







新一代backbone
源码https://github.com/microsoft/Swin-Transformer
ICCV 2021最佳论文
解决问题:
图像中像素太多,需要更多特征就需要很长的序列
血猎榷场注意力越慢
本质:
用窗口和分层的形式代替长序列
使用分层来代替CNN的感受野
摘要
提出一个Swin Transformer, 可以用作骨干网络,直接把transformer用在CV领域,有挑战:1.多尺度物体2.序列长度太长。基于挑战,提出了hierarchical transformer,使用一种一种窗口的方法,现在自注意力在窗口内算,seq很短,而且通过移动窗口,上下层之间会产生交互(cross-window connection),这个层级窗口可以提供各个尺度的信息,而且他的复杂度是随着分辨率提高线性增长(不是平方)
Intro
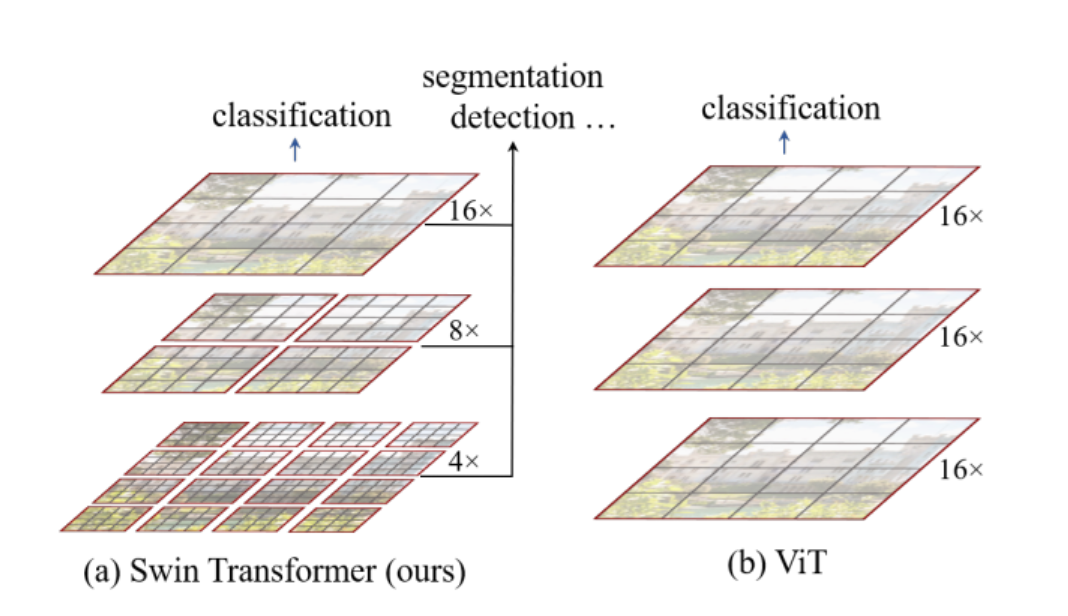
Vit把图片打成16*16的patch,也就是说每一层token看到的都是这个分辨率,对多尺寸的物体效果就不好,也就是low-resolution、单一尺度
FPN每一层的感受野不一样,可以处理不同尺寸的问题,检测
UNet提出Skip connection,下采样之后不光从bottom里拿特征,还从下采样的结果拿 分割
方法
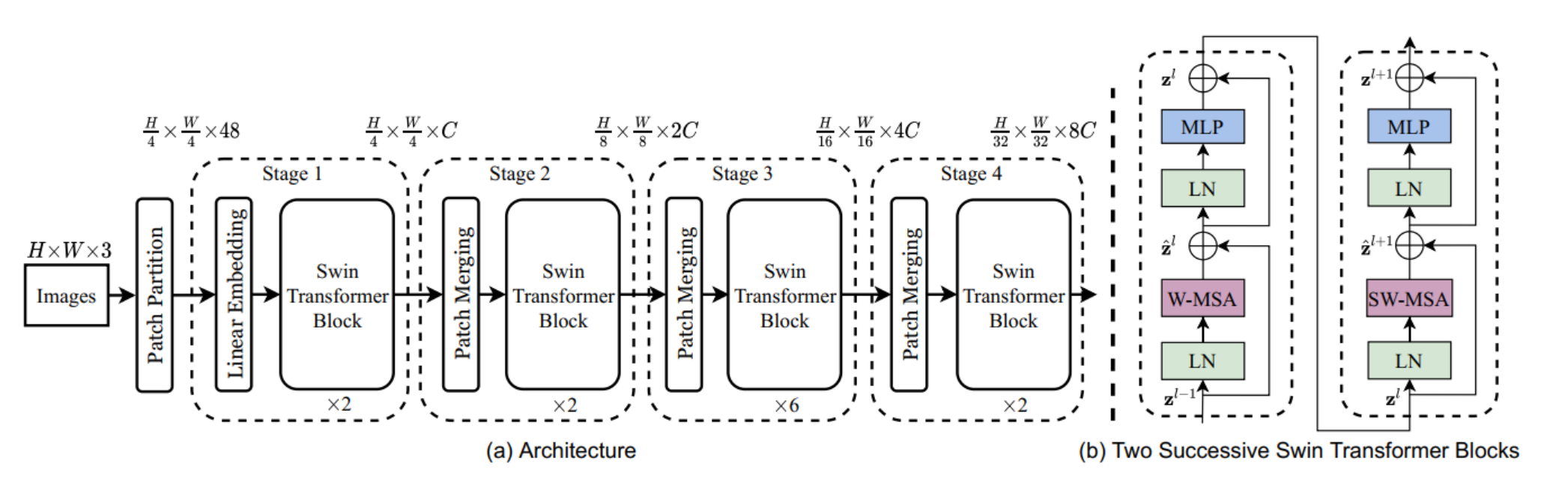
patch partition
patchsize是4X4,48=4X4X3
linear embeding
对每个像素的channel做线性变换(前两步加起来和ViT中liear projection一样)(源码中直接卷积实现)
对于Swin-T版本,超参数C=96 > 56X56X96=3136X56 (token个数 X token向量维度)
swin transfomer
后面谈,维度不变
patch Merging
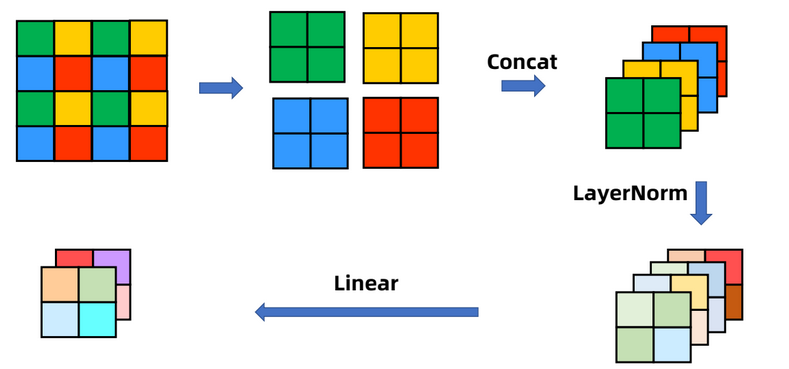
主要是降维(下采样、类似池化)(类似pixel shuffle的反过程)。把每个小窗口中相同位置的值取出来,拼成新的patch,再把所有patch在cannel维度上concat起来。(此时通道数应该变成4C),然后为了和resNet等网络保持一致,再在cannel维度上做一个1X1的卷积,把维度降一半,变成2C
在Swin Transformer中,每个stage的降低分辨率的过程都是通过Patch Merging实现的。
重复进行三次
这个过程完全类似CNN,特征图降到7X7X768
分类头
如果做分类任务,在7X7X768的基础上添加一个“分类头”,做一个平均池化,变成1X768,再变成1X1000(如果在imageNet上做分类)
基于移动窗口的自注意力
窗口
问题:对于密集预测任务和大分辨率的图片,全局的自注意力有平方倍的复杂度
和标准的复杂度对比
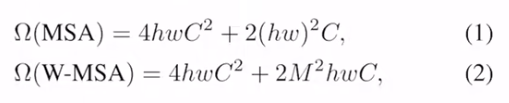
这楼里每个窗口有49个patch
移动窗口
问题:只基于窗口丢失了全局信息
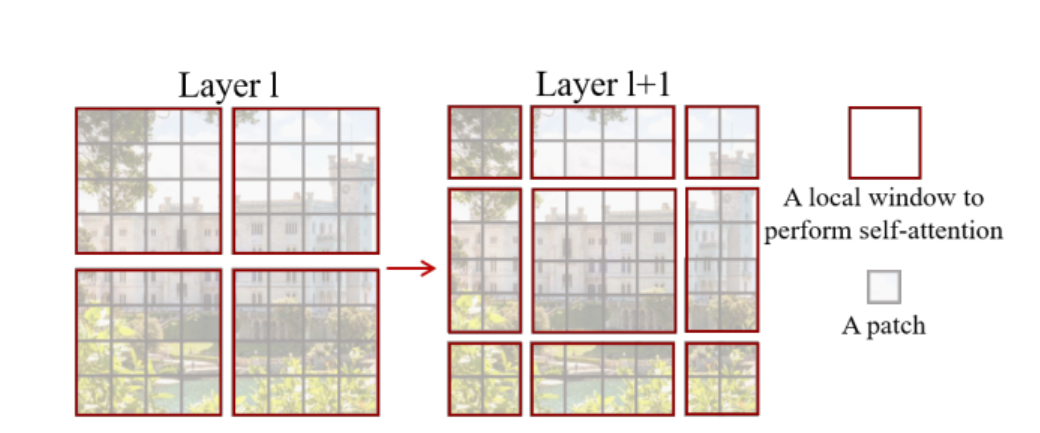
往右下移动窗口3个patch,带来的问题:窗口数增多了,而且窗口大小不一样
一种简单解决,在周围的窗口直接padding-0但是复杂度太高了
解决:一种掩码方式,做一次循环移位
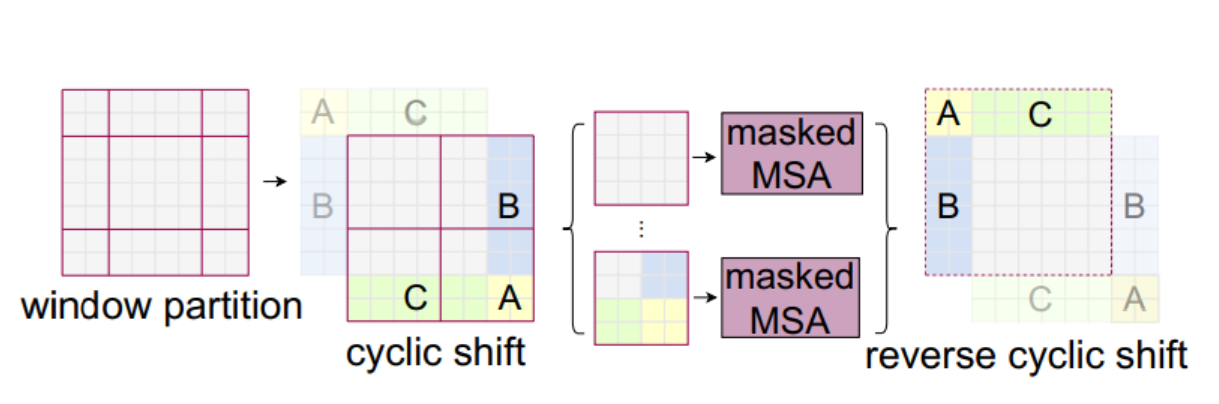
如此得到的窗口数量还是四个,对于左上角的窗口,做自注意力没问题
位置信息
放在了attention矩阵当中,可以学习,使用相对位置信息
对比
分为T、S、B、L四种,其中SwinT和Res50参数相当、SwinS和Res101相当,具体区别如下

ref:
source code:https://github.com/SwinTransformer/Swin-Transformer-Object-Detection
使用:https://www.cnblogs.com/isLinXu/p/15880039.html
测试命令:
python demo/image_demo.py demo/demo.jpg configs/swin/mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_1x_coco.py mask_rcnn_swin_tiny_patch4_window7_1x.pth
知乎:https://zhuanlan.zhihu.com/p/468495919
知乎:https://zhuanlan.zhihu.com/p/443418635


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









