







现在需要监听netcat方式输入的文本内容
要求:将含有kb07 和 kb09的字符的内容放在hdfs上的各自命名的文件夹下
文字内容:
aaaaaaakb09bbbbbbbbbbbbbbbbbbb
bbbbbbbbbkb07cccccccccccccccc
ccccccccckb09cddddddddddddddddd
aaaaaaakb09ddddddddddddddd
bbbbbbbbbkb07rrrrrrrrrrrrrrrrrrr
ccccccccckb092222222222222222
aaaaaaakb0944444444444444444
bbbbbbbbbkb07666666666666666666
ccccccccckb09sssssssssssssssss
aaaaaaakb09wwwwwwwwwwwwww
bbbbbbbbbkb07sssssssssssssss
ccccccccckb09mmmmmmmmmmmmm
最终效果如图:

maven 依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
Java代码实现功能
package cn.bright;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @Author Bright
* @Date 2020/12/1
* @Description
*/
public class InterceptorDemo2 implements Interceptor {
private List<Event> addHeaderEvents;
@Override
public void initialize() {
ArrayList addHeaderEvents = new ArrayList();
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
Map<String, String> headers = event.getHeaders();
String bodystr = new String(body);
if(bodystr.indexOf("kb07")!=-1){
headers.put("type","kb07");
}else {
headers.put("type","kb09");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
addHeaderEvents.clear();
for (Event event:events){
addHeaderEvents.add(intercept(event));
}
return addHeaderEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new InterceptorDemo2();
}
@Override
public void configure(Context context) {
}
}
}
flume脚本
vi banji-flume-interceptor-hdfs.conf
train.sources=trainSource
train.channels=trainChannel
train.sinks=trainSink
train.sources.trainSource.type=spooldir
train.sources.trainSource.spoolDir=/opt/flume160/conf/jobkb09/dataSourceFile/train
train.sources.trainSource.includePattern=train_[0-9]{4}-[0-9]{2}-[0-9]{2}.csv
train.sources.trainSource.deserialize=LINE
train.sources.trainSource.deserialize=maxLineLength=10000
train.sources.trainSource.interceptors=head_filter
train.sources.trainSource.interceptors.head_filter.type=regex_filter
train.sources.trainSource.interceptors.head_filter.regex=^user*
train.sources.trainSource.interceptors.head_filter.excludeEvents=true
train.channels.trainChannel.type=file
train.channels.trainChannel.checkpointDir=/opt/flume160/conf/jobkb09/checkPointFile/train
train.channels.trainChannel.dataDirs=/opt/flume160/conf/jobkb09/dataChannelFile/train
train.sinks.trainSink.type=hdfs
train.sinks.trainSink.hdfs.fileType=DataStream
train.sinks.trainSink.hdfs.filePrefix=train
train.sinks.trainSink.hdfs.fileSuffix=.csv
train.sinks.trainSink.hdfs.path=hdfs://192.168.116.60:9000/kb09file/user/train/%Y-%m-%d
train.sinks.trainSink.hdfs.useLocalTimeStamp=true
train.sinks.trainSink.hdfs.batchSize=640
train.sinks.trainSink.hdfs.rollCount=0
train.sinks.trainSink.hdfs.rollSize=120000000
train.sinks.trainSink.hdfs.rollInterval=20
train.sources.trainSource.channels=trainChannel
train.sinks.trainSink.channel=trainChannel
[root@hadoop001 jobkb09]# cat banji-flume-interceptor-hdfs.conf
banjidemo.sources=banjiSource
banjidemo.channels=banjiChannel1 banjiChannel2
banjidemo.sinks=banjiSink1 banjiSink2
banjidemo.sources.banjiSource.type=netcat
banjidemo.sources.banjiSource.bind=localhost
banjidemo.sources.banjiSource.port=7777
banjidemo.sources.banjiSource.interceptors=banji1
banjidemo.sources.banjiSource.interceptors.banji1.type=cn.bright.InterceptorDemo2$Builder
banjidemo.sources.banjiSource.selector.type=multiplexing
banjidemo.sources.banjiSource.selector.header=type
banjidemo.sources.banjiSource.selector.mapping.kb07=banjiChannel1
banjidemo.sources.banjiSource.selector.mapping.kb09=banjiChannel2
banjidemo.channels.banjiChannel1.type=memory
banjidemo.channels.banjiChannel1.capacity=1000
banjidemo.channels.banjiChannel1.transactionCapacity=1000
banjidemo.channels.banjiChannel2.type=memory
banjidemo.channels.banjiChannel2.capacity=1000
banjidemo.channels.banjiChannel2.transactionCapacity=1000
banjidemo.sinks.banjiSink1.type=hdfs
banjidemo.sinks.banjiSink1.hdfs.fileType=DataStream
banjidemo.sinks.banjiSink1.hdfs.filePrefix=kb07
banjidemo.sinks.banjiSink1.hdfs.fileSuffix=.csv
banjidemo.sinks.banjiSink1.hdfs.path=hdfs://192.168.116.60:9000/kb09file/user/kb07/%Y-%m-%d
banjidemo.sinks.banjiSink1.hdfs.useLocalTimeStamp=true
banjidemo.sinks.banjiSink1.hdfs.batchSize=640
banjidemo.sinks.banjiSink1.hdfs.rollCount=0
banjidemo.sinks.banjiSink1.hdfs.rollSize=1000
banjidemo.sinks.banjiSink1.hdfs.rollInterval=3
banjidemo.sinks.banjiSink2.type=hdfs
banjidemo.sinks.banjiSink2.hdfs.fileType=DataStream
banjidemo.sinks.banjiSink2.hdfs.filePrefix=kb09
banjidemo.sinks.banjiSink2.hdfs.fileSuffix=.csv
banjidemo.sinks.banjiSink2.hdfs.path=hdfs://192.168.116.60:9000/kb09file/user/kb09/%Y-%m-%d
banjidemo.sinks.banjiSink2.hdfs.useLocalTimeStamp=true
banjidemo.sinks.banjiSink2.hdfs.batchSize=640
banjidemo.sinks.banjiSink2.hdfs.rollCount=0
banjidemo.sinks.banjiSink2.hdfs.rollSize=1000
banjidemo.sinks.banjiSink2.hdfs.rollInterval=3
banjidemo.sources.banjiSource.channels=banjiChannel1 banjiChannel2
banjidemo.sinks.banjiSink1.channel=banjiChannel1
banjidemo.sinks.banjiSink2.channel=banjiChannel2
flume路径下执行命令
./bin/flume-ng agent --name banjidemo --conf ./conf/ --conf-file ./conf/jobkb09/banji-flume-interceptor-hdfs.conf -Dflume.root.logger=INFO,console
监控界面
再开一个界面进行连接
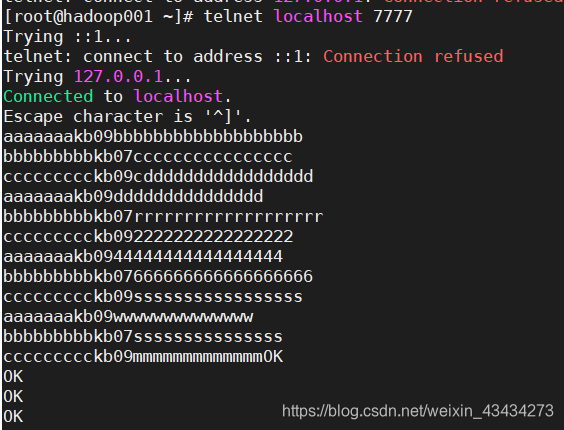
telnet localhost 7777
输入文本内容:
aaaaaaakb09bbbbbbbbbbbbbbbbbbb
bbbbbbbbbkb07cccccccccccccccc
ccccccccckb09cddddddddddddddddd
aaaaaaakb09ddddddddddddddd
bbbbbbbbbkb07rrrrrrrrrrrrrrrrrrr
ccccccccckb092222222222222222
aaaaaaakb0944444444444444444
bbbbbbbbbkb07666666666666666666
ccccccccckb09sssssssssssssssss
aaaaaaakb09wwwwwwwwwwwwww
bbbbbbbbbkb07sssssssssssssss
ccccccccckb09mmmmmmmmmmmmm
hdfs 查看数据收集情况
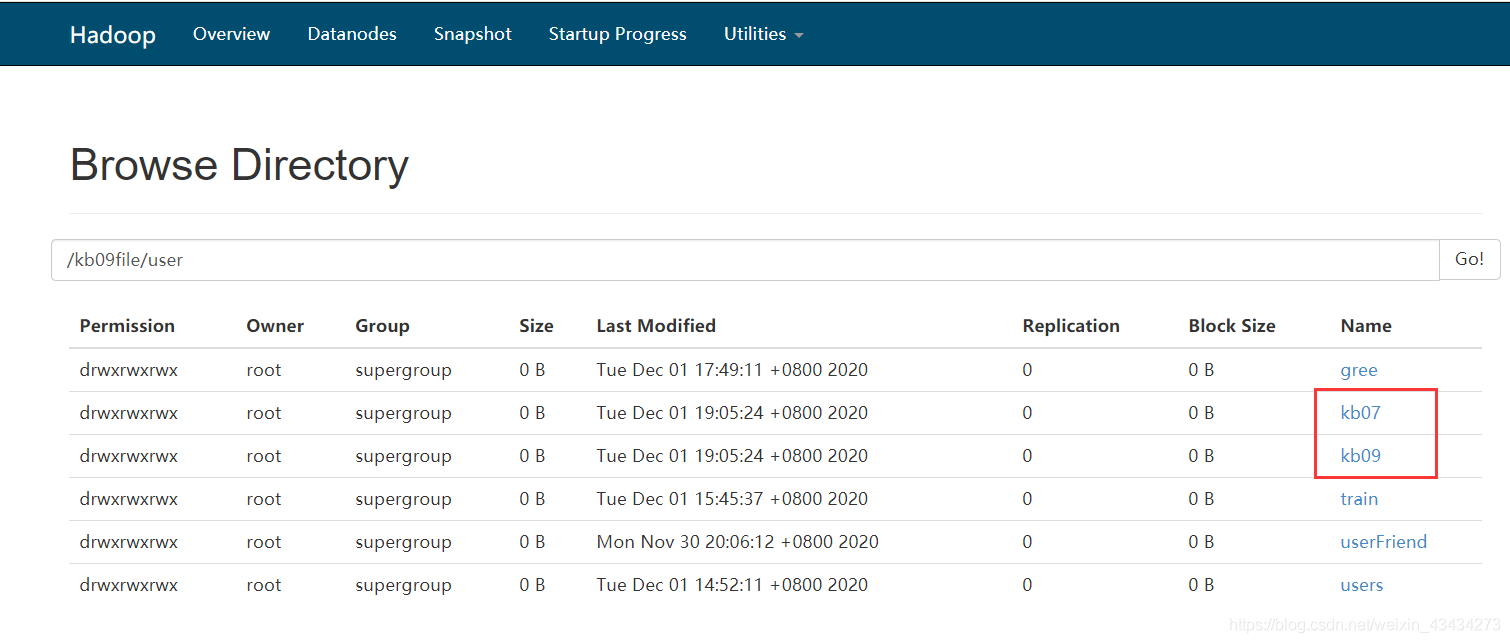


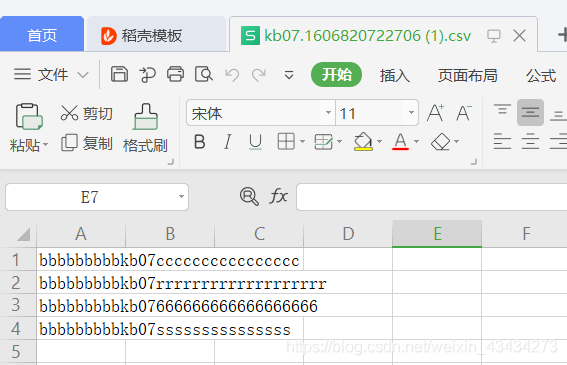
文件下载查看:如图即为成功














 4680
4680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









