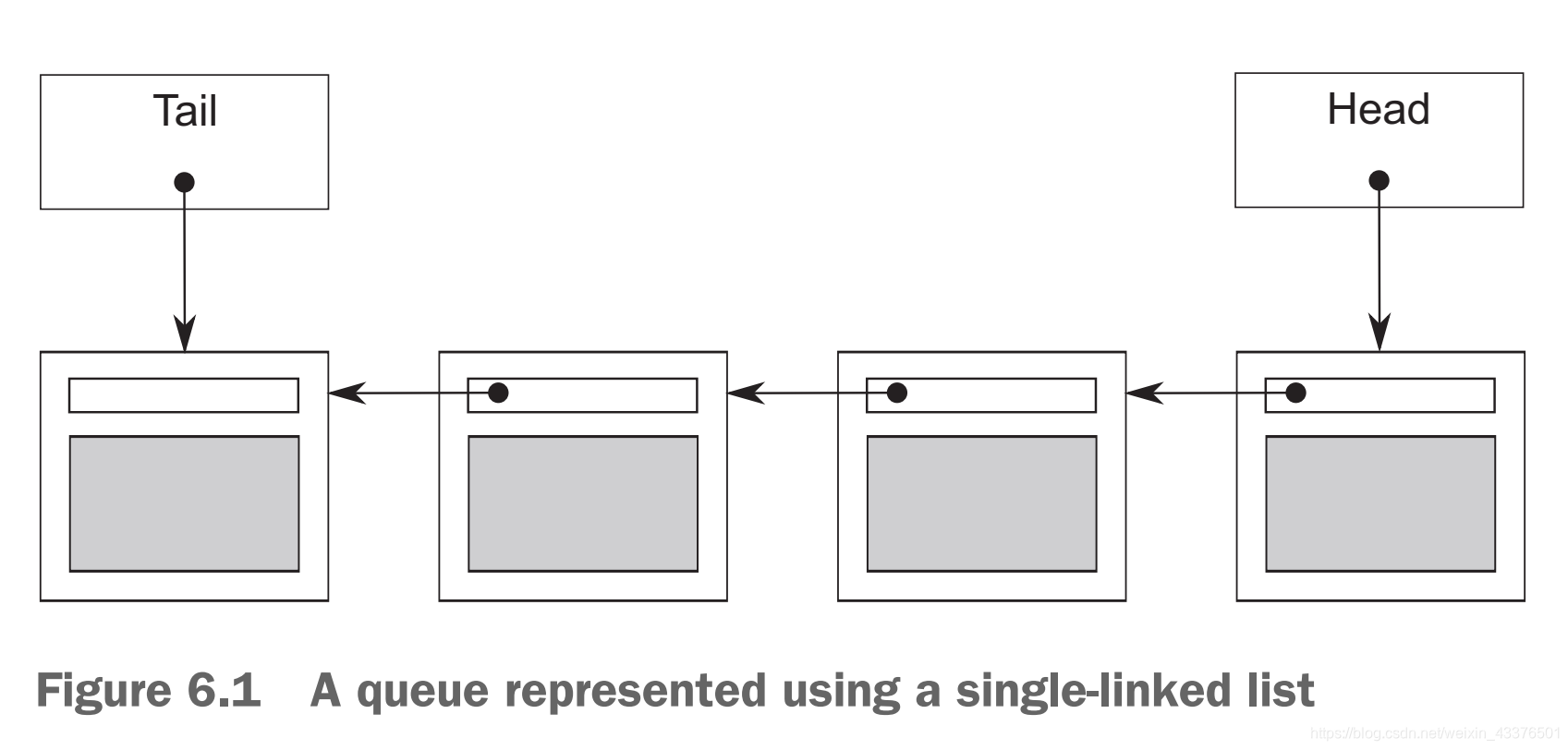
我们可以使用单向链表这种数据结构来实现我们的queue。队列是一种先进先出(FIFO)的数据结构,因此只需要访问队头和队尾,而中间无需考虑。因此,我们的链表结构中需要一个队头以及一个队尾。下面看一下简单的实现:
template<typename T>
class queue
{
private:
struct node
{
T data;
std::unique_ptr<node> next;
node(T data_) : data(std::move(data_)) {}
};
std::unique_ptr<node> head;
node* tail; // 注意,这里用的是内置类型指针
public:
queue() : tail(nullptr) {}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop()
{
if (!head)
return std::shared_ptr<T>();
std::shared_ptr<T> const res(std::make_shared<T>(std::move(head->data)));
std::unique_ptr<node> const old_head = std::move(head);
head = std::move(old_head->next);
if (!head)
tail = nullptr;
return res;
}
void push(T new_value)
{
std::unique_ptr<node> p(new node(std::move(new_value)));
node* const new_tail = p.get();
if (tail) // 队列不为空时进入这里
tail->next = std::move(p);
else // 队列为空时进入这里
head = std::move(p);
tail = new_tail;
}
};
代码中此队列的主要结构就是一个队头(head)和一个队尾(tail)。其中,数据是放在node结构中的。注意,这里队列中的每个节点都是用的std::unique_ptr来连接的(这样就不需要主动去管理内存了),因为中间节点是不参与访问的,只有头节点和尾结点参与访问,所以节点间使用的是std::unique_ptr。此外,由于头节点不需要多个指针来指向它,因此直接用std::unique_ptr就可以了。不过,对于尾结点,由于需要另外的指针需要指向它,所以尾结点有两个指针指向它,因此这里使用内置类型的指针(std::unique_ptr独占所有权,所以访问尾结点只能用内置指针)来访问尾结点(另一个指向尾结点的是next指针,使用的是std::unique_ptr)。
上面的代码在单线程下还行,但是在多线程下就有问题。如果要在多线程中,可能需要两个锁来分别锁住head和tail(如果只用一个锁,那还干嘛自己设计结构,直接在标准库的队列基础上改不就得了。使用两个锁能够细粒度化锁,从而提高并发性能),不过这样就会出现问题,最明显的问题就是push()可以同时修改head和tail,这就需要同时锁定两个锁。这还不是最大的问题,最大问题是push()和pop()能够同时访问next指针:push()更新tail->next,而pop()读取head->next。假如队列中只有一个元素,则有head == tail,此时head->next和tail->next就指向同一个对象了,此时必须要对此对象进行保护。然而,由于在你还未读取tail和head之前是无法得知它俩是否相等的,因此,你必须要在push()和try_pop()中使用同一把锁(意思是最终你还是得使用一把锁来锁住两种操作,你用两把锁就会出现上面分析的问题),这样的话,那自行设计队列的结构就变得无意义了。
(上面基本是照翻书上的内容,大概意思就是说如果是按照上面的方式实现的话,就无法使用两把锁来分别处理tail和head的修改,只能使用一把锁,那这样就无法提高性能了)
那如何才能够使用两把锁(从而实现更高的并发性能)而又不会出现问题呢?
这里书本上介绍了一个特别棒的方式:引入一个虚节点(或者说空节点,即不存储元素,只是占位用)。虚节点的存在,就能确保队列里至少存在一个节点,这样就能区分当前访问的是头结点还是尾结点。当队列为空的时候,就有head == tail,这样try_pop()就无需再访问head->next了。而当插入数据后,head和tail就不再相等,此时head->next和tail->next就不会指向同一个数据了。
引入虚节点的话,node中存储数据时就应该存储指针而不是值本身,因为虚节点本身是没有数据的,使用指针就可以不用给node的构造函数传入一个值从而来构造出一个数据,这里我们当然使用shared_ptr啦:
template<typename T>
class queue
{
private:
struct node
{
std::shared_ptr<T> data; // 使用指针来存储数据
std::unique_ptr<node> next;
};
std::unique_ptr<node> head;
node* tail;
public:
queue() : head(new node), tail(head.get()) {} // 队列的初始化,直接将head创建为虚节点,并将尾结点指向head
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr<T> try_pop()
{
if (head.get() == tail) // 如果相等,则表示队列为空,直接返回
return std::shared_ptr<T>();
std::shared_ptr<T> const res(head->data);
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return res;
}
void push(T new_value)
{
std::shared_ptr<T> new_data(std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node); // 这里也可以用make_unique函数来创建
tail->data = new_data;
node* const new_tail = p.get();
tail->next = std::move(p);
tail = new_tail;
}
};
使用std::shared_ptr来存储数据的额外好处是在try_pop()中无需再构造std::shared_ptr了,可以直接传出std::shared_ptr,这样就不会有异常发生了。
这里讲解一下push()里到底干了啥。由于有虚节点的存在,当存入一个新的值的时候,它是直接将这个新的值存放到虚节点中,然后再创建一个虚节点,链接到刚才的节点之后,成为一个新的虚节点。这样,就存入了一个新值,且根本没有涉及到head节点的操作(你要是说如果head == tail时push中虚节点不就涉及到了head了吗,你要知道,如果相等,则其他线程将不会对head节点执行任何操作,因为是空队列,直接返回。所以push中无需考虑head,天然安全!)。
此外,对于try_pop()中,除了一开始判断一下指针是否相等,后面的操作只是关于head的,跟tail就没有关系了(你要说那old->next不也可能是tail吗。你要知道,这里只是把old->next存储到head中,并没有对old->next做任何修改,old->next是始终有效且不变的。另外,push只可能改变old->next中的data值(当old->next是虚节点时。如果不是虚节点,那push更是接触不到它了),对old->next这个节点本身不会做任何改变,因此,old->next始终是安全的)。所以,此时使用两个锁来分别保护head和tail就非常安全了。
好,下面我们看看加上锁后最终是什么样子的:
template<typename T>
class threadsafe_queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::mutex tail_mutex;
std::unique_ptr<node> head;
node* tail;
private:
node* get_tail()
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail()) // 1 这里需要好好分析
return nullptr;
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
public:
threadsafe_queue() : head(new node), tail(head.get()) {}
threadsafe_queue(const threadsafe_queue& other) = delete;
threadsafe_queue& operator=(const threadsafe_queue& other) = delete;
std::shared_ptr<T> try_pop()
{
std::unique_ptr<node> old_head = pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
void push(T new_value)
{
std::shared_ptr<T> new_data(std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node); // 创建新的虚节点,连接到旧的虚节点后面,成为新的tail
node* const new_tail = p.get();
// 将上面耗时的资源申请操作都放在了锁的区域之外!!
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
tail->next = std::move(p);
tail = new_tail;
}
};
- 首先,我们在
push()中使用了一个tail_lock,这样,当其他push()线程想并发的写时,就会被阻塞。此外,也会阻塞try_pop()中对tail的一次访问(非常简单快速的一次只读访问)。注意到此函数中,锁的上面有三行耗时操作,这种优化非常重要; - 其次,我们看看
try_pop()函数,能看到把锁都放在了数据返回的上面,这样数据在返回时没有在锁的范围内,这样也减少了锁的持有时间,也是一种优化; - 接着,我们看内部的
pop_head()函数,它首先锁住了head_lock,这样,其他想读取数据的线程就会被阻塞; - 来说最重要的地方,我们能看到在
get_tail()内部使用了tail_lock,因为要访问tail,所以这里要加锁。这里很重要的一点是取得tail的地址后,就释放了tail_lock。要知道,一旦释放了tail_lock,push()中就可以继续加元素,从而使得你获取的tail可能与当前真正的tail不一致。因为可能在你的get_tail()函数返回后并与head.get()比较之前,push()已经放入一个新数据了,所以你用来比较的tail已经不是最新的tail了。但是,那又如何!!!要知道,这里和head.get()比较是为了确保tail不会与head.get()相等。此时就算你拿了一个旧的tail,如果判断不相等,则新的tail就更不相等了,且新的tail离head就更远了。因此,这里即使拿取的tial不是最新值,也是天然安全的。这里把锁的范围缩小,更有助于锁的粒度最小化,更加提高了并发性能; - 还要注意一点的是,在
pop_head()中,千万不能把get_tail()放在head_lock锁的外面,必须锁定在head_lock的范围内。反例:
上面代码1和2中间就不在任何锁的控制范围之内。如果线程a通过std::unique_ptr<node> pop_head() { node* const old_tail = get_tail(); // 1 std::lock_guard<std::mutex> head_lock(head_mutex); // 2 if(head.get() == old_tail) return nullptr; std::unique_ptr<node> old_head = std::move(head); head = std::move(old_head->next); return old_head; }get_tail()拿取到了一个tail,然后线程a在执行2之前被系统给挂起了。然后线程b通过push()把当前的tail加入了数据,使其从虚节点变成了真正存储数据的节点,然后现在线程c通过get_tail()拿取到了一个tail,并顺利进入下面的操作,并成功删除了head,然后线程d也跟线程c一样…,直到队列中的所有有效节点都被删除了(当然线程a获取的tail对应的节点也被删除了,因为它被线程b变成了非虚节点)。最后线程a才又被系统给调度起来执行,结果就有可能在线程a获取锁head_lock之前,已经有很多其他线程执行了push或pop操作,并把很多个节点都删除了,甚至删除了线程a所获取的那个tail节点,导致线程a拿到的tail这个地址根本就不在队列里面了。此时,假如队列里面已经没有元素了,按理说现在应该是tail == head,但是由于线程a拿取的tail已经不在队列里了,所以 if 判断肯定不相等,所以线程a将继续执行push操作,导致线程a最后把虚节点也删除了,这就破坏了这个队列的结构。
此外(这里不再是分析反例啦!),我们也可以分析出它是异常安全的。现在在try_pop()里面唯一可能抛出异常的是对互斥体进行上锁,然鹅,由于在成功上锁之前并没有更改队列里面的数据,所以此时即使抛出异常,也不会改变队列中的数据,所以try_pop()是异常安全的。另外,对于push()函数,里面构建的新的std::shared_ptr<T>以及新的std::unique_ptr<node>(都涉及到了堆内存的申请)都有可能会抛出异常。但是,这些执行都是在修改队列中的数据之前完成的,所以即使抛出异常,也不会影响队列中的数据的完整性。其次,类模板std::shared_ptr<>和std::unique_ptr<>都能够在抛出异常时自己处理相关的资源释放,因此也不会出现内存泄漏(所以用标准库设施是多么的好!!!)。因此,push()函数也是异常安全的。
另外,也可以分析出上面的实现也不会出现死锁(即使用了两个锁)。对于try_pop(),因为每次都是先获取head_lock锁,因此不会产生两个锁相互等待的情况。
好了,现在上述的队列可以安全的为多线程服务了,且并发性能比较高。现在我们考虑把wait_and_pop()机制引入进去,这样就可以等待数据,直到有数据时,才能获取队列中的数据。
引入条件变量来实现队列的可等待接口
由于只有push()能够添加数据,所以可以想象,添加数据后只需要使用条件变量执行一下notify_one就能够通知那些获取数据的接口醒来,这个比较简单。比较复杂的是wait_and_pop(),因为获取数据的接口里面会有两个锁,所以等确定好是使用哪个锁来给条件变量使用,以及在哪里等待,我们一步步分析。首先,我们看看最终的队列版本的接口长啥样的:
template<typename T>
class threadsafe_queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
mutable std::mutex head_mutex;
mutable std::mutex tail_mutex;
mutable std::condition_variable data_cond;
std::unique_ptr<node> head;
node* tail;
public:
threadsafe_queue() : head(new node), tail(head.get()) {}
threadsafe_queue(const threadsafe_queue&) = delete;
threadsafe_queue& operator=(const threadsafe_queue&) = delete;
std::shared_ptr<T> try_pop();
bool try_pop(T& value);
std::shared_ptr<T> wait_and_pop();
void wait_and_pop(T& value);
void push(T new_value);
bool empty() const;
};
可以看到,既有try_pop(),又有wait_and_pop(),而且都是有两个重载的版本,因此内部实现部分肯定要用私有函数包装,然后给这几个pop函数调用。
首先来实现最简单的push()接口:
template<typename T>
void threadsafe_queue<T>::push(T new_value)
{
std::shared_ptr<T> new_data(std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
node* const new_tail = p.get();
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
tail->next = std::move(p);
tail = new_tail;
}
data_cond.notify_one();
}
注意,这里面专门用了一对{}来实现tail_lock的提前释放。为啥要提前释放?因为如果不是提前释放,而是等函数返回才自动释放,则有可能另一个线程的wait函数已经接收到此函数的notify_one消息,但是对应的锁还没释放,这会浪费时间。这里提前释放是有一点小小的加速效果的。
此外,其实这里也可以用std::unique_lock来锁住互斥体,然后在执行notify_one()之前主动用unlock()来释放,这样就不需要{}了。但是,建议还是使用std::lock_guard以及{},因为std::lock_guard的性能更高。在非特殊情况下,尽量使用std::lock_guard。
现在考虑实现pop相关的函数。
首先是确定data_cond应该使用哪一个锁来wait(),其实这里两个锁都可以。一般情况下,条件变量的notify_xxx()处使用的什么锁,在对应的wait()处也使用同样的锁。不过,实际使用时也可以不一致,两个地方分别使用两个锁,不过此时就要注意条件竞争的问题。
其次,可以看到有的接口通过直接返回T类型的引用来获取值,这样的话,在接口中必定存在将shared_ptr<T>中的值拷贝或者移动出来给T类型的引用。如果对应的T类型的移动操作不会抛出异常,则比较安全。但是,T类型可能是用户自定义类型,所以其移动或者拷贝可能会抛出异常。此时,如果是先把智能指针从队列里取出来,再从智能指针里拷贝或者移动数据,那么此时如果抛出异常,则队列里的这个数据就不存在了,就会丢失数据。因此,为了异常安全,需要在从队列里取出数据之前就把值赋值给T的引用,然后再将数据从队列里移除。这样,假如在赋值过程中出现异常,则数据仍然在队列里,这下就异常安全了!
因此,我们需要一个单独的私有函数,用于专门等待锁,然后还需要一个私有函数用于删除head。这样的话,用于等待条件变量的锁最好是head_mutex(与notidy_one()处的不是同一个锁):
template<typename T>
class threadsafe_queue
{
private:
node* get_tail()
{
std::lock_guard tail_lock(tail_mutex);
return tail;
}
std::unique_lock<std::mutex> wait_pop()
{
std::unique_lock head_lock(head_mutex);
data_cond.wait(head_lock, [this] {return head.get() != get_tail(); });
return head_lock;
}
std::unique_ptr<node> pop_head()
{
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
public:
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> head_lock(wait_pop());
value = std::move(*head->data);
pop_head();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> head_lock(wait_pop());
auto res = pop_head();
head_lock.unlock();
return res->data;
}
}
注意wait_and_pop()函数里,其将wait_pop()中的head_lock的所有权转移到了外部这个函数中,使得wait_and_pop()在执行后续操作时候,仍然是受head_mutex对应的锁的保护的。
在void wait_and_pop(T& value)函数里,首先是等待锁并获取锁,然后直接将队列中的第一个元素的值移动给T引用,此时如果抛出异常,则队列中的数据仍然健在。最后,通过函数pop_head()来将队列中的数据移除,这就保证了异常安全。对于std::shared_ptr<T> wait_and_pop()函数,由于传出来的是智能指针,所以不会抛出异常,因此可以放心的先移除数据,再传出来。
最后看wait_pop()这个函数,它内部的data_cond等待的是head_mutex,不过tail_mutex在它的谓词里面,所以这里是安全的。其实个人觉得这里等待tail_mutex也可以,但是本书的作者没有这么做:
std::unique_lock<std::mutex> wait_pop()
{
std::unique_lock head_lock(head_mutex);
{
std::unique_lock tail_lock(tail_mutex);
data_cond.wait(tail_mutex, [this] {return head.get() != tail; });
}
return head_lock;
}
如果这么做的话,那么私有函数get_tail()就不需要了。此处,我大概可能猜出作者不这么做的原因是由于get_tail()这个私有函数。因为四个pop函数都会用到tail指针,如果没有get_tail()函数,那么在获取tail指针时都要重新锁住tail_mutex。相反,如果使用get_tail(),那么四个地方都不需要主动锁住tail_mutex了,这样一份代码给四处使用,简化了代码结构和逻辑,所以get_tail()函数是有必要存在的。一旦使用get_tail()函数,那么data_cond的wait就不需要等待tail_mutex了,直接等待head_mutex同样可以。
另外,我们也可以分析一下在wait处等待tail_mutex和等待head_mutex会对最终程序执行有什么细微的影响:
如果wait的是tail_mutex,则head_lock一旦被某个线程得到,其他线程在执行pop相关函数时都会等待获取head_lock。比如线程1首先进入wait_pop(),首先得到head_lock,然后假如队列里面无数据,则其会在wait处等待,并且在等待期间,线程1始终持有head_lock,并没有释放。此时如果线程2也进入wait_pop(),则由于线程1没有释放锁head_lock,所以线程2需要等待head_lock被释放,才能进入里面执行wait等待。此时假如队列里有数据了,则第一个执行的是线程1,因为线程1始终持有head_lock,它会在wait处唤醒并继续执行。等线程1执行完了,释放了head_lock,线程2才能获取到head_lock并执行。
如果用的是作者给出的方法(即wait函数等待的是head_mutex),则假如线程1线进入wait_pop(),当队列为空时,就会发生等待,但是在等待的过程中,线程1会临时释放其wait的锁head_lock(这是条件变量wait函数的特点,更多相关解读可以在我的另一篇文章里查看:C++中条件变量std::condition_variable的唤醒说明)。这样,其他pop线程也就可以获取head_lock锁并发生等待。然后如果队列里突然有数据了,则当前被唤醒并继续执行的不一定是线程1,有可能是其他在wait head_lock的线程。
也就是说,条件变量的wait函数等待tail_mutex时,则第一个等待中的线程(一直持有head_lock的线程)必定先执行,如果wait函数等待的是head_mutex,则后续被唤醒执行的线程是随机的。这两种方案也使得所有线程等待的位置不同,我的方案使得除了第一个线程会在wait处等待外,其他线程都在获取head_lock锁的地方等待。作者的那个方案使得所有线程都在wait处等待。
好了,上面的代码还没有写出try_pop(),其实try_pop()几乎和之前一样,没有什么特别好分析的。下面把完整的代码写出来(与书上的有点区别,比书上的更简洁更好一点):
template<typename T>
class threadsafe_queue
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
mutable std::mutex head_mutex;
mutable std::mutex tail_mutex;
mutable std::condition_variable data_cond;
std::unique_ptr<node> head;
node* tail;
private:
node* get_tail()
{
std::lock_guard tail_lock(tail_mutex);
return tail;
}
std::unique_lock<std::mutex> wait_pop()
{
std::unique_lock head_lock(head_mutex);
data_cond.wait(head_lock, [this] { return head.get() != get_tail(); });
return head_lock;
}
std::unique_ptr<node> pop_head()
{
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
public:
threadsafe_queue() : head(new node), tail(head.get()) {}
threadsafe_queue(const threadsafe_queue&) = delete;
threadsafe_queue& operator=(const threadsafe_queue&) = delete;
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> head_lock(wait_pop());
value = std::move(*head->data);
pop_head();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> head_lock(wait_pop());
auto res = pop_head();
head_lock.unlock();
return res->data;
}
std::shared_ptr<T> try_pop()
{
std::unique_ptr<node> res;
{ // 这里是为了更细粒度化锁采取的措施
std::lock_guard head_lock(head_mutex);
if (head.get() == get_tail())
return nullptr;
res = pop_head();
}
return res->data;
}
bool try_pop(T& value)
{
std::lock_guard head_lock(head_mutex);
if (head.get() == get_tail())
return false;
value = std::move(*head->data);
pop_head();
return true;
}
bool empty() const
{
std::lock_guard head_lock(head_mutex);
return (head.get() == get_tail());
}
void push(T new_value)
{
auto new_data = std::make_shared<T>(std::move(new_value));
auto new_node = std::make_unique<node>();
auto new_tail = new_node.get();
{ // 比直接用unique_lock要好!!
std::lock_guard tail_lock(tail_mutex);
tail->data = std::move(new_data);
tail->next = std::move(new_node);
tail = new_tail;
}
data_cond.notify_one();
}
};
三、总结
设计一个高并发且安全的多线程数据结构是比较困难的,要充分考虑各种可能的问题,特别是要保证异常安全,保证不会发生死锁等情况。在安全的前提下,尽可能的细粒度化锁,从而提高并发性能。文章开头的那些指导意见可以帮助你设计出更安全,更高效的并发数据结构。此外,文章的例子中使用的智能指针、虚节点、以及上锁的位置等细节可以仔细推敲,非常的好,对以后设计相关数据结构肯定有帮助。















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









