







背景
在 A ∗ A^* A∗算法出现之前,人们都在用DFS和BFS进行搜索,然而,这两种算法在展开子节点时都属于盲目型搜索,也就是说,它不会选择在下一次搜索中更优的那个节点,继而借此跳转到该节点进行下一步的搜索,而是盲目全局搜索。如果运气不好,在此情形中,均需要试探完整个解集空间,显然,DFS和BFS只适用于问题规模不大的搜索问题中。 然而,1968年的一篇论文“P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths in graphs. IEEE Trans. Syst. Sci. and Cybernetics, SSC-4(2):100-107, 1968”,打破了这个僵局,从此,一种精巧、高效的算法------A*算法横空出世了,而且还在好多领域取得了不错的应用。
算法介绍
A ∗ A^* A∗算法属于启发式搜索算法,在寻路方面,它可以是在图形平面上,有多条路径,求出最低成本的算法,是非常流行的该类搜索算法中的一个,它一般被用于路径优化领域,例如导航、游戏里面的人物移动等。它的特别之处是在检查最短路径中时,检查每个可能符合需要的节点时都引入了全局的信息,然后对当前节点距终点的距离做出估计,并作为评价该节点处于最短路线上的可能性的量度。
算法搜索过程
核心
两个集合:Open,Closed和一个公式: f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)。其中Open,Closed都是存储节点的集合,Open存储可到达的节点,Closed存储已经到达的节点;而公式 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)则是对节点价值的评估, g ( n ) g(n) g(n)代表从起点走到当前节点的成本,也就是走了多少步, h ( n ) h(n) h(n)代表从当前节点走到目标节点的距离,即不考虑障碍的情况下,离目标还有多远。至于 f ( n ) f(n) f(n),则是对 g ( n ) g(n) g(n)和 h ( n ) h(n) h(n)的综合评估,我们应该尽量选择步数更少,离目标更近的节点,那么 f ( n ) f(n) f(n)的值越小越好。
搜索思路
开始时,Closed表为空,Open表仅包括起始节点,每次迭代中, A ∗ A^* A∗算法将Open表中具有最小代价之的节点去除进行检查,检查后的节点放入Closed表,如果这个节点不是目标节点,那么考虑该节点的所有相邻节点。对于每个相邻节点按下列规则处理;
- 如果相邻节点既不在Open表中,又不在Closed表中,则将它加入Open表中;
- 如果相邻节点已经在Open表中,并且新的路径具有更低的代价值,则更新它的信息;
- 如果相邻节点已经在Closed表中,那么需要检查新的路径是否具有更低的代价值,如果是,那么将它从Closed表中移出,加入到Open表中,否则忽略。(这里需要检查Closed表是因为要防止由于h(n)计算不准确而导致的误差)
重复上述步骤,直到到达目标节点。如果在到达目标之前,Open表就已经变空,则意味着在起始位置和目标位置之间没有可达的路径。
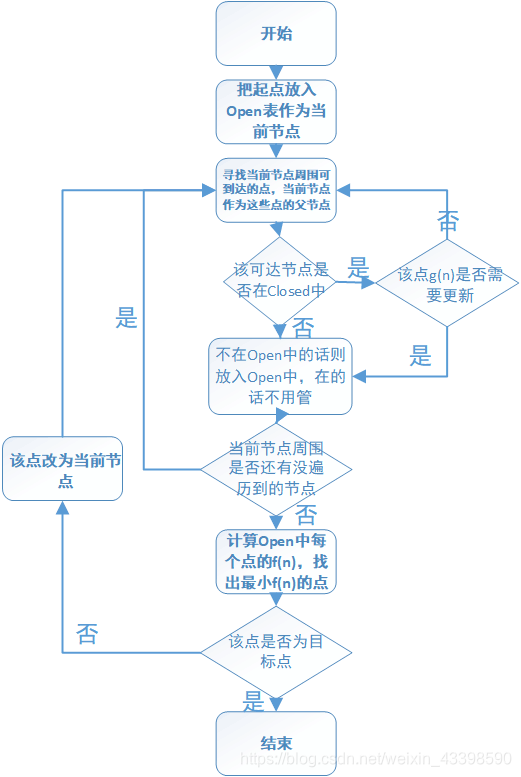
算法流程图
算法正确性证明
前置知识
符号说明:
- g ( n ) g(n) g(n)表示从点 s t st st到达节点 n n n的当前最小代价。
- g ∗ ( n ) g^*(n) g∗(n)表示从节点 s t st st到节点 n n n的实际最小代价。
- h ( n ) h(n) h(n)表示从节点 n n n到目标节点 e n d end end的预估代价。
- h ∗ ( n ) h^*(n) h∗(n)表示从节点 n n n到目标节点 e n d end end的实际最小代价。
- f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n) 。这里 f ( n ) f(n) f(n)的含义为从初始节点 s t st st出发经过节点 n n n再到达目标节点 e n d end end的最小代价的预估。
- f ∗ ( n ) f^*(n) f∗(n)。实际的最短路径长度。
- O P E N L I S T OPEN\ LIST OPEN LIST(开放列表), C L O S E L I S T CLOSE\ LIST CLOSE LIST(封闭列表)。
算法本身性质一: 每次选择的节点是 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)最小的节点。而且, O P E N L I S T OPEN \ LIST OPEN LIST上任一具有 f ( n ) < f ∗ ( s t ) f(n)<f^*(st) f(n)<f∗(st)的节点 n n n,最终都将被 A ∗ A^* A∗选作扩展节点。(下面定理推论2.1)
算法本身性质二: h ( n ) ≤ h ∗ ( n ) h(n)\le h^*(n) h(n)≤h∗(n),预估代价小于实际最小代价。
开始证明
先证明,如果有解,那么算法一定可以找到:
定理1: 对有限图,如果从初始节点 s t st st到目标节点 e n d end end有路径存在,则A*算法一定成功结束。
- 首先证明算法必定结束。由于搜索图为有限图,如果算法能找到解,则会成功结束;如果算法找不到解,那么必然会因为 O P E N L I S T OPEN \ LIST OPEN LIST 为空而结束。因此A算法必然会结束。
- 然后证明算法一定会成功结束。由于至少存在一条由初始点到目标点的路径,设此路径为 P s t = s t ( v 0 ) → v 1 → v 2 ⋯ → e n d ( v m ) P_{st}=st(v_0)\to v_1 \to v_2 \cdots \to end(v_m) Pst=st(v0)→v1→v2⋯→end(vm) 那么算法开始时,节点 v 0 v_0 v0在 O P E N L I S T OPEN \ LIST OPEN LIST 中,而且路径中任一节点 v k v_k vk 离开 O P E N L I S T OPEN \ LIST OPEN LIST 后,其后继节点 v k + 1 v_{k+1} vk+1一定会在这之前进入 O P E N L I S T OPEN \ LIST OPEN LIST 。这样在 O P E N L I S T OPEN \ LIST OPEN LIST 变空之前,目标节点必然会出现在 O P E N L I S T OPEN \ LIST OPEN LIST 中。因此,算法必定会结束。
引理1: 对无限图,若有从初始节点 s t st st到目标节点 e n d end end的路径,则 A ∗ A^* A∗不结束时,在 O P E N L I S T OPEN \ LIST OPEN LIST 中即使最小的一个 f ( v n ) f(v_n) f(vn)值也将增到任意大,或有 f ( v n ) > f ∗ ( s t ) f(v_n)>f^*(st) f(vn)>f∗(st)。
- 设 d ∗ ( v n ) d^*(v_n) d∗(vn) 是 A ∗ A^* A∗生成的从初始节点 v 0 v_0 v0到节点 v n v_n vn的最短路径长度(这里的长度指的是要经过多条边),由于搜索图中每条边的代价都是一个正数,令这些正数中最小一个数是 e e e,则有 g ∗ ( v n ) ≥ d ∗ ( v n ) × e g^*(v_n)\ge d^*(v_n)\times e g∗(vn)≥d∗(vn)×e。( g ∗ ( v n ) g^*(v_n) g∗(vn)是源点到 v n v_n vn的最小代价, d ∗ ( v n ) d^*(v_n) d∗(vn)是源点到 v n v_n vn的最小长度,长度乘以所有边中的最小代价,得到的肯定比从源点到 n n n的最小代价要小)
- 又因为是最佳路径的代价,所以 g ( v n ) ≥ g ∗ ( v n ) ≥ d ∗ ( v n ) × e g(v_n)\ge g^*(v_n)\ge d^*(v_n)\times e g(vn)≥g∗(vn)≥d∗(vn)×e
- 又因为 h ( v n ) ≥ 0 h(v_n)\ge 0 h(vn)≥0,所以 f ( v n ) = g ( v n ) + h ( v n ) ≥ g ∗ ( v n ) ≥ d ∗ ( v n ) × e f(v_n)=g(v_n)+h(v_n)\ge g^*(v_n)\ge d^*(v_n)\times e f(vn)=g(vn)+h(vn)≥g∗(vn)≥d∗(vn)×e
- 所以如果 A ∗ A^* A∗算法不终止,从 O P E N L I S T OPEN \ LIST OPEN LIST 中选出的节点必将拥有任意大的 d ∗ ( v n ) d^*(v_n) d∗(vn)值,因此,也将具有任意大的f值。
引理2: A ∗ A^* A∗结束前的任意时刻, O P E N L I S T OPEN \ LIST OPEN LIST 中总是存在结点 v k v_k vk ,它是从初始结点 s t st st到目标节点 e n d end end 的一个节点,且满足 f ( v k ) < f ∗ ( v k ) f(v_k)<f^*(v_k) f(vk)<f∗(vk) 。
设初始点 s t st st到目标 e n d end end 的最佳路径序列 P s t = s t ( v 0 ) → v 1 → v 2 ⋯ → e n d ( v m ) P_{st}=st(v_0)\to v_1 \to v_2 \cdots \to end(v_m) Pst=st(v0)→v1→v2⋯→end(vm)。
- 算法开始的时候,节点 s t st st在 O P E N L I S T OPEN \ LIST OPEN LIST中,当节点 s t st st离开 O P E N L I S T OPEN \ LIST OPEN LIST 进入 C L O S E L I S T CLOSE\ LIST CLOSE LIST中时,节点 v 1 v_1 v1进入 O P E N L I S T OPEN \ LIST OPEN LIST 。因此, A ∗ A^* A∗没有结束之前,在 O P E N L I S T OPEN \ LIST OPEN LIST 中,必然是最佳路径上的节点。设这些节点排在最前面的节点为 v k v_k vk,则有: f ( v k ) = g ( v k ) + h ( v k ) f(v_k)=g(v_k)+h(v_k) f(vk)=g(vk)+h(vk)
- 由于 v k v_k vk在最佳路径上,故有 g ( v k ) = g ∗ ( v k ) g(v_k)=g^*(v_k) g(vk)=g∗(vk),从而 f ( v k ) = g ∗ ( v k ) + h ( v k ) f(v_k)=g^*(v_k)+h(v_k) f(vk)=g∗(vk)+h(vk)。
- 又由于 A ∗ A^* A∗算法性质二 h ( v k ) ≤ h ∗ ( v k ) h(v_k)\le h^*(v_k) h(vk)≤h∗(vk),故有, f ( v k ) ≤ g ∗ ( v k ) + h ∗ ( v k ) = f ∗ ( v k ) f(v_k)\le g^*(v_k)+h^*(v_k)=f^*(v_k) f(vk)≤g∗(vk)+h∗(vk)=f∗(vk)。
- 因为在最佳路径上的所有节点的 f ∗ f^* f∗值都相同,因此有 f ( v k ) ≤ f ∗ ( v k ) f(v_k)\le f^*(v_k) f(vk)≤f∗(vk)。
定理2: 对无限图,若从初始节点
s
t
st
st到目标节点
e
n
d
end
end有路径存在,则
A
∗
A^*
A∗一定成功结束。
反证法:
- 使用引理1:假设 A ∗ A^* A∗不结束,在 O P E N L I S T OPEN \ LIST OPEN LIST中即使最小的一个 f ( n ) f(n) f(n)值也将增到任意大,或有 f ( n ) > f ∗ ( s ) f(n)>f^*(s) f(n)>f∗(s)
- 根据引理2:在 A ∗ A^* A∗结束前,必存在节点 n n n,使得 f ( n ) < = f ∗ ( s ) f(n)<=f^*(s) f(n)<=f∗(s),所以,如果 A ∗ A^* A∗不结束,将导致矛盾, A ∗ A^* A∗算法只能成功结束。
推论2.1: O P E N L I S T OPEN \ LIST OPEN LIST上任一具有 f ( n ) < f ∗ ( s t ) f(n)<f^*(st) f(n)<f∗(st)的节点 n n n,最终都将被 A ∗ A^* A∗选作扩展节点。
- 由定理2,知 A ∗ A^* A∗一定结束,由 A ∗ A^* A∗的结束条件, O P E N L I S T OPEN \ LIST OPEN LIST中 f ( e n d ) f(end) f(end)最小时才结束。
- 而 f ( e n d ) ≥ f ∗ ( e n d ) = f ∗ ( s t ) f(end)\ge f^*(end)=f^*(st) f(end)≥f∗(end)=f∗(st),所以 f ( n ) < f ∗ ( s t ) f(n)<f^*(st) f(n)<f∗(st) ,均被扩展,得证。
根据定理一和定理二可知,不论是在无向图还是在有向图中,如果有解一定可以被 A ∗ A^* A∗算法找到
再证明,算法找的的解一定是最优解:
引理一: 已知从初始节点 s t st st到目标节点 e n d end end的一条最短路径 P s t P_{st} Pst,路径上任意一点 n n n, g ∗ ( n ) = ∣ P s t ( s t → n ) ∣ g^*(n)= |P_{st}(st\to n)| g∗(n)=∣Pst(st→n)∣。
已知一条 s t st st到 n n n的路径长度为 ∣ P s t ( s t → n ) ∣ |P_{st}(st\to n)| ∣Pst(st→n)∣,根据 g ∗ ( n ) g^*(n) g∗(n)的最小性 g ∗ ( n ) ≤ ∣ P s t ( s t → n ) ∣ g^*(n)\le |P_{st}(st\to n)| g∗(n)≤∣Pst(st→n)∣。
利用反证法证明如下:
假设: g ∗ ( n ) < ∣ P s t ( s t → n ) ∣ g^*(n)< |P_{st}(st\to n)| g∗(n)<∣Pst(st→n)∣。
那么,意味着存在一条路径 P ′ P' P′,该路径从 s t st st到 n n n的长度 ∣ P ′ ( s t → n ) ∣ < ∣ P s t ( s t → n ) ∣ |P'(st\to n)|<|P_{st}(st\to n)| ∣P′(st→n)∣<∣Pst(st→n)∣。
则 ∣ P ′ ( s t → n ) ∣ + ∣ P s t ( n → e n d ) ∣ < ∣ P s t ( s t → e n d ) ∣ |P'(st\to n)| + |P_{st}(n\to end)| < |P_{st}(st\to end)| ∣P′(st→n)∣+∣Pst(n→end)∣<∣Pst(st→end)∣。这与 P s t P_{st} Pst为从 s t st st到 e n d end end的最短路径矛盾。
所以原假设 g ∗ ( n ) < ∣ P s t ( s t → n ) ∣ g^*(n) < |P_{st}(st\to n)| g∗(n)<∣Pst(st→n)∣不成立,因此 g ∗ ( n ) = ∣ P s t ( s t → n ) ∣ g^*(n)=|P_{st}(st\to n)| g∗(n)=∣Pst(st→n)∣得证。
引理二: 已知从初始节点 s t st st到目标节点 e n d end end的一条最短路径 P s t P_{st} Pst,路径上任意一点 n n n, h ∗ ( n ) = ∣ P s t ( n → e n d ) ∣ h^*(n)= |P_{st}(n\to end)| h∗(n)=∣Pst(n→end)∣。(证明思路和引理1相同)
已知一条 n n n到 e n d end end的路径长度为 ∣ P s t ( n → e n d ) ∣ |P_{st}(n\to end)| ∣Pst(n→end)∣,根据 h ∗ ( n ) h^*(n) h∗(n)的最小性 h ∗ ( n ) ≤ ∣ P s t ( n → e n d ) ∣ h^*(n)\le |P_{st}(n\to end)| h∗(n)≤∣Pst(n→end)∣。
利用反证法证明如下:
假设: h ∗ ( n ) < ∣ P s t ( n → e n d ) ∣ h^*(n)< |P_{st}(n\to end)| h∗(n)<∣Pst(n→end)∣。
那么,意味着存在一条路径 P ′ P' P′,该路径从 s t st st到 n n n的长度 ∣ P ′ ( n → e n d ) ∣ < ∣ P s t ( n → e n d ) ∣ |P'(n\to end)|<|P_{st}(n\to end)| ∣P′(n→end)∣<∣Pst(n→end)∣。
则 ∣ P s t ( s t → n ) ∣ + ∣ P ′ ( n → e n d ) ∣ < ∣ P s t ( s t → e n d ) ∣ |P_{st}(st\to n)|+|P'(n\to end)| < |P_{st}(st\to end)| ∣Pst(st→n)∣+∣P′(n→end)∣<∣Pst(st→end)∣。这与 P s t P_{st} Pst为从 s t st st到 e n d end end的最短路径矛盾。
所以原假设 h ∗ ( n ) < ∣ P s t ( n → e n d ) ∣ h^*(n) < |P_{st}(n\to end)| h∗(n)<∣Pst(n→end)∣不成立,因此 h ∗ ( n ) = ∣ P s t ( n → e n d ) ∣ h^*(n)=|P_{st}(n\to end)| h∗(n)=∣Pst(n→end)∣得证。
引理三: 对于任意节点 n n n, g ( n ) = g ∗ ( n ) g(n)=g^*(n) g(n)=g∗(n)时 f ( n ) f(n) f(n)最小。
证明:已知 f ( n ) = g ( n ) + h ( n ) f(n)=g(n)+h(n) f(n)=g(n)+h(n)。对于 h ( n ) h(n) h(n),在寻路前就已经确定,是一个定值。因此, a r g m i n ( f ( n ) ) = a r g m i n ( g ( n ) + h ( n ) ) = a r g m i n ( g ( n ) ) + h ( n ) argmin(f(n))=argmin(g(n)+h(n))=argmin(g(n))+h(n) argmin(f(n))=argmin(g(n)+h(n))=argmin(g(n))+h(n) 。也就是说 f ( n ) f(n) f(n)的值只有在更新 g ( n ) g(n) g(n)时才会变。而 g ( n ) g(n) g(n)最小值是 g ∗ ( n ) g^*(n) g∗(n),所以对节点n而言, g ( n ) = g ∗ ( n ) g(n)=g^*(n) g(n)=g∗(n)时 f ( n ) f(n) f(n)最小。
我们利用反证法进行证明:
假设: A ∗ A^* A∗算法求出的解不是最优,那么我们通过 A ∗ A^* A∗算法寻到了一条从 s t st st到 e n d end end的路径 P A ∗ P_{A^*} PA∗,而这条路径并不是最短路径。
那么则存在最短路径 P s t P_{st} Pst,有 ∣ P s t ∣ < ∣ P A ∗ ∣ |P_{st}|<|P_{A^*}| ∣Pst∣<∣PA∗∣。设最短路径 P s t = s t ( v 0 ) → v 1 → v 2 ⋯ → e n d ( v m ) P_{st}=st(v_0)\to v_1 \to v_2 \cdots \to end(v_m) Pst=st(v0)→v1→v2⋯→end(vm)。
以下利用数学归纳法
归纳奠基:
当到节点 v n , n = 0 v_n,n=0 vn,n=0时: 把节点 s t st st放入 C L O S E L I S T CLOSE\ LIST CLOSE LIST中,把 s t st st相邻节点放入 O P E N L I S T OPEN\ LIST OPEN LIST中并更新 g g g值。这一步后 v 1 v_1 v1显然应该在 O P E N L I S T OPEN\ LIST OPEN LIST中,并且因为节点 v 1 v_1 v1为最短路径 P s t P_{st} Pst上的节点,根据引理一, g ∗ ( v 1 ) = ∣ P s t ( s t → v 1 ) ∣ g^*(v_1)=|P_{st}(st\to v_1)| g∗(v1)=∣Pst(st→v1)∣。这里发现更新 g ( v 1 ) g(v_1) g(v1)时也是根据节点 s t st st到节点 v 1 v_1 v1的边的长度,即 g ( v 1 ) g(v_1) g(v1)更新为 ∣ P s t ( s t → v 1 ) ∣ |P_{st}(st\to v_1)| ∣Pst(st→v1)∣,这时有 g ( v 1 ) = g ∗ ( v 1 ) g(v_1)=g^*(v_1) g(v1)=g∗(v1)。根据引理三,这时的 f ( v 1 ) f(v_1) f(v1)就是最小值了,以后不会再发生变化。
利用算法本身性质一、引理一、引理二,有 f ( v 1 ) = g ( v 1 ) + h ( v 1 ) = g ∗ ( v 1 ) + h ( v 1 ) ≤ g ∗ ( v 1 ) + h ∗ ( v 1 ) = ∣ P s t ∣ < ∣ P A ∗ ∣ f(v_1)=g(v_1)+h(v_1)=g^*(v_1)+h(v_1)\le g^*(v_1)+h^*(v_1)=|P_{st}|<|P_{A^*}| f(v1)=g(v1)+h(v1)=g∗(v1)+h(v1)≤g∗(v1)+h∗(v1)=∣Pst∣<∣PA∗∣。也就是 f ( v 1 ) < f ( e n d ) f(v_1)<f(end) f(v1)<f(end)也成立。由 A ∗ A^* A∗算法的性质一可以知道, v 1 v_1 v1节点一定可以在结束之前被选中,用来更新数据。
当到节点 v n , n = 1 v_n,n=1 vn,n=1时: 若 v 2 v_2 v2不在 O P E N L I S T OPEN \ LIST OPEN LIST或 C L O S E L I S T CLOSE \ LIST CLOSE LIST中,直接更新 g ( v 2 ) g(v_2) g(v2);若在 O P E N L I S T OPEN \ LIST OPEN LIST或 C L O S E L I S T CLOSE \ LIST CLOSE LIST中,接下来由 g ( v 2 ) g(v_2) g(v2)与 g ( v 1 ) + ∣ P s t ( v 1 → v 2 ) ∣ g(v_1)+|P_{st}(v_1\to v_2)| g(v1)+∣Pst(v1→v2)∣的大小关系,判断是否会通过通过 v 1 v_1 v1对 g ( v 2 ) g(v_2) g(v2)进行更新。
- 若更新,则有:
g ( v 2 ) = g ( v 1 ) + ∣ P s t ( v 1 → v 2 ) ∣ = g ∗ ( v 1 ) + ∣ P s t ( v 1 → v 2 ) ∣ = ∣ P s t ( s t → v 1 ) ∣ + ∣ P s t ( v 1 → v 2 ) ∣ = ∣ P s t ( s t → v 2 ) ∣ = g ∗ ( v 2 ) \begin{aligned}g(v_2)&=g(v_1)+ |P_{st}(v_1\to v_2)|\\&=g^*(v_1)+ |P_{st}(v_1\to v_2)|\\&=|P_{st}(st\to v_1)| + |P_{st}(v_1\to v_2)|\\&=|P_{st}(st\to v_2)|\\&=g^*(v_2)\end{aligned} g(v2)=g(v1)+∣Pst(v1→v2)∣=g∗(v1)+∣Pst(v1→v2)∣=∣Pst(st→v1)∣+∣Pst(v1→v2)∣=∣Pst(st→v2)∣=g∗(v2)
根据引理一,此时的 g ( v 2 ) g(v_2) g(v2) 是最小的,所以若 g ( v 2 ) g(v_2) g(v2)更新,则 g ( v 2 ) = g ∗ ( v 2 ) g(v_2)=g^*(v_2) g(v2)=g∗(v2)。
- 若不更新,则说明 g ( v 2 ) ≤ g ( v 1 ) + ∣ P s t ( v 1 → v 2 ) ∣ = g ∗ ( v 2 ) g(v_2)\le g(v_1)+|P_{st}(v_1\to v_2)| = g^*(v_2) g(v2)≤g(v1)+∣Pst(v1→v2)∣=g∗(v2),又因为 g ∗ ( v 2 ) ≤ g ( v 2 ) g^*(v_2)\le g(v_2) g∗(v2)≤g(v2),则 g ( v 2 ) = g ∗ ( v 2 ) g(v_2)=g^*(v_2) g(v2)=g∗(v2)。
这意味着通过 v 1 v_1 v1对节点 v 2 v_2 v2计算 g ( v 2 ) g(v_2) g(v2)后,无论是否更新, g ( v 2 ) g(v_2) g(v2)都会取 g ∗ ( v 2 ) g^*(v_2) g∗(v2)。那么把 v 1 v_1 v1放入 C L O S E L I S T CLOSE\ LIST CLOSE LIST后,无论 v 2 v_2 v2在 C L O S E L I S T CLOSE\ LIST CLOSE LIST或 O P E N L I S T OPEN \ LIST OPEN LIST中,还是不在,最终的 g ( v 2 ) g(v_2) g(v2) 都等于 g ∗ ( v 2 ) g^*(v_2) g∗(v2)。根据引理三,这时的 f ( v 2 ) f(v_2) f(v2)就是最小值了,以后不会再发生变化。
归纳假设:对于节点 v n , n = k v_n,n=k vn,n=k时,满足 g ( v k ) = g ∗ ( v k ) g(v_{k})=g^*(v_{k}) g(vk)=g∗(vk),且以后不会发生变化。
归纳递推:对于节点 v n , n = k + 1 , k ≤ m − 1 v_n,n=k+1,k\le m-1 vn,n=k+1,k≤m−1时:
利用算法本身性质一、引理一、引理二,有 f ( v k ) = g ( v k ) + h ( v k ) = g ∗ ( v k ) + h ( v k ) ≤ g ∗ ( v k ) + h ∗ ( v k ) = ∣ P s t ∣ < ∣ P A ∗ ∣ f(v_k)=g(v_k)+h(v_k)=g^*(v_k)+h(v_k)\le g^*(v_k)+h^*(v_k)=|P_{st}|<|P_{A^*}| f(vk)=g(vk)+h(vk)=g∗(vk)+h(vk)≤g∗(vk)+h∗(vk)=∣Pst∣<∣PA∗∣。也就是 f ( v k ) < f ( e n d ) f(v_k)<f(end) f(vk)<f(end)也成立。由 A ∗ A^* A∗算法的性质一可以知道, v k v_k vk 节点一定可以在结束之前被选中,用来更新数据。
若 v k + 1 v_{k+1} vk+1不在 O P E N L I S T OPEN \ LIST OPEN LIST或 C L O S E L I S T CLOSE \ LIST CLOSE LIST中,直接更新 g ( v k + 1 ) g(v_{k+1}) g(vk+1);若在 O P E N L I S T OPEN \ LIST OPEN LIST或 C L O S E L I S T CLOSE \ LIST CLOSE LIST中,接下来由 g ( v k + 1 ) g(v_{k+1}) g(vk+1)与 g ( v k ) + ∣ P s t ( v k → v k + 1 ) ∣ g(v_{k})+|P_{st}(v_k\to v_{k+1})| g(vk)+∣Pst(vk→vk+1)∣的大小关系,判断是否会通过通过 v k v_k vk对 g ( v k + 1 ) g(v_{k+1}) g(vk+1)进行更新。
- 若更新,则有:
g ( v k + 1 ) = g ( v k ) + ∣ P s t ( v k → v k + 1 ) ∣ = g ∗ ( v k ) + ∣ P s t ( v k → v k + 1 ) ∣ = ∣ P s t ( s t → v k ) ∣ + ∣ P s t ( v k → v k + 1 ) ∣ = ∣ P s t ( s t → v k + 1 ) ∣ = g ∗ ( v k + 1 ) \begin{aligned}g(v_{k+1})&=g(v_k)+ |P_{st}(v_k\to v_{k+1})|\\&=g^*(v_k)+ |P_{st}(v_k\to v_{k+1})|\\&=|P_{st}(st\to v_k)| + |P_{st}(v_k\to v_{k+1})|\\&=|P_{st}(st\to v_{k+1})|\\&=g^*(v_{k+1})\end{aligned} g(vk+1)=g(vk)+∣Pst(vk→vk+1)∣=g∗(vk)+∣Pst(vk→vk+1)∣=∣Pst(st→vk)∣+∣Pst(vk→vk+1)∣=∣Pst(st→vk+1)∣=g∗(vk+1)
根据引理一,此时的 g ( v k + 1 ) g(v_{k+1} ) g(vk+1) 是最小的,所以若 g ( v k + 1 ) g(v_{k+1}) g(vk+1)更新,则 g ( v k + 1 ) = g ∗ ( v K + 1 ) g(v_{k+1})=g^*(v_{K+1}) g(vk+1)=g∗(vK+1)。
- 若不更新,则说明 g ( v k + 1 ) ≤ g ( v k ) + ∣ P s t ( v k → v k + 1 ) ∣ = g ∗ ( v k + 1 ) g(v_{k+1})\le g(v_k)+|P_{st}(v_k\to v_{k+1})| = g^*(v_{k+1}) g(vk+1)≤g(vk)+∣Pst(vk→vk+1)∣=g∗(vk+1),又因为 g ∗ ( v k + 1 ) ≤ g ( v k + 1 ) g^*(v_{k+1})\le g(v_{k+1}) g∗(vk+1)≤g(vk+1),则 g ( v k + 1 ) = g ∗ ( v k + 1 ) g(v_{k+1})=g^*(v_{k+1}) g(vk+1)=g∗(vk+1) 。
这意味着通过 v k v_k vk 对节点 v k + 1 v_{k+1} vk+1计算 g ( v k + 1 ) g(v_{k+1}) g(vk+1)后,无论是否更新, g ( v k + 1 ) g(v_{k+1}) g(vk+1)都会取 g ∗ ( v k + 1 ) g^*(v_{k+1}) g∗(vk+1)。那么把 v k v_k vk 放入 C L O S E L I S T CLOSE\ LIST CLOSE LIST后,无论 v k + 1 v_{k+1} vk+1在 C L O S E L I S T CLOSE\ LIST CLOSE LIST或 O P E N L I S T OPEN \ LIST OPEN LIST中,还是不在,最终的 g ( v k + 1 ) g(v_{k+1}) g(vk+1) 都等于 g ∗ ( v k + 1 ) g^*(v_{k+1}) g∗(vk+1)。根据引理三,这时的 f ( v k + 1 ) f(v_{k+1}) f(vk+1)就是最小值了,以后不会再发生变化。
综上所述: ∀ k ∈ Z , 0 ≤ k ≤ m , 满 足 g ( k ) = g ∗ ( k ) \forall k \in Z, 0\le k \le m, 满足g(k)=g^*(k) ∀k∈Z,0≤k≤m,满足g(k)=g∗(k),且以后不会发生变化。
因此,最后从 O P E N L I S T OPEN\ LIST OPEN LIST 中取出 e n d ( v m ) end(v_m) end(vm)节点的时候, ∣ P A ∗ ∣ = f ( v m ) = g ( v m ) + h ( v m ) = g ∗ ( v m ) + h ( v m ) = g ∗ ( v m ) = ∣ P s t ∣ |P_{A^*}|=f(v_m)=g(v_m)+h(v_m)=g^*(v_m)+h(v_m)=g^*(v_m)=|P_{st}| ∣PA∗∣=f(vm)=g(vm)+h(vm)=g∗(vm)+h(vm)=g∗(vm)=∣Pst∣。这是一条根据 A ∗ A^* A∗算法找到的路径 P A ∗ P_{A^*} PA∗。这显然与我们最初的假设“通过 A ∗ A^* A∗算法找到的路径不是最小值,也就是 ∣ P s t ∣ < ∣ P A ∗ ∣ |P_{st}|<|P_{A^*}| ∣Pst∣<∣PA∗∣”矛盾。所以假设不成立,通过 A ∗ A^* A∗算法找到的就是最短路径。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









