







一、前言
学习G1垃圾收集器之前需要对JVM有大概了结:JVM基础知识。
二、G1简介
G1是一个并行回收器,它把整个堆划分为2048个区域,这些区域物理上不连续,被称为reigon,每一个region的大小是1 - 32M不等,必须是2的整数次幂。使用不同的region可以来表示Eden区、survivor区、old区等
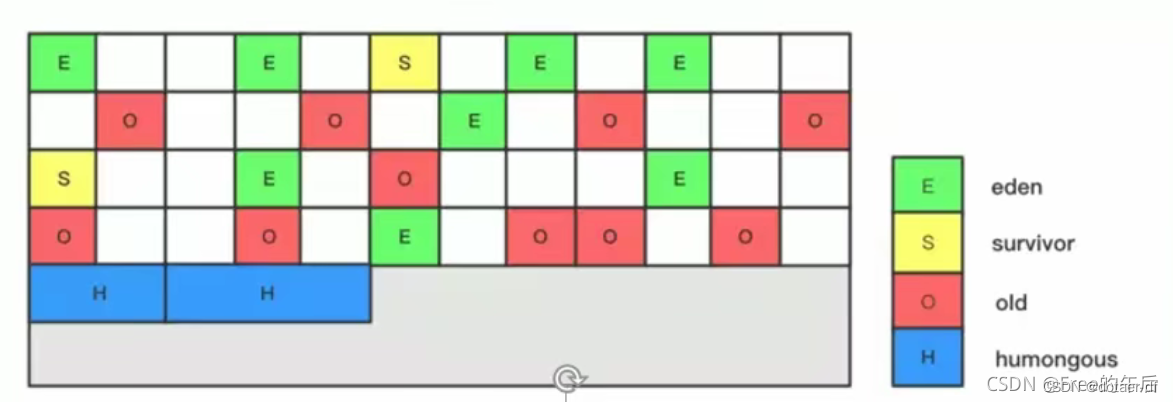
虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分region (不需要连续)的集合,通过region的动态分配方式实现逻辑上的连续。
G1垃圾收集器还增加了一种新的内存区域,叫做Humongous内存区域,如图中的H块。主要用于存储大对象,如果超过1.5个region, 就放到H。
设置H区的原因:
对于堆中的大对象,默认直接会被分配到老年代,但是如果它是一个短期存在的大对象,
就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,
它用来专门存放大对象。如果一个H区装不下一个大对象,那么G1会寻找连续的H区来
存储。为了能找到连续的H区,有时候不得不启动Full GC。 G1的大多数行为都把H区
作为老年代的一部分来看待。
不像传统分代垃圾收集器,G1中没有From Survivor 与 To Survivor的概念, 因为G1不管是Young GC、Mix GC、Full GC 对象都是从一个reigon转移到另外一个reigon或是直接清除,也就是说reigon之间采用的复制的算法。但是整体上来看实际属于标记-压缩算法。通过复制算法处理之后的内存会被整齐的摆放在一起(即region经过垃圾回收之后会被规整)。此外,这些reigion的角色会转变,即原来存放eden区域被清空后,可以用来存放survivor、old或者是humongous
三、G1的优劣
G1的优势
- 可预测的停顿时间模型
相比于CMS的STW时间未知,G1能让使用者通过一个参数来明确指定STW的时间必须在指定时间内,通过参数-XX:MaxGCPauseMillis进行设置 - 分区
由于分区的原因,G1可以只选取部分区域进行内存回收,这样缩小了回收的范围,因此对于全局停顿情况的发生也能得到较好的控制。此外G1 跟踪各个 reigion 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的reigion。保证了G1收集器在有限的时间内可以获取尽可能高的收集效率。
G1的劣势
- G1无论是为了垃圾收集产生的内存占用(Footprint)还是程序运行时的额外执行负载(Overload)都要比CMS要高。
- 从经验上来说,在小内存应用上CMS的表现大概率会优于G1,而G1在大内存应用上则发挥其优势
四、G1和CMS区别
1、堆(Heap)空间分配不同
-
CMS 将堆逻辑上分成Eden,Survivor(S0,S1),Old,并且他们是固定大小JVM启动的时候就已经设定不能改变,并且是连续的内存块
-
G1 将堆分成多个大小相同的Region(区域),默认2048个,在1Mb到32Mb之间大小,逻辑上分成Eden,Survivor,Old,巨型,空闲,他们不是固定大小,会根据每次GC的信息做出调整
2、对于漏标处理不同(三色标级好文)
-
CMS 在三色标记算法阶段采用增量更新处理漏标
-
G1 在三色标记算法阶段采用原始快照处理漏标
3、压缩策略不同
- CMS中不启用压缩会产生很多内存碎片,当产生很多内存碎片的时候,找不到空间来分配剩余的对象
- G1中每次回收过程中,将多个Region拷贝到空闲Region的时候都会进行压缩
4、YoungGC不同
- CMS是针对老年代进行回收的,如果要回收年轻代还需配合其他垃圾回收器
- G1的Young GC是自己去清理的,而不是其他GC处理
五、Remembered Set
理解RSet首先需要知晓如下几点:
一个对象会被不同region的其他对象引用,这些region可能属于不同的代,判断对象是否存活的时候,不能只考虑属于一个代中的region内对象,其他分代垃圾收集器也存在该问题,G1由于分区算法的原因,这个问题更为突出。比如回收新生代的时候也不得不扫描老年代?比如可达性分析算法的GC Roots集合可能在不同的代中,所以从所有GC Roots出发扫描关联引用的对象的时候是会涉及所有代的,如果为了回收某个代中的垃圾对象而扫描整个堆,这样必然会降低垃圾回收的效率,所以堆内会有一部分的内存用来储存对象引用关系,也就是堆内存并不能完全用来存放对象数据
对于Remember Set,可以将其理解为一个抽象的数据结构,它主要为了解决跨代引用对GC的影响。
Hot Spot实际使用的是一个叫做CardTable的结构。对于G1来说,每个Region都有一个CardTable,每个CardTable都有若干大小为512字节的card用于存储其它Region的对象地址。当Region A的一个对象A在引用Region B的一个对象B的时候,会通过写屏障将A对象的地址映射到Region B的CardTable中,标识对应card为dirty,之后在对Region B进行根节点枚举的时候,会把Region B的CardTable中被标记为dirty的card纳入到根节点的范围中进行扫描,以此避免去扫描Region A。
如果对应到分代的情况,那就是在新生代中记录了老年代的一块块地址,在Minor GC的时候,直接从CardTable中获取到需要扫描的老年代对象,而不用去扫描整个老年代
垃圾收集之Remember Set(CardTable)_黄智霖-blog的博客-CSDN博客_remember set 原理















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









